
笔记整理:陆星宇,东南大学硕士,研究方向为自然语言处理
链接:https://arxiv.org/abs/2208.14565
动机
命名实体识别(NER)是识别与命名实体相关的文本片段并将其分类到预定义的实体类型(如人物、位置等)的任务。作为信息提取系统中的基本组件,NER已被证明对各种下游任务如关系抽取、指代消解和细粒度观点挖掘有益。
以往的工作主要将NER作为序列标记或跨度分类来处理,存在许多局限性,例如难以用序列标注处理嵌套NER,基于跨度分类的学习和推理十分复杂,对监督数据中的噪声十分敏感。此外,现有的工作将所有非实体标记的跨度统一作为反例,当训练数据的标记不完整时,可能会引入假反例。
贡献
文章的主要贡献如下:
(1) 将NER视为一种表示学习问题,提出了一种用于命名实体识别的高效双编码器,并在通用和医疗领域的多个数据集上取得了SOTA结果。
(2) 引入了一种新的动态阈值损失,其学习针对候选实体的动态阈值以区分实体跨度和非实体跨度;
方法
1、模型结构
模型的总体架构如图1所示,实体类型编码器和文本编码器是同构且完全解耦的Transformer模型。在向量空间中,锚点(橙色标识)表示来自实体类型编码器的特殊标记[CLS]。通过对比学习,其最大化锚点与正标记(Jim)之间的相似性,并最小化锚点与负标记之间的相似性。虚线灰色圆圈(由锚点与文本编码器中的[CLS]之间的相似性限定)表示将实体标记与非实体标记分开的阈值。
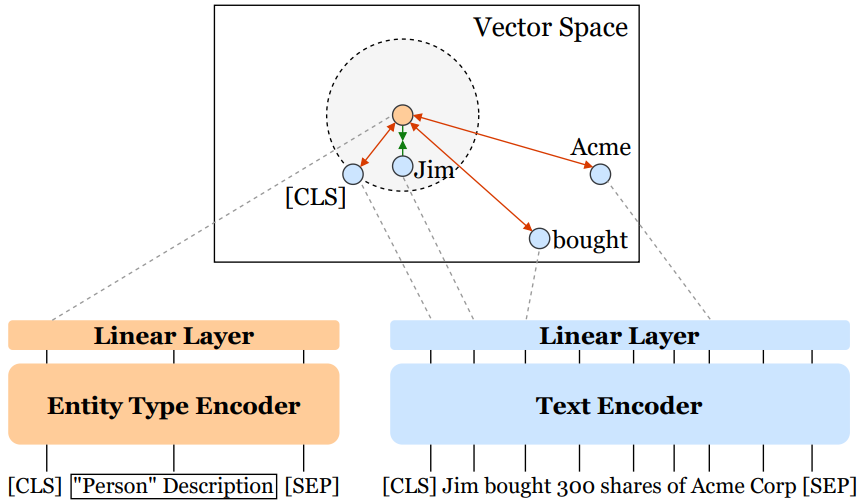
图 1:模型总体架构
实体类型嵌入:实体类型编码器的目标是生成实体类型嵌入,作为向量空间中对比学习的锚点。在这项工作中,关注预定义的实体类型集合 ,其中每个实体由一段自然语言描述,并使用 表示第k个实体类型的token序列。对于给定的实体类型 ,其使用BERT作为实体类型编码器(BERTE),并添加一个额外的线性层来计算相应的实体类型嵌入:
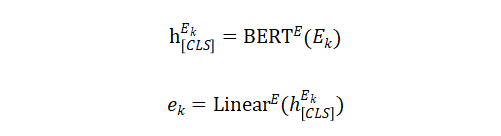
文本token嵌入:与实体类型嵌入类似,再次使用BERT作为文本编码器(BERTT),并简单地使用最终的隐藏层状态作为文本token表示:
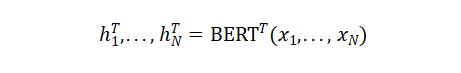
2、损失函数
本部分介绍了命名实体识别的对比学习损失函数。假设一个跨度(i,j)是输入文本中的连续token序列,其起始标记位于位置i,结束标记位于位置j。相似度函数为 τ ,其中 τ 是一个标量参数。
基于跨度的目标:按下面的公式获取跨度(i,j)的向量表示:
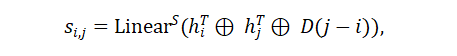
其中 , 是文本token嵌入, , 是一个可学习的线性层, 表示向量串联, 是一个可学习的跨度宽度嵌入 的第 行。基于此,基于跨度的互信息神经估计(infoNCE)可以被定义为
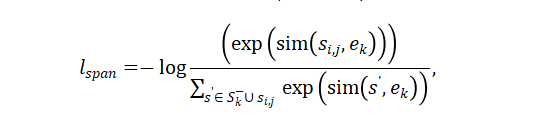
其中跨度 属于实体类型 , 是所有输入文本中所有不属于 的可能跨度, 是实体类型嵌入。
基于位置的目标:基于跨度的目标的一个局限性是它以相同的方式惩罚所有反例,即使它们是部分正确的跨度,例如与正确实体跨度具有相同的起始或结束标记的跨度。直觉上,预测部分正确的跨度比完全错误的跨度更可取。因此,作者提出了基于位置的对比学习目标。具体而言,其使用附加线性层来计算 的两个额外的实体类型嵌入, , ,其中 , 分别是开始和结束位置的类型嵌入, 来自实体类型编码器。相应地,可以使用两个附加的线性层来计算开始和结束标记的相应token嵌入, , ,其中 是文本token嵌入。使用 , 作为锚点,然后通过对比学习定义了两个基于位置的损失函数:
