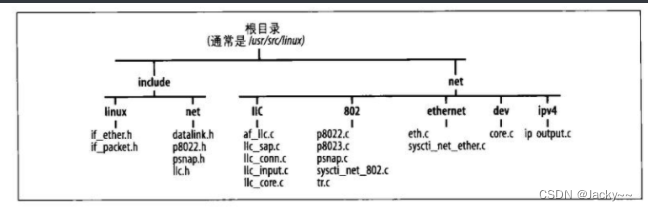
文章目录
前言
协议是所有通信的架构:指示每位通信者如何理解通话的另一端。在Linux中,对通信的理解是通过网络中各层的协议处理函数。本篇说明这些处理函数如何安装、如何在执行期间被选中以及如何启用。
网络协议栈概论
我想你应该熟悉TCP/IP协议,然而还有一些协议也很常见,例如LLC(Logical Link Control,逻辑链接控制)以及SNAP(Sub network Access Protocol,子网访问协议),但你可能还不懂。我们要介绍一些关键协议及彼此间的关系。网络协议最著名的两个模型就是七层的OSI模型以及五层的TCP/IP模型。如下图所示。即使因为各种原因并为实际实现过,OSI模型一直是讨论网络链接时很重要的参考点。TCP/IP模型包含了当今计算机所用的多数协议。
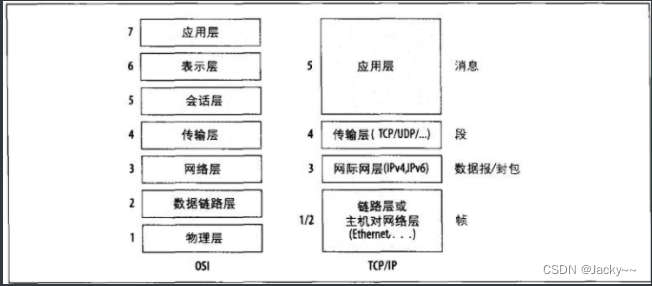
每一层中都哟偶很多协议可用。在最低层的接口交换数据,而所用的协议是预先决定的。协议的驱动程序被关联至该接口,而来到该接口的所有数据都假定会遵循此协议(也就是Ethernet)。如果没有,就会回报错误,不会有任何的通信发生。
但是,一旦驱动程序必须把数据交给高层时,就发生了协议的选择问题。L3的数据应该由IPv4、IPv6、IPvX(Novell NetWare协议)、DECnet或其他网络层协议中的那个协议处理呢?此外,从L3到L4时也需要做类似的选择;L4有TCP、UDP、ICMP以及其他协议可用。
我们这里主要介绍最低的三层,而第四层会简要的提一下:
单独一个封包传输数据通常在链接层被称为帧,在网络层则称为封包,在传输层称为端,而在应用层则称为消息。
这些分层通常称为网络协议栈,因为通信会往下传播过各个分层,知道实际上经过线路(或无线频道)传输,然后再返回来。报头也会以LIFO的方式添加和删除掉。
大蓝图
下图是建立在上图所示的TCP/IP模式之上。显示出相邻分层间的每个接口会由哪一章说明。有些接口会涉及由协议栈从上到下的通信,而其他的则是由协议栈从下到上。

-
在协议栈中向上传递(用于接收信息)
-
在协议栈中向下传递(用于传送信息)
我们这里并不讨论套接字接口。然而,对于AF_PACKET套接字类型而言,有一点值得一提,即Linux在链路层捕捉帧并将其注入至链路层的方式:直接跳过所有中间的协议层。网络嗅探器(如tcpdump和Ethereal)是AF_SOCKET套接字的最普遍的用户。从图中可知,AF_{ACKET}套接字直接把帧交给dev_queue_xmit,并直接从网络协议分派函数接收入口帧。
上图只显示了两种协议系列(PF_INET,PF_PACKET),但是Linux内核还实现了其他多种协议。例如:
-
PF_NETLINK- 网络配置较好接口
-
PF_KEY- 网络安全服务的关键接口
-
PF_LLC- 参见“逻辑链接控制(LLC)”一节
Ethernet的链路层的选择(LLC和SNAP)
虽然链路层协议会被所用的硬件绑定,但是,Ethernet标准可让我们在协议之间做某种选择。首次尝试将这种选择标准化的协议称为LLC(逻辑链接控制)。因为LLC提供的选项很有限,所以很少使用。随后,IEEE 802委员又制定了SNAP(子网络访问协议)协议标准,现已相当常见。这些字协议的实现会在后面描述。
在LLC中,报头内含一个字段,指出SSAP(Source Service Access Point,来源地服务访问点)的协议以及DSAP(Destination Service Access Point,目的地服务访问点)的协议。然而,每个字段只有8位,其中一位指出是否使用了多播的标识,而另一位指出该地址是一个网络的区域地址还是全球都识别的地址。因此,只剩6位可用于指明协议,因为LLC最多只能支持64种协议,使得此项技术难以普及。
鉴于以上原因,IEEE 802委员会在SSAP和DSAP字段中提供一个特殊值,依次扩充LLC。此特殊值指出来源地或目的地所用的协议是由报头中另外5个字节标识。采用这项扩充功能(改称为SNAP),就有40位可以分派给各种协议了。
网络协议栈的操作方式
来初略考察一个通信范例,以了解通信点之间如何做选择。
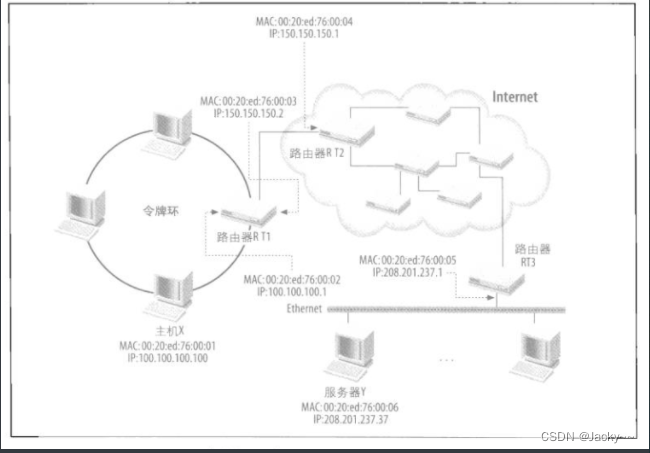
如下图所示,假设有一个用户在主机X,想使用网页浏览器从服务器Y上的网站服务器下载一页HTML网页。要回答如下一些问题:
-
主机X和服务器Y位于不同的局域网络中,它们如何相互对话?
