文章出处: http://blog.csdn.net/sdksdk0/article/details/53634332
作者:朱培 ID:sdksdk0
--------------------------------------------------------------------------------------------
最近十几天在做一个博客系统,因为域名服务器都闲置已久,于是乎决定合理利用起来,做个网站。系统整体架构采用分布式的系统,也是当今很多企业都在用的,基于restful风格的一套系统。从父工程开始blog-parent.这是一个pom工程,主要用来放置pom.xml文件的,这个包含了整个项目所有依赖的jar包。然后是blog-common,这个存放项目中使用到的一些工具类,也是一个pom工程。然后是blog-manager工程,这个主要是后台,包括用户操作以及管理员操作,这个项目还有一个积分商城的功能,所以商城的后台我也是放到这个manager工程里面的。这个manager是一个pom工程,然后下面的mapper和pojo以及service和web都是一个maven module.然后除了blog-manager-web是一个war之外,剩下的三个都是jar工程。
然后前台是blog-portal,还有就是rest、search、sso、order。rest其实是给积分商城用的。search使用的是一个solr集群。因为服务器性能原因,所以我搭建的是三台tomcat的solr集群,依托zookeeper来进行管理。
sso就是单点登录系统,主要给整个系统提供登录服务的。order系统主要是给积分商城提供订单服务的。
下面来说详细内容:
一、系统后台:
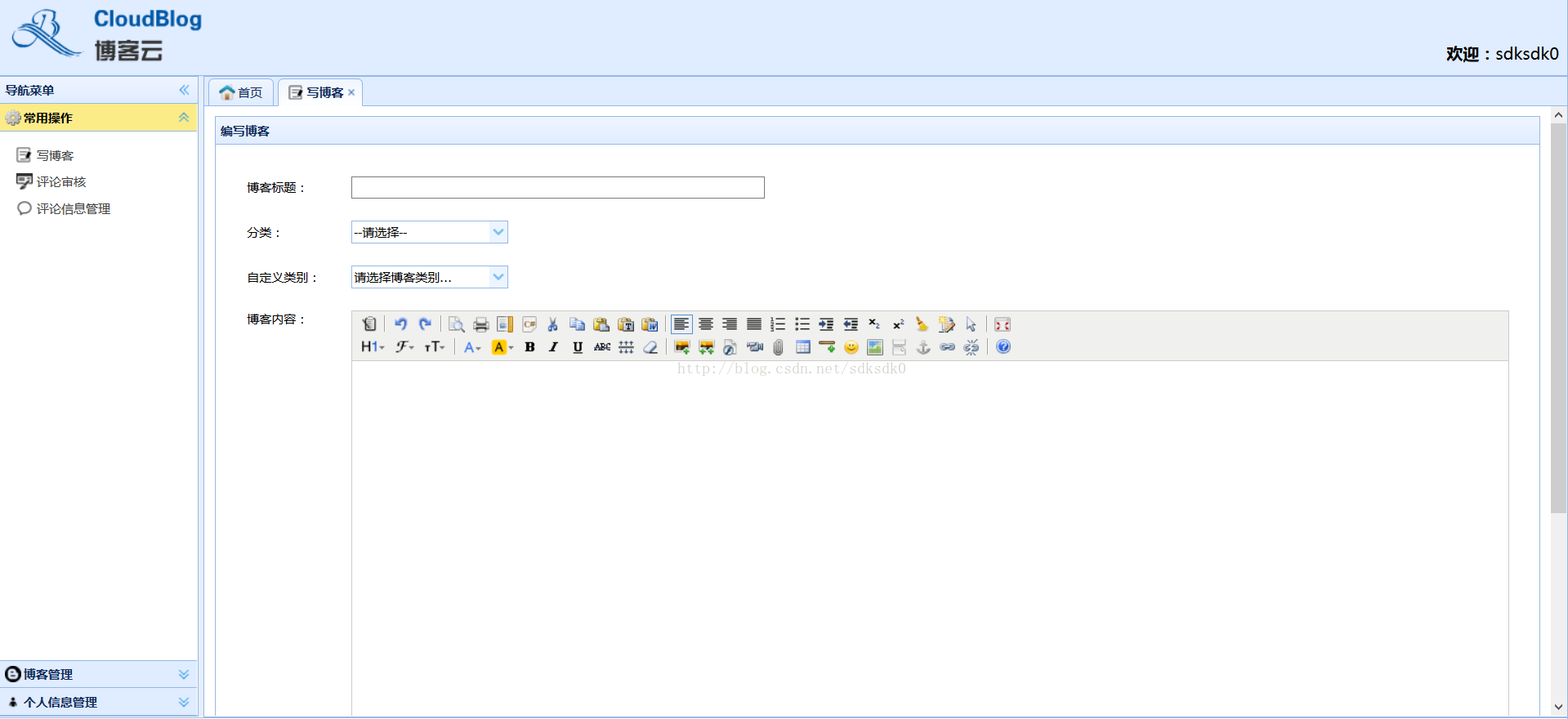
后台是一个easyui的界面,非常简约,写文章的富文本编辑器我采用的是kindeditor。这个编辑器性能还是不错的,其实使用百度的ueditor富文本编辑器效果也不错,只是因为我的springmvc拦截配置的config一直不成功,于是我就换了其他的编辑器。数据提交采用的post提交。
- if(title==null || title==''){
- alert("请输入标题!");
- }else if(typeId==null || typeId==''){
- alert("请选择博客类别!");
- }else if(blogTypeId==null || blogTypeId==''){
- alert("请选择博客类别!");
- }else if(content==null || content==''){
- alert("请输入内容!");
- }else{
- $.post("/mg/user/blog/save",{'username':username,'title':title,'typeid':typeId,'blogtypeid':blogTypeId,'content':content,'summary':summary,'contentNoTag':contentNoTag,'keyword':keyWord},function(result){
- if(result.success){
- alert("博客发布成功!");
- resetValue();
- }else{
- alert("博客发布失败!");
- }
- },"json");
- }
- var content=itemAddEditor.html();
- itemAddEditor.sync();
因为这里是加入了lucene全文检索功能,所以在添加或者修改文章的时候,都需要进行索引字段处理,因为富文本编辑器存到数据库中的内容都是带html标签格式的,但是我检索肯定是不需要这些标签的,所以使用下面的方法,来把这个html标签去掉,放到contentNoTag字段,用于检索。而content就是带html标签的需要存放在数据库的内容。
- var dd=content.replace(/<\/?.+?>/g,"");
- var contentNoTag=dd.replace(/(^\s*)|(\s*$)/g,"");//dds为得到后的内容
然后就是一个列表的查询。因为这是一个多用户的系统,所以每个用户查看的都是自己的博客信息,所以在查询的时候需要加上用户名。
对于添加博客的时候需要的一个lucene操作。
- /**//**
- * 获取IndexWriter实例
- * @return
- * @throws Exception
- *//*
- */ private IndexWriter getWriter()throws Exception{
- dir=FSDirectory.open(Paths.get("/home/tf/work/data/lucene1/"));
- //dir=