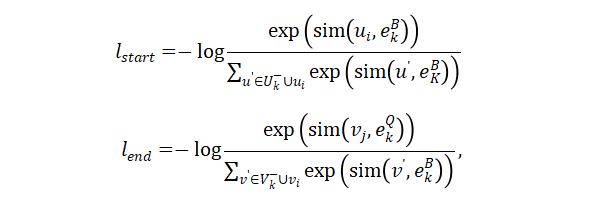
其中 , 是输入文本中不属于实体类型k的任何跨度的起始/结束位置的两个集合。与基于跨度的目标相比,基于位置的目标的主要区别来自相应的负面集,其中起始和结束位置彼此独立。换句话说,基于位置的目标可以潜在地帮助模型做出更好的起始和结束位置预测。
非实体情况的阈值设置:尽管上述定义的对比学习目标可以有效地将正面跨度推向其在向量空间中对应的实体类型,但在测试时,模型可能无法决定跨度应该多接近才能预测为正面。换句话说,该模型无法正确地将实体跨度与非实体跨度分开。为解决这个问题,作者使用特殊标记[CLS]与实体类型之间的相似度作为动态阈值。直观上,[CLS]的表示阅读整个输入文本并总结上下文信息。
为了学习阈值,作者选择通过额外的自适应学习目标扩展了原始对比学习目标,用于非实体情况。具体而言,对于开始损失,增强的开始损失定义为:
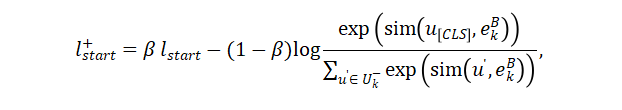
增强的结束损失可以以相似的形式定义。对于跨度损失,作者使用跨度嵌入 来获取增强的跨度损失:
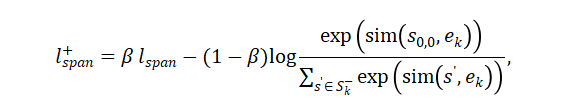
注意,作者使用了一个单一的标量参数 β 来平衡三个目标的自适应阈值学习和原始的对比学习。
训练:最后,作者通过结合之前讨论的三个增强对比学习,考虑一个多任务对比学习形式,这使得总体训练目标如下所示:
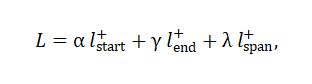
其中 α,γ,λ 都是标量参数。
3、推理策略
在推理期间,模型枚举所有长度小于L的可能跨度,并基于每种实体类型的起始/结束/跨度情况计算三个相似度得分。考虑两种预测策略:联合位置-跨度和仅跨度预测。在联合位置-跨度情况下,对于实体类型 ,其剪枝掉具有起始或结束相似得分低于学习阈值的跨度,即 或 。然后,只有那些跨度相似度得分高于跨度阈值的跨度被预测为正数,即 。对于仅跨度策略,其只依赖跨度相似度得分,并将所有合格的跨度保留为最终的预测结果。实验发现仅跨度推理更加有效,因为联合推理更容易受到注释工作的影响。
实验
作者在有监督和远程监督两种设置下评估了该方法。
有监督的NER结果:表1呈现了该方法与所有先前方法在三个嵌套NER数据集(ACE2004、ACE2005和GENIA)上评估的比较。方法在所有三个数据集上均达到了SOTA性能。表2将该方法与BLURB基准测试中的所有先前提交进行比较。
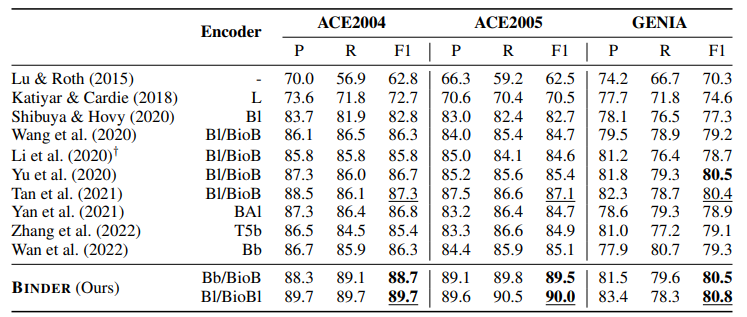
表 1:有监督的嵌套NER

表 2:有监督的扁平NER
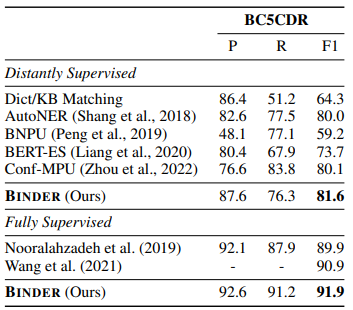
表 3:远程监督NER
比较两种设置,可以观察到远程监督结果仍然与有监督结果存在超过10个点的差距,表明有进一步降低假反例噪声的潜力。
总结
作者提出了一个使用对比学习的双编码器框架来进行NER,将文本和实体类型分别映射到相同的向量空间中。为了将实体跨度与非实体跨度分开,作者引入了一种新的对比损失来共同学习跨度识别和实体分类。在监督和远程监督设置下的实验表明了该方法的有效性和鲁棒性。作者进行了广泛的分析来解释其方法的成功并揭示增长机会。未来的方向包括进一步改进低性能类型并在自监督零样本设置中应用。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。