-
主机X不知道服务器Y实际位于何处,主机X如何知道该把请求传送至何处?
-
如果服务器Y运行的应用程序不止一个(不只是网站服务器),其操作系统如何确定该由那个应用程序处理来自主机X的请求?
-
如果主机X上运行的应用程序不止一个(不止浏览器),其操作系统如何确定该由那个应用接收返回的数据?
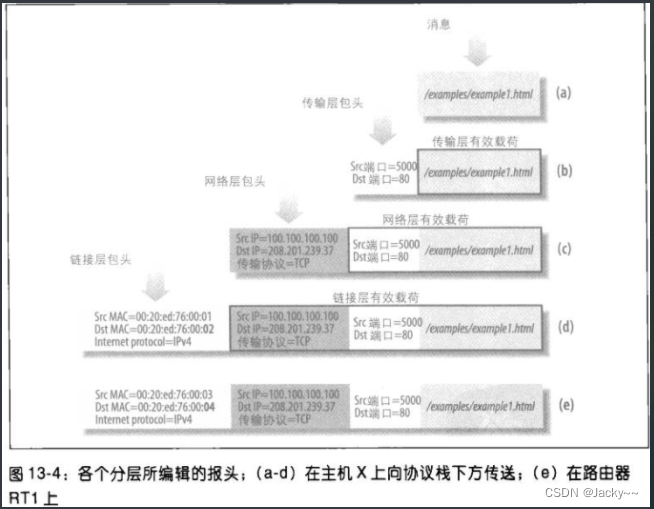
让我们跟随网页的请求,通过网络协议栈看一看这些问题如何解答。我们以上图和下图作为参考
-
应用层、主机X- 浏览器读取用户请求的URL,假设是
http://www.oreilly.com。浏览器使用域名系统(Domain Name System,不做讨论)把网址www.oreilly.com解析成IP地址(假设是208.201.239.37)。至于怎么找出主机X和使用此地址的服务器Y之间的路径,就是IP协议(L3,网络层)的事了。现在,浏览器在应用层对208.201.239.37启动了一个HTTP会话,然后,浏览器启用TCP把流量带往远程网站服务器(使用TCP而非UDP是因为HTTP需要可靠的信道来传递大量数据,而不会造成损毁)。现在,请求从网络协议栈上方向下传送。
- 浏览器读取用户请求的URL,假设是
-
传输层,主机X-
TCP层在必要时会把HTTP消息请求分成几个节段,然后为每个节段加上一个TCP报头。此外,TCP会加入来源地和目的地端口。端口号使操作系统可以把请求导向至正确的应用程序。服务器Y的网站服务器会监听默认的HTTP端口
80,除非明确配置成使用另一个端口号,然后在哪里获取所有流量。服务器Y会把响应导向至主机X的端口5000,也就是来源地端口号,而服务器就所接收到的请求就是从主机的这个端口发出的。 -
端口号是一种L4的概念,所以,TCP和UDP各有一组端口可用。
-
主机X的TCP层知道目的地端口是80,因为浏览器使用分派给HTTP协议的默认端口(除非URL中提供另一个不同的端口)。分派给浏览器的来源地端口(处理入口流量时指认目的应用程序)是由OS分派的(除非应用程序要求特定的端口)。我们假设该端口为5000.会话两段可以使用不同的端口。
NAT(Network Address Translation,网络地址转换)以及代理防火墙(proxying firewall)使得这项议题更为复杂,但是,从这里的讨论应该可以看清楚应用程序彼此间如何联系的轮廓。TCP层不知道该如何把那些阶段送往目的地。因此TCP层会启用IP层,在每个传输请求中都传递目的地IP地址。
-
-
网络层、主机X-
IP层不关心应用程序或端口。其所做的事就是检查封包的IP地址以及和IP相关的网络选项。其重责大任就是查询路由表(很复杂的过程,后面会分析),以找出该封包应该经过路由器RT1.IPv4协议后面会说明。
-
封包要往下传到另一层以便于被传送至该路由器,但是,IP层必须在此层找出路由器的正确地址。因为L2涉及到相邻主机间的通信(如主机共享LAN或者点对点链接),因此,IP层用于找出特定IP地址相关联的L2地址的流程就称为邻居协议(neighbor protocol)。后面会进行说明。
-
-
链路层,主机X和路由器RT1-
这一层的一部分是由设备驱动程序所实现的。在LAN上,Ethernet是最常见的协议,但是还有
ATM、Token Ring、FDDI以及其他协议存在。长距离的链接会使用专门的铜缆线或光纤缆线;最简单的链接就是几百万家庭和小办公室用户通过其ISP所建立的拨号连线。LAN使其自己的(L2)寻址方案与TCP/IP无关。对Ethernet(以及一般的IEEE 802网络)而言,地址是6个八位字节构成,而且通常称为MAC地址。在专线上(如拨号链接)并不需要L2寻址机制,因为每一边都是直接传送给另一边。 -
不同的链接可能使用不同类型的报头,因为每一种都和硬件有关。这些报头所携带的信息对应用层的浏览器和服务器而言都没有意义。
-
-
路由器RT1、RT2等等-
路径中的每个路由器(最后一个除外)都会经过下列流程把封包转发至其最终的目的地:
-
删除链路层报头
-
由于链路层报头中的特定子段,可以看到L3层协议就是IP。
-
确定本地系统不是封包目的地,因为IP报头中的目的地IP地址不在其自己的IP地址之列。
-
把IP包转发至通往服务器Y路径下的下一个路由器。为此,路由器会查询其路由表,以选出下一个跳点路由器,然后建立新的链路层报头。
-
-
正常来讲,封包在系统间传送时,L3(IP报头)上的信息不会改变。而每个链接上都会使用不同的L2报头。
-
当封包终于到达路由器RT3时,RT3会发现服务器Y和其直接连接,因此没必要再把封包绕送至另一个跳点。
-
一旦消息到达目的地服务器时,就会再由下而上穿越网络协议栈。
-
-
链路层,服务器Y- 剥离L2报头时,此层会检查一个字段,以了解该由那个协议处理L3层。得知L3是由IP处理处理后,链路层会启用适当的函数以继续处理L3包(也就是L2有效载荷)。本章多数内容都是讨论协议注册的方式,以及处理指出该用那个协议的关键字段。
-
网络层、服务器Y- 此层识别出其自己系统的IP地址(
208.201.239.37)就是封包中的目的地址,因此,此封包应该在本地接收处理。网络层会剥离L3报头,再次检查一个字段,以了解由哪一个协议处理L4.
