linux的虚拟网络技术
文章目录
前言
- 近几年,Docker、Kubernetes等容器化技术和容器编排工具的兴起使技术人员从应用部署和维护的泥淖中解脱出来,同时也改变了很多很多互联网公司的技术架构。笔者近期也在学习Docker和Kubernetes,对这些新技术所带来的便捷性和安全性非常着迷,其中尤其对容器化技术的网络实现方式更为好奇。今天就把近期的对Linux虚拟网络技术的学习成果分享出来,希望能和大家一起交流学习。
1. Network namespace
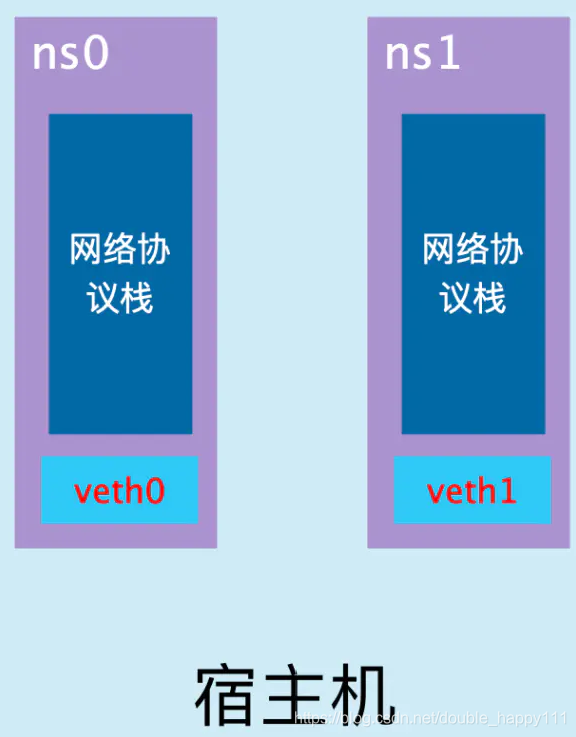
- Network Namespace 是 Linux 内核提供的功能,是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己都在独立的网络中。而且不同Network Namespace的资源相互不可见,彼此之间无法通信。
2. ip netns命令
- 可以借助
ip netns命令来完成对 Network Namespace 的各种操作。ip netns命令来自于iproute2安装包,一般系统会默认安装,如果没有的话,读者自行安装。 - 可以通过
ip netns命令完成对Network Namespace 的相关操作,可以通过ip netns help查看命令帮助信息:
[root@localhost ~]# ip netns help
Usage: ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id
- 默认情况下,Linux系统中是没有任何 Network Namespace的,所以
ip netns list命令不会返回任何信息。
[root@localhost ~]# ip netns list
[root@localhost ~]#
- 创建network namespace
- 创建一个love的命名空间
[root@localhost ~]# ip netns add love
[root@localhost ~]# ip netns list
love
- 新创建的 Network Namespace 会出现在
/var/run/netns/目录下。如果相同名字的 namespace 已经存在,命令会报Cannot create namespace file "/var/run/netns/ns0": File exists的错误。 - 对于每个 Network Namespace 来说,它会有自己独立的网卡、路由表、ARP 表、iptables 等和网络相关的资源。
- 操作network namespace
- 查看新创建 Network Namespace 的网卡信息
[root@localhost ~]# ip netns exec love ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- 可以看到,新创建的Network Namespace中会默认创建一个
lo回环网卡,此时网卡处于关闭状态。此时,尝试去 ping 该lo回环网卡,会提示Network is unreachable
[root@localhost ~]# ip netns exec love ping 127.0.0.1
connect: Network is unreachable
- 启用lo回环网卡,并进行ping测试
[root@localhost ~]# ip netns exec love ip link set lo up
[root@localhost ~]# ip netns exec love ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.130 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.051 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.068 ms
^C
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 0.051/0.083/0.130/0.033 ms
- 转移设备
- 我们可以在不同的 Network Namespace 之间转移设备(如veth)。由于一个设备只能属于一个 Network Namespace ,所以转移后在这个 Network Namespace 内就看不到这个设备了。
- 其中,veth设备属于可转移设备,而很多其它设备(如lo、vxlan、ppp、bridge等)是不可以转移的。
- veth pair
- veth pair 全称是 Virtual Ethernet Pair,是一个成对的端口,所有从这对端口一 端进入的数据包都将从另一端出来,反之也是一样
- 引入veth pair是为了在不同的 Network Namespace 直接进行通信,利用它可以直接将两个 Network Namespace 连接起来。
- 整个veth的实现非常简单,有兴趣的读者可以参考源代码
drivers/net/veth.c的实现。
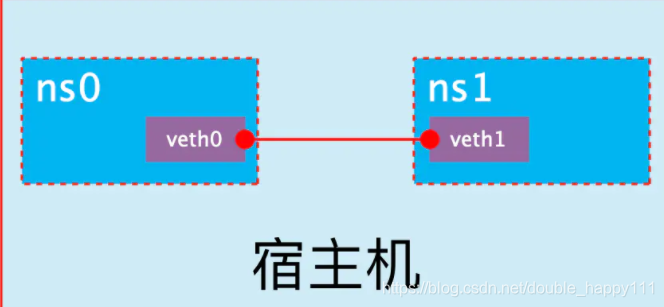
- 创建veth pair
[root@localhost ~]# ip link add type veth
[root@localhost ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:2d:60:55 brd ff:ff:ff:ff:ff:ff