- 此层识别出其自己系统的IP地址(
我们已经知道,每个分层都是提供各式各样的协议,而每一种协议都由一组不同的内核函数处理。因此,当封包回头向协议上方传送时,每一种协议都必须搞清楚下一较高层所用的协议是哪一种,然后启用适当的内核函数以处理该封包。
在最低的软件层L2上,所用的硬件决定所用的协议。如果帧是在Ethernet接口上呗接收,接收者知道其包含了一个Ethernet报头,而Token Ring接口则知道其包含了一个Token Ring报头等等。这里不能模棱两可,除非指定LLC或SNAP。LLC和SNAP后面介绍。
当封包在网络协议栈中向上传送时,每一个协议在其报头中都需要一个字段,指出下一阶段的处理该使用那个协议。此进程如下图
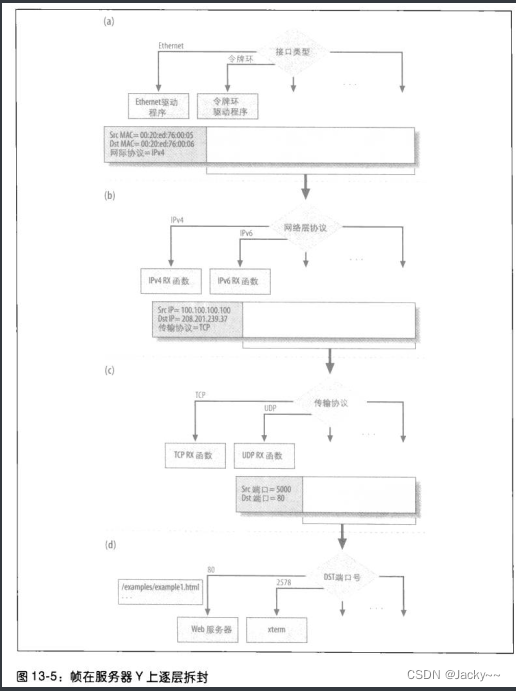
因此,从图中a的L2转至b中的L3时,就依赖于L2检查L2报头中,“上层协议”字段。同样的,L3层也会检查其报头内的一个字段,以促成转至L4,如b和c所示。最后,L4使用封包的“目的地端口”字段把封包从内核中取出,然后找出在本地主机处理该封包的进程(如网站服务器)。
执行正确的协议处理函数
就每种网络协议而言,无论其所在的分层为何,都有一个初始化函数。其中包括L3协议(如IPv4和IPv6)、链路层协议(如ARP)等等。就静态包含在内核中的协议而言,初始化函数会在引导期间执行,就编译成模块的协议而言,当模块加载时,初始化函数就会执行。此函数会分配内部数据结构,通知其他子系统有关该协议的存在,在/proc中注册文件等等。有一项关键任务是在内核内注册一个处理函数,以处理该协议的流量。
为简洁起见,我们会说明设备驱动程序如何启用L3协议,但是,同样的原理也适用于任何分层的任何协议。
当设备驱动程序接收到一帧时,会将其保存在一个sk_buff缓冲区数据结构,然后对如下所示的protocol字段做初始化:
struct sk_buff
{
... ... ...
unsigned short protocol;
... ... ...
}
此字段的值可以是内核所用的任何值,以识别特定的协议,或者进来的帧中一个MAC报头中的一个字段。此字段会由netif_receive_skb内核函数查询,以确定该由那个函数来执行,以处理L3的封包。参考下图:
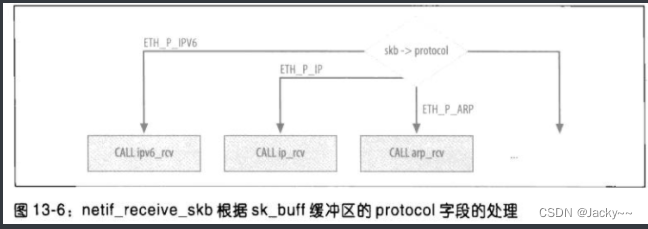
由内核用在protocol字段中涉及协议的值大多都列在了include/linux/if_ether.h中,,名为ETH_P_XXX。尽管有ETH前缀,但并非所有名称都涉及Ethernet硬件。如下表列出了内核内部所用的值,而这些值由设备驱动程序直接指定给skb->protocol,而不是从帧报头中剥离出来(表中省略的值并没有分派函数处理函数)。例如,表中第一列指出,内核处理函数ipx_rcv用于处理一个输入封包,而且其skb->protocol字段为ETH_P_802_3。
| 符号 | 值 | 函数处理函数 |
|---|---|---|
| ETH_P_802_3 | 0x0001 | ipx_rcv |
| ETH_P_AX25 | 0x0002 | ax25_kiss_rcv |
| ETH_P_ALL | 0x0003 | 这不是真正的协议,而是作为处理函数的通配符,如监听所有协议的封包探嗅器。 |
| ETH_P_802_2 | 0x0004 | llc_rcv |
| ETH_P_TR_802_2 | 0x0011 | |
| ETH_P_WAN_PPP | 0x0007 | sppp_rcv |
| ETH_P_LOCALTALK | 0x0009 | ltalk_rcv |
| ETH_P_PPPTALK | 0x0010 | atalk_rcv |
| ETH_P_IRDA | 0x0017 | irlap_driver_rcv |
| ETH_P_ECONET | 0x0018 | econnet_rcv |
| ETH_P_HDLC | 0x0019 | hdlc_rcv |
并非所有ETH_P_XXX值都分派一个处理函数。在两种情况下,可以不予指定:
-
该协议没有处理函数(也就是内核不支持)。
-
另一个协议处理函数可以间接处理该协议,如SNAP的情况。此情况会在“逻辑连接控制(LLC)”以及“子网访问协议(SNAP)”两节中讨论。
可惜,并非只要取出L2报头中的字段,就能搞清楚启用那个处理函数;skb->protocol和处理帧的协议处理函数间的关联关系不一定都是一对一的。有些情况下,特定ETH_P_XXX的协议处理函数实际上只会从帧报头中读取其他参数(没有帧处理),然后把帧交给另一个会处理该帧的协议处理函数。其中一例就是ETH_P_802_2处理函数。
如前面的章节所述,netif_receive_skb是把入口帧分派给正确的协议处理函数的函数。当特定协议没有处理函数可用时,该帧就会被丢弃。
在特殊情况下,单一封包可以传递给多个处理函数。例如,当封包探嗅器在运行时就是这种情况。这种话操作模式有时称为混杂模式,也就是表中的ETH_P_ALL。这类处理函数通常不用于为接受者处理封包,而只是窥探特定设备或一组设备,其目的是纠错或收集统计数据。
特殊媒介封装
到目前为止,Ethernet是实现共享和点对点网络联机最常见的机制。本书中讨论L2时,始终是指Ethernet设备驱动程序。然而,Linux允许你使用现在PC上由任何最常见的媒介(mdia)携带IP流量(以及有时任何网络协议流量)。可用于传输IP的媒介范例包括串行和并行端口(SLIP/PLIP/PPP)、FireWire(eth1394)、USB、蓝牙(Bluetooth)以及IrDA等等。
这类媒介会把网络设备定义成通用端口的抽象层,通常是通过对通用媒介设备驱动程序做扩充。这类虚拟设备对那些上层设备而言,看起来就像是真实的NIC。
以下是接收和传输在这些虚拟网络设备上的实现方式:
-
传输net_device的hard_start_xmit虚拟设备函数指针,由设备驱动程序初始化为一个能够根据媒介所用的协议而封装IP封包(假设原本就是IP封包)的函数。
-
接收- 当通用驱动程序从其端口之一接收数据时,会把媒介报头剥离(如同Ethernet设备会剥离Ethernet报头一样),对
skb->protocol初始化,然后调用netif_rx通知其上层。当这些媒介只用于点对点联机时,就没有必要使用链接层报头,所以skb->protocol会静态初始化成ETH_P_IP;在其他情况下,媒介封装可能也会包括一个假设的Ethernet报头,所以skb->protocol会由eth_type_trans函数做初始化(如同真实的Ethernet驱动程序所做的那样)。
- 当通用驱动程序从其端口之一接收数据时,会把媒介报头剥离(如同Ethernet设备会剥离Ethernet报头一样),对
如何把给定媒介类型的通用设备驱动程序与虚拟网络设备接口,是实现细节的问题。具体依赖于媒介而定,也许会提供同步或异步接口,或在接收和传输路径上使用缓冲机制等。
协议处理函数的组织
下图所示是各种协议处理函数在内核内的组织方式。每种协议都由packet_type数据结构描述

为了访问快一点,多数协议都用到一个简单的hash函数。16个列表组织成一个数组,也就是全局变量ptype_base所指的数组。当一个协议使用dev_add_pack函数注册时,此函数就会对协议类型执行hash函数,然后把packet_type结构分派至16个列表之一。稍后,要找出一个ptype_type结构时,内核只要重新运行hash函数,并且遍历匹配列表。
那些ETH_P_ALL协议被组织在它们所属的列表中,也就是全局变量ptype_all所指的列表。此列表中的协议数目存储在netdev_nit。而dev_queue_xmit和qdisc_restart会使用netdev_nit检查某个PF_PACKET套接字是否开启(也就是监听中的探嗅器),使其得以传递入口帧的副本。
协议处理函数的注册
无论是系统启动或其他时刻,当一个协议注册时,内核就会调用dev_add_pack,把一个定义在include/linux/netdevice.h类型为packet_type的数据结构传进去:
struct packet_type
{
unsigend short type;
struct net_device *dev;
int (*func)(struct sk_buff *, struct net_device *,
struct packet_type *);
void *af_packet_priv;
struct list_head *list;
};
这些字段的意义如下:
-
type- 协议代码。此值可以是上表中所列的任何值之一,不同表内的协议间的差异性后面会进行阐述
-
dev- 设备指针(如
eth0),该协议为此设备而开启。置为NULL时,指的是“所有设备”。由于此参数有可能使不同的设备有不同的处理函数,或者把特定处理函数关联给特定设备。通常不会这样做,不过有助于测试。PF_PACKET套接字时常以此监听特定设备。例如,像tcpdump -i eth0这样的命令会通过一个PF_PACKET套接字建立一个packet_type实例,并将dev初始化为与eth0关联的net_device实例。
- 设备指针(如
-
func- 当
netif_receive_skb必须处理一个skb->protocol=type(如ip_rcv)的帧时,就会调用此函数处理函数。注意,此func的输入参数之一是一个指向packet_type结构的指针:此结构由PF_PACKET套接字使用,以访问af_packet_priv字段。
- 当
-
af_packet_priv- 由
PF_PCKET套接字使用。这是一个指针,指向与packet_type结构的建立者相关联的sock数据结构。此字段允许dev_queue_xmit_nit不把缓冲区传递给传送者,而且通过PF_PACKET接收函数把输入数据传递给正确的套接字。
- 由
-
list- 用于把这个数据结构和其他在同一个
bucket的列表中相冲突的实例链接起来。
- 用于把这个数据结构和其他在同一个
当你有多个packet_type实例都关联于有相同的type的协议,则匹配type的输入帧就会通过为这些实例启用func,转交给所有这些协议处理函数实例。
为每个协议注册时,内核会对packet_type结构做初始化,然后调用dev_add_pack。这里有个取自net/ipv4/ip_output.c的范例,显示出IPv4关键代码如何注册IPv4协议处理函数。
当IPv4协议在引导期间初始化时,ip_init函数会被执行。其中一种结果是,IPv4packet_type结构中的函数ip_rcv会注册成此协议的函数处理函数。所有Ethernet帧接收时,若ETH_P_IP的值为Protocol Above,就会由函数ip_rcv处理。
static struct packet_type ip_packet_type =
{
.type = __ocnstant_htons(ETH_P_IP),
.func = ip_rcv,
}
...
void __init ip_init(void)
{
dev_add_pack(&ip_packet_type);
...