inet 192.168.73.41/24 brd 192.168.73.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::399f:dd76:3eb7:2c5b/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:82:d5:d2 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:82:d5:d2 brd ff:ff:ff:ff:ff:ff
5: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 72:65:8f:0a:3e:f3 brd ff:ff:ff:ff:ff:ff
6: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether e2:42:9c:95:76:ea brd ff:ff:ff:ff:ff:ff
- 可以看到,此时系统中新增了一对veth pair,将veth0和veth1两个虚拟网卡连接了起来,此时这对 veth pair 处于”未启用“状态。
- 如果我们想指定 veth pair 两个端点的名称,可以使用下面的命令:
ip link add vethfoo type veth peer name vethbar
3. 实现network namespace间的通信
- 下面我们利用veth pair实现两个不同的 Network Namespace 之间的通信。刚才我们已经创建了一个名为love的 Network Namespace,下面再创建一个信息Network Namespace,命名为you
[root@localhost ~]# ip netns list
you
love
- 然后我们将veth0加入到love,将veth1加入到you,如下所示:
[root@localhost ~]# ip link set veth0 netns love
[root@localhost ~]# ip link set veth1 netns you
- 然后我们分别为这对veth pair配置上ip地址,并启用它们:
[root@localhost ~]# ip netns exec love ip link set veth0 up
[root@localhost ~]# ip netns exec love ip addr add 192.168.73.51/24 dev veth0
[root@localhost ~]# ip netns exec you ip link set veth1 up
[root@localhost ~]# ip netns exec you ip addr add 192.168.73.52/24 dev veth1
- 查看veth pair的状态
[root@localhost ~]# ip netns exec love ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
5: veth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 72:65:8f:0a:3e:f3 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 192.168.73.51/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::7065:8fff:fe0a:3ef3/64 scope link
valid_lft forever preferred_lft forever
[root@localhost ~]# ip netns exec you ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
6: veth1@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether e2:42:9c:95:76:ea brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.73.52/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::e042:9cff:fe95:76ea/64 scope link
valid_lft forever preferred_lft forever
- 从上面可以看出,我们已经成功启用了这个veth pair,并为每个veth设备分配了对应的ip地址。我们尝试在
ns1中访问ns0中的ip地址:
[root@localhost ~]# ip netns exec you ping -c 3 192.168.73.51
PING 192.168.73.51 (192.168.73.51) 56(84) bytes of data.
64 bytes from 192.168.73.51: icmp_seq=1 ttl=64 time=0.292 ms
64 bytes from 192.168.73.51: icmp_seq=2 ttl=64 time=0.056 ms
64 bytes from 192.168.73.51: icmp_seq=3 ttl=64 time=0.041 ms
--- 192.168.73.51 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.041/0.129/0.292/0.115 ms
4. veth 查看对端
- 一旦将veth pair的peer段放入另一个Network Namespace,我们在当前Namespace中就看不到它了。那么,我们怎么才能知道这个veth pair的对端在哪里呢?