}
dev_add_packet相当简单:检查要新增的处理函数是否为协议探嗅器(pt->type == htons(ETH_P_ALL))。如果是,则此函数会将其添加到ptype_all所指的列表,然后递增已注册的协议探嗅器的数目(netdev_nit++)。如果处理函数不是探嗅器,就会被插入至ptype_base所指的16个列表之一(依赖于hash编码的值)。ptype_base和ptype_all所指的数据结构都会由ptype_lock回转锁保护。
void dev_add_pack(struct packet_type *pt)
{
int hash;
spin_lock_bh(&ptype_lock);
if(pt->type == htons(ETH_P_ALL)){
netdev_nit++;
list_add_rcu(&pt->list, &ptype_all);
}else{
hash = ntohs(pt->type) & 15;
list_add_rcu(&pt->list, &ptype_base[hash]);
}
spin_unlock(&ptype_lock);
}
函数dev_remove_pack,如其名称所暗示与dev_add_pack互补。
void dev_remove_pack(struct packet_type *pt)
{
__dev_remove_pack(pt);
synchronize_net();
}
dev_remove_pack会从ptype_all或ptype_base中把packet_type结构删掉,而synchroize_net是用于确保dev_remove_pack返回时没有谁还持有已删除的packet_type实例的引用。
如果dev_add_pack在负责模块初始化的含糊init_module之内调用,则dev_remove_pack最可能在cleanup_module(当模块要被删除时,由内核调用)之内被调用(可以在net/ax25/af_ax25.c中找到范例)。另一方面,如果该协议静态包含在内核内,就会在引导期间自动被注册,而且只有当系统关机时才会被删除,IPv4协议是绝不会在运行期间被删除的协议。
Ethernet与IEEE 802.3帧
有很多协议都属于广义的术语Ethernet之下。802.2和802.3标准分别由协议ETH_P_802_2和ETH_P_802_3表示,但是,还有很多其他Ethernet协议如下表,以及LLC和SNAP扩充协议。这些标准构成了一些足以支持所有变化版本协议的手段(关于h_proto会在下一节讨论)。

Ethernet是在IEEE建立其802.2和802.3标准前设计的。802.2和802.3标准并非纯粹的Ethernet,只不过通常都称为Ethernet标准。所幸,IEEE 802委员会决定让协议可兼容。每块Ethernet卡都可接收802标准帧类型以及旧式Ethernet帧,而内核可以提供一个函数使设备驱动程序可以识别这些帧。
以下是Ethernet报头的定义:
struct ethhdr
{
unsigned char h_dest[ETH_ALEN]; /*目的地eth地址*/
unsigned char h_source[ETH_ALEN]; /*来源地eth地址*/
unsigned short h_proto; /*封包类型ID字段*/
}__ATTRIBUTE__ ((packed));
后面我们讨论LLC和SNAP时就会知道,其他字段也会关注ethhdr结构。这里我们关注的焦点是协议字段h_proto。尽管如此,但实际上可以存储正在使用的协议或帧的长度。这是因为此字段的大小是2个八位字节,但是,一个Ethernet帧的最大尺寸为1500个字节(实际上,如果包含SA、DA、校验和字段以及开头内容的话,尺寸可以多打1518个字节。使用802.1q的帧有四个额外的封装字节,因此可以有的尺寸是1522个字节)。
为了节省空间,IEEE决定使用大于1536的值以表示Ethernet协议。有些早已存在而加上标识符后依然低于1536的协议(0x600十六进制),也已更新为满足这项准则。然而,802.2和802.3协议使用这个字段存储帧的长度。界于1501和1535之间的值,在此字段中是非法的。
下图所示是Ethernet报头可能的几种变种,图a所示是简单的Ethernet,图b所示是802.2和802.3变种。如你所见,对前者而言,那个字段是作为协议字段,而后者而言,该字段又变成了长度字段。此外,802变种也可支持LLC(图c)和SNAP(图d)。
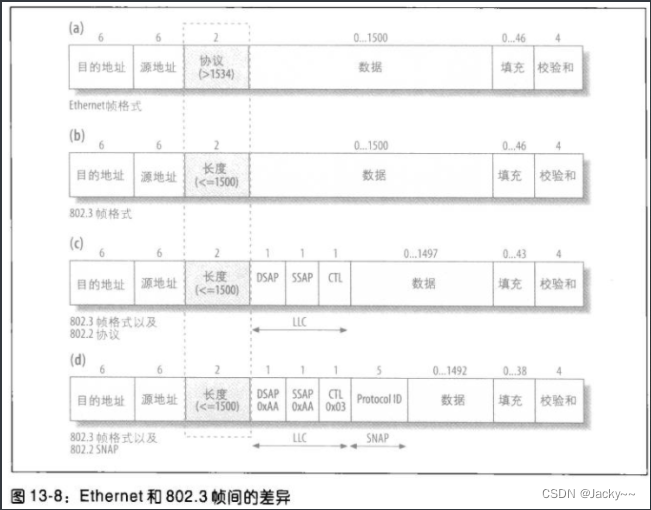
Linux在eth_type_trans函数中完成协议和长度这种特殊的区分。下列代码片段代表的是典型的环境。当drivers/net/3c509.cEthernet驱动程序接收一个帧时就会用到。netif_rx函数负责把帧拷贝到输入队列中,然后设置NET_RX_SOFTIRQ标识,让内核知道队列中有新帧。调用netif_rx之前,调用者要先调用eth_type_trans做一些重要的初始化工作。
el3_rx(struct device *dev)
{
... ... ...
skb->protocol = eth_type_trans(skb, dev);
netif_rf(skb);
... ... ...