- 可以通过
ethtool工具来查看(当Network Namespace很多时,操作会比较麻烦):
[root@localhost ~]# ip netns exec you ethtool -S veth1
NIC statistics:
peer_ifindex: 5
- 得知另一端的接口设备序列号是5,我们再到另一个命名空间中查看序列号5代表什么设备:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
5: veth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 72:65:8f:0a:3e:f3 brd ff:ff:ff:ff:ff:ff link-netnsid 1
5. 网桥
- veth pair打破了 Network Namespace 的限制,实现了不同 Network Namespace 之间的通信。但veth pair有一个明显的缺陷,就是只能实现两个网络接口之间的通信。
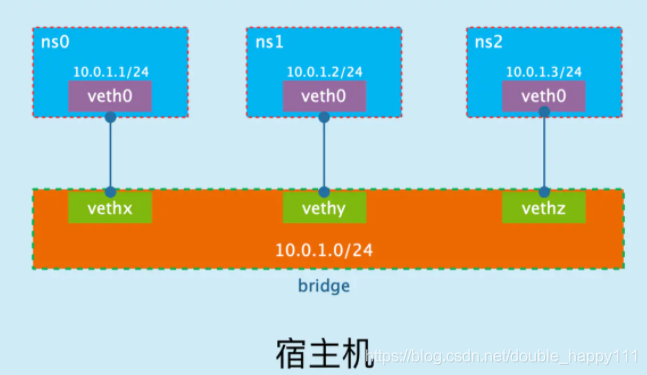
- 如果我们想实现多个网络接口之间的通信,就可以使用下面介绍的网桥(Bridge)技术。
- 简单来说,网桥就是把一台机器上的若干个网络接口“连接”起来。其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去。以使得网口之间的报文能够互相转发。
5.1 网桥的工作原理
- 网桥对报文的转发基于MAC地址。网桥能够解析收发的报文,读取目标MAC地址的信息,和自己记录的MAC表结合,来决策报文的转发目标网口。
- 为了实现这些功能,网桥会学习源MAC地址,在转发报文时,网桥只需要向特定的网口进行转发,从而避免不必要的网络交互。
- 如果它遇到一个自己从未学习到的地址,就无法知道这个报文应该向哪个网口转发,就将报文广播给所有的网口(报文来源的网口除外)。
5.2 网桥的实现
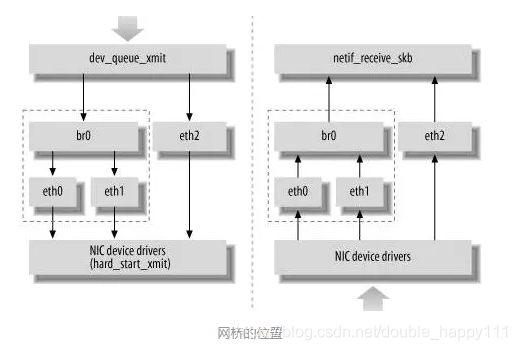
- Linux内核是通过一个虚拟的网桥设备(Net Device)来实现桥接的。这个虚拟设备可以绑定若干个以太网接口设备,从而将它们桥接起来。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X3tEDe5h-1587100512783)(H:\markdown图片\4.png)]
- 对于网络协议栈的上层来说,只看得到 br0,上层协议栈需要发送的报文被送到 br0,网桥设备的处理代码判断报文该被转发到 eth0 还是 eth1,或者两者皆转发;反过来,从eth0 或 eth1 接收到的报文被提交给网桥的处理代码,在这里会判断报文应该被转发、丢弃还是提交到协议栈上层。
- 而有时eth0、eth1 也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收,从而绕过网桥。
5.3 brctl
- 和网桥有关的操作可以使用命令 brctl,这个命令来自 bridge-utils 这个包。
- 创建网桥
# 创建网桥
brctl addbr br0
- 删除网桥
# 删除网桥
brctl delbr br0
- 绑定网口
- 建立一个逻辑网段之后,我们还需要为这个网段分配特定的端口。在Linux 中,一个端口实际上就是一个物理或虚拟网卡。而每个网卡的名称则分别为eth0 ,eth1 ,eth2 。我们需要把每个网卡一一和br0 这个网段联系起来,作为br0 中的一个端口。