}
eth_type_trans执行两项主要任务:设置封包类型以及设置协议。设置协议的工作是在其返回值中完成的。先来说明封包类型的设置,再回到本节的主要议题:协议。
设置封包类型
eth_type_trans函数会把skb->pkt_type设成include/linux/if_packrt.h中所列PACKET_XXX的值之一。
-
PACKET_BROADCAST- 该帧是传给链路层广播地址(对Ethernet而言就是
FF:FF:FF:FF:FF:FF)
- 该帧是传给链路层广播地址(对Ethernet而言就是
-
PACKET_MULTICAST- 该帧是传给链路层多播地址。细节在本节后面讲述
-
PACKET_OTHERHOST- 该帧并非要传送给接收接口。然而,该帧没有立刻被丢弃,而是传给次最高层。如前所述,可能有协议探嗅器或其他爱管闲事的协议想看一下这个帧。
当eth_type_trans没有显示地设置skb->pkt_type时,其值就会是0,也就是PACKET_HOST。这意味着接收接口就是帧的接收者(从链路层的角度看,也就是MAC地址匹配)。
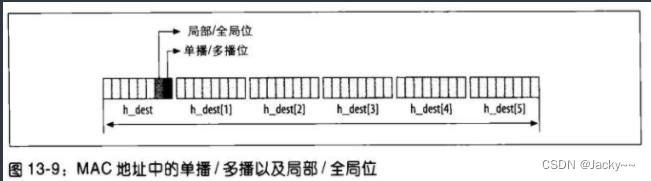
设置正确的封包类型所需的信息,大多数都会在报头中明确指定。Ethernet地址是48位或6字节长。第一个字节(网络字节尾端)的最高两个位有特殊意义:参考下图
-
位0区分多播地址和单播地址。广播地址是多播的特殊情况。设为1时,此位指的是多播;设为0时,指的是单播。通过
if(*eth->h_dest & 1)检查此位后,此函数会继续通过memcmp(eth->h_dest, dev->broadcast, ETH_ALEN)比较此地址设备的广播地址,以了解该帧是否为广播地址。 -
位1区分局部地址和全局地址。全局地址是全球唯一的,而局部地址就不是了:系统管理员可自行决定要如何适当分派局部地址。设为1时,此位指全局地址;为0时,指的是局部地址。
因此,eth_type_trans的开头部分如下:
unsigned short eth_type_trans(struct sk_buff *skb, struct net_device *dev)
{
struct ethhdr *eth;
unsigned char *rawp;
skb->mac.raw=skb->data;
skb_pull(skb,ETH_HLEN);
eth=eth_hdr(skb);
skb->input_dev = dev ;
if(*eth->h_dest&1)
{
if(memcmp(eth->h_dest, dev->broadcast, ETH_ALEN)==0)
skb->pkt_type=PACKET_BROADCAST;
else
skb->pkt_type=PACKET_MULTICAST
}
else if(1/*dev->falgs & IFF_PROMISC*/)
{
if(memcmp(eth->h_dest, dev->dev_addr, ETH_ALEN))
skb->pkt_type=PACKET_OTHERHOST;
}
}
当接口进入混杂模式时,dev->falgs中的IFF_PROMISC标识就会被设置。如前述代码片段所示,当目的地MAC地址与接口的地址不匹配时(无论IFF_PROMISC是否设置),eth_type_trans都会把skb->pkt_type设为PACKET_OTHERHOST。这样将允许PF_SOCKETS处理函数接收副本,但是上层协议处理函数必须丢弃PACKET_OTHEHOST类型的缓冲区。(例如,参见arp_rcv和ip_rcv)。
设置Ethernet协议及长度
eth_type_trans的第二部分是获取在较高层所用协议的标识符。协议值也称为Ethertype,而有效类型的列表会随时保持更新,位于http://standards.ieee.org/regauth/ethertype。高于1536的旧Ethernet协议与802协议间的区别由下列代码片段完成:
if(ntohs(eth->h_proto) >= 1536)
return eth->h_proto;
rawp = skb->data;
if(*(unsigned short *)rawp == 0xFFFF)
return htons(ETH_P_802_3);
/*
* 真实802.2 LLC
*/
return htons(ETH_P_802_2);
}
如果大于1536的值会被解读成协议ID,那么,设备驱动程序该如何找出其接收的帧的大小?当协议/长度值小于1500或大于1536时,设备本身要把帧的大小存储至其寄存器之一,使得设备驱动程序可以读取。得益于为此目的而设的著名的位模式,设备可以搞清楚每个帧的大小。下列代码片段取自drivers/net/3c59x.c中的vortex_rx,显示出驱动程序如何先从设备读取大小,然后再据此分配缓冲区的过程:
/*封包长度:多达4.5k*/
int pkt_len = rx_status & 0x1fff;
struct sk_buff *skb;
skb = dev_alloc_skb(pkt_len + 5);
不要被上述代码的注释搞糊涂了。这个特殊设备可以接受的帧的尺寸可以多达4.5K,是因为此设备也处理FDDI NIC。
我们已知何为主机及网络字节尾端。由eth_type_trans返回的值,以及分派给skb->protocol的值采用网络字节尾端:从Ethernet报头中剥离出来时,已经处于网络字节尾端,此外,当eth_type_trans使用一个局部符号ETH_P_XXX时,就必须以htons宏将其从主机字节尾端转换至网络字节尾端。也就是说,当内核稍后访问skb->protocol,并且用来与ETH_P_XXX值比较时,必须把ETH_P_XXX转成网络字节尾端,或者把skb->protocal转换成主机字节尾端:使用什么尾端并不重要,重要的是比较时都是以相同尾端表达。换言之,下面两行代码是对等的:
ntohs(skb->protocol) == ETH_P_802_2
skb->protocol == htons(ETH_P_802_2)
因为eth_type_trans只会因Ethernet帧而被调用,其他媒介类型也有类似函数存在,有些名称的结尾是_type_trans,而有些有不同的名称。例如,下面的范例取自IBM Token Ring驱动程序(drivers/net/tokenring/ibmtr.c)的一些代码,在大家熟悉的netif_rx调用前,skb->protocol会被tr_type_trans设置,如同eth_type_trans为Ethernet设备所做的一样:
static void tr_rx(struct device *dev)
{
...
skb->protocol=tr_type_trans(skb, dev);
...
netif_rx(skb);
...
}
如果你看net/802/tr.c中的tr_type_trans,就会看到与eth_type_trans相似的逻辑,只不过对象是Token Ring设备。
还有些媒介类型会直接设置skb->protocol,而不用任何__type_trans辅助函数,因为这些媒介类型只能携带一种协议(如IrDA,AX25)。
逻辑链接控制(LLC)
LLC层是由IEEE 802委员会在为LAN做标准化规格时设计的。其想法是,不要只用一个较高层协议标识符,而是要更有灵活性,可以指定来源地的协议标识符(SSAP)以及目的地的协议标识符(DSAP)。在大多数情况下,对于任何给定连接而言,SSAP和DSAP都是相同的—事实上,当全局标识被设置时,SSAP和DSAP都是相同的——但是,有两个值就使系统具有灵活弹性,可以使用不同的协议。
LLC可以为其上层提供各种不同服务类型:
-
类型I- 无连接(如数据报文协议),不支持应答机制、流量控制以及错误恢复
-
类型II- 面向连接,支持应答机制、流量控制以及错误恢复。
-
类型III- 无连接,但有类型II的一些优点。
LLC帧的报头格式。相比之下有三个新字段:
-
SSAP
-
DSAP
- 这些是8位字段,用于指定所用的协议。
-
控制(CTL)
- 此字段的大小是依赖于所用的LLC的类型(类型I或类型II)。不会深入探讨LLC层,但是会假设此字段有1个字节长,而且其值为0x03(类型I, CTL=UI)。这样就足以了解本章后续的内容了。
LLC报头无法流行的原因有很多个。也许主要原因在于SSAP和DSAP标识符的8位限制,更糟糕的是这些位还保留了两个给单播/多播以及局部/全局标识。只有64个协议可以在剩余的6个位内指定,这样实在太过限制。
使用局部SAP时(由协议字段中的局部/全局标识指定),网络管理员必须确保所有系统都同意其所使用的局部SAP,因而使事情更为复杂而且可用性也减少了。全局SAP不可能模棱两可,但是新协议都没有使用全局SAP。下一节你会看到这种限制如何因为使用了SNAP的概念扩充了报头而获得解决。
下表是和Linux内核注册的SAP。与上表所列并且以dev_add_pack注册的协议相比,LLC使得内核在获取处理函数时使用了一个额外的层。
| 协议 | SAP | 函数处理 |
|---|---|---|
| SNAP | 0xAA | snap_rcv |
| IPX | 0xE0 | ipx_rcv |
IPX的情况
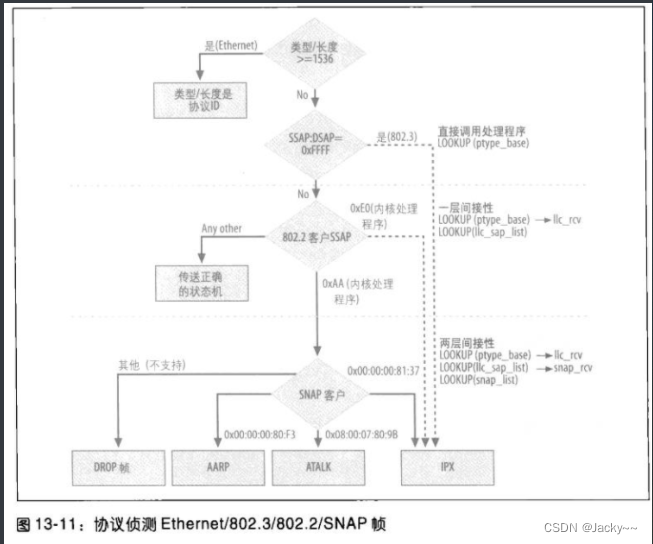
你可能会想,能否使用纯粹的802.3帧格式,因为它没有表示协议ID的地方。事实上,通常不会使用纯粹的802.3帧。唯一众所周知的例外涉及IPX、IPX封包可以通过未加工的802.3帧(也就是没有LLC报头的帧)而传送。接受者会通过一种手段识别这些封包。IPX报头的第一个字段是一个16位的校验和字段,正常来讲通过简单地设成0xFFFF予以关闭。因为0xFF/0xFF是无效的SSAP/DSAP组合,而且没有Ethertype有该值,因此,使用未加工的802.3的IPX封包就可轻易被识别。当这些封包被侦测出来时,skb->protocol就被被设成ETH_p_802_3,而其处理函数就是IPX处理函数。
Linux的LLC实现方式
802.2LLC层不仅做了拓展而且还被重新改写。内核的LLC实现支持类型I和类型II,有下列主要组件组成:
-
两个状态机。用于记录局部SAP以及建立在其上的连接的状态。
-
LLC接收函数,根据其所接收的输入帧把正确的输入数据反馈到两个状态机。
-
AF_LLC套接字接口。可用于在用户空间的LLC层顶部建立协议或服务。
我们不会深入探讨Linux内核的LLC实现的细节。这里只谈定义局部SAP所用的数据结构,以及简单说明一些输入帧是如何处理的。
使用定义在include/net/llc.h中的数据结构llc_sap定义局部SAP。其中一些字段如下:
-
struct llc_addr laddr- SAP标识符
-
int (*rcv_func)(struct sk_buff*, struct net_device *, struct packet_type *)- 函数处理。当一个SAP通过PF_LLC套接字开启时,此字段为NULL。当SAP由内核开启时,此字段向内核所提供的函数。
局部SAP由llc_sap_open建立,并被插入到llc_sap_list列表中。调用llc_sap_open时,可建立两种类型的SAP:
-
由内核本身所安装的SAP,安装内核层次的处理程序
-
由PF_LLC套接字所管理的SAP(例如,当服务器在PF_LLC套接字上使用
bind系统调用以将其绑定至给定的SAP)。
处理入口的LLC帧
每当送进来的帧被eth_type_trans归类为使用LLC报头时(因为其类型/长度字段小于1536,而且没有侦测到特殊的IPX情况),skb->protocol初始化为ETH_P_802_2之后就会导致llc_rcv处理程序被选中。此处理程序会根据LLC报头内的DSAP字段选出正确协议处理程序:为此,它会为那些由内核所开启的SAP调用以llc_sap_open注册的rcv_func处理程序,然后当SAP由PF_LLC套接字开启时,就把正确的输入数据输入到正确的状态机。(参考下图)

当两个状态机之一需要时(例如,用以通知接收到一个帧),就会由帧送出给定的SAP。PF_LLC套接字可以使用标准接口(如sendmsg)进行传输。在这两种情况下,适当的链路层报头已正确初始化后,帧就会直接输入到dev_queue_xmit。
子网访问协议(SNAP)