# 让eth0 成为br0 的一个端口
brctl addif br0 eth0
# 让eth1 成为br0 的一个端口
brctl addif br0 eth1
# 让eth2 成为br0 的一个端口
brctl addif br0 eth2
6. iptables/netfilter
- iptables是Linux实现的软件防火墙,用户可以通过iptables设置请求准入和拒绝规则,从而保护系统的安全。
- 我们也可以把iptables理解成一个客户端代理,用户通过iptables这个代理,将用户安全设定执行到对应的安全框架中,这个“安全框架”才是真正的防火墙,这个框架的名字叫
netfilter。 - iptables其实是一个命令行工具,位于用户空间。
- iptables/netfilter(以下简称iptables)组成了Linux平台下的包过滤防火墙,可以完成封包过滤、封包重定向和网络地址转换(NAT)等功能。
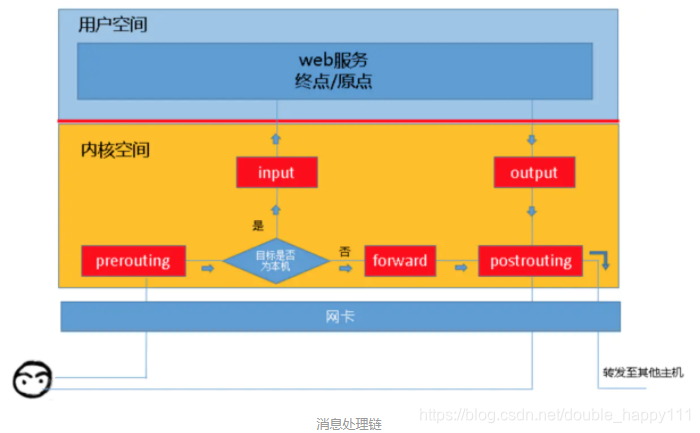
7. 消息处理
- iptables不仅要处理本机接收到的消息,也要处理本机发出的消息。这些消息需要经过一系列的”关卡“才能被本机应用层接收,或者从本机发出,每个”关卡“担负着不同的工作。这里的”关卡“被称为”链“。
INPUT:进来的数据包应用此规则链中的策规则;OUTPUT:外出的数据包应用此规则链中的规则;FORWARD:转发数据包时应用此规则链中的规则;PREROUTING:对数据包作路由选择前应用此链中的规则(所有的数据包进来的时侯都先由这个链处理);POSTROUTING:对数据包作路由选择后应用此链中的规则(所有的数据包出来的时侯都先由这个链处理);
8. 规则表
-
从上面我们知道,iptables是按照规则来办事的,这些规则就是网络管理员预定义的条件。规则一般的定义为:如果数据包头符合这样的条件,就这样处理“。这些规则并不是严格按照添加顺序排列在一张规则表中,而是按照功能进行分类,存储在不同的表中,每个表存储一类规则:
-
filter
- 主要用来过滤数据,用来控制让哪些数据可以通过,哪些数据不能通过,它是最常用的表。
-
nat
- 用来处理网络地址转换的,控制要不要进行地址转换,以及怎样修改源地址或目的地址,从而影响数据包的路由,达到连通的目的。
-
mangle
- 主要用来修改IP数据包头,比如修改TTL值,同时也用于给数据包添加一些标记,从而便于后续其它模块对数据包进行处理(这里的添加标记是指往内核skb结构中添加标记,而不是往真正的IP数据包上加东西)。
-
raw
- 在Netfilter里面有一个叫做链接跟踪的功能,主要用来追踪所有的连接,而raw表里的rule的功能是给数据包打标记,从而控制哪些数据包不做链接跟踪处理,从而提高性能;
优先级最高。
- 在Netfilter里面有一个叫做链接跟踪的功能,主要用来追踪所有的连接,而raw表里的rule的功能是给数据包打标记,从而控制哪些数据包不做链接跟踪处理,从而提高性能;
9. 表和链的关系
- 表和链共同完成了iptables对数据包的处理。但并不是每个链都包含所有类型的表,所以,有些链是天生不具备某些功能的。就像我们去车站乘车的时候,”关卡A“只负责检查身份证,”B关卡”只负责检查行李,而“C关卡”功能比较齐全,即负责检查身份证,又负责检查行李。