由于LLC报头的限制,802委员会又把数据链路报头进一步拓展。为了让协议的范围更大,还引入了SNAP的概念。基本上,当SSAP/DSAP分派了0xAA/0xAA值时,就有了特殊意义:跟在LLC报头的CTL字段之后的5个字节表示一个协议标识符。单播/多播以及局部/全局位已不再使用。因此,协议标识符的大小从8位跳变至40位。委员会决定使用5个字节的原因与MAC地址可以推导出多少协议编号有关。与SSAP/DSAP不同的是,SNAP编码的使用相当普遍。
因为SNAP标识符0xAA/0xAA是SSAP/DSAP的特例,因此,SNAP使用llc_sap_open的客户之一(参见net/802/psnap.c中的snap_init)。这意味着使用SNAP编码的协议将多一层间接性,即有三层!
在了解SNAP客户如何和内核注册之前,我们先简述如何定义SNAP协议ID。你可能已经知道,MAC地址由IEEE管理,而IEEE分2的24次方批将其卖出去。因为一个MAC地址是48位长(6个字节),因此,IEEE给予每个客户一个24位长的数字(也就是MAC地址的前3个字节),然后让客户可以把任何值放进剩下的24位。假设因为我想销售网卡,所以想买一批MAC地址。我们称分派给我的数字为XX:YY:ZZ。此时,我会成为XX:YY:ZZ:00:00:00与XX:YY:ZZ:FF:FF:FF之间的所有地址的拥有者。除了这些MAC地址,我还将分派界于XX:YY:ZZ:00:00与XX:YY:ZZ:FF:FF之间的SNAP编码。
当你从IEEE得到一个24位长的数字时,由于局部/全局以及单播/多播位的四种可能组合,实际上是给了你4个24位长的数字。
采用与SAP协议类似的注册和除名方式,SNAP层也提供register_snap_client和unregister_snap_client函数,也使用一个全局列表(snap_list)把所有和内核注册的SNAP协议链接。如下表是利用Linux内核注册的客户。
| 协议 | Snap ID | 函数处理例程 |
|---|---|---|
| AppleTalk地址解析协议 | 00:00:00:80:F3 | aarp_rcv |
| AppleTalk数据段传递协议 | 08:00:07:80:9B | atalk_rcv |
| IPX | 00:00:00:81:37 | ipx_rcv |
定义在include/net/datalink.h中的数据结构datalink_proto用于定义SNAP协议。其中一些字段如下:
-
unsigned short header_length- 这是数据链路报头的长度。在
register_snap_client中,其初始化设为8
- 这是数据链路报头的长度。在
-
unsigned_char type[8]- 协议标识符。只使用了5个字节
-
void (*request)(struct datalink_proto *, struct sk_buff *, unsigned char *)- 在
register_snap_client中,其初始值设为snap_request。此字段会对SNAP报头做初始化(只有协议ID),并把帧传给802.2代码。在传输用于填写数据链路报头的数据之前,此字段的函数就会被启用。
- 在
-
void (*rcvfunc)(struct sk_buff*, struct net_device *, struct packet_type *)- 入口流量所需的函数处理函数
这里只初略探讨IPX。值得指出的是,该协议在三种不同场合会以相同的处理函数向内核注册:
-
有Ethertype时
-
作为802.3 SSAP/DSAP协议
-
作为SNAP协议
下图总结了内核如何识别并处理Ethernet、802.2、802.3以及SNAP帧。
通过/proc文件系统进行调整
就Ethernet和802而言,/proc/sys/net中都有一个目录,/proc/sys/net/ethernet/(空的)和/proc/sys/net/token-ring/(只有一个文件)分别在net/core/sysctl_net_ethernet.c和net/802/sysctl_net_802.c中注册。只有当内核编译成支持Ethernet和Token Ring时,这两个目录才会被包含进来。
涉及的函数和变量
| 函数 | 说明 |
|---|---|
dev_add_pack |
添加/移除协议处理函数 |
dev_remove_pack |
|
register_8022_client |
为802.2协议注册/除名。这些函数被定义成包裹函数,内含llc_sap_open和llc_sap_close |
unresgiter_8022_client |
|
register_snap_client |
为SNAP客户注册/除名 |
unregister_snap_client |
|
llc_sap_open |
创建/移除SAP |
llc_sap_close |
|
eth_type_trans |
由Ethernet设备使用以剥离较高层协议标识符,然后把帧归类为单播/多播/广播 |
| 变量 | 说明 |
|---|---|
netdev_nit |
已注册的协议探嗅器的数目 |
ptype_base |
指向内含已注册协议处理例程的数据结构的指针 |
ptype_all |
同ptype_base,但是用于协议探嗅器 |
sanap_list |
SNAP客户列表 |
| 数据结构类型 | 说明 |
|---|---|
struct packet_type |
用于存储有关ETH_P_XXX协议处理函数的信息 |
struct datalink_proto |
用于表示SNAP协议 |
涉及的文件和目录
下图是本篇博客所涉及的文件的位置。在include/linux目录中,可以找到其他媒介类型的if_xxx.h头文件。net/llc目录中包含多个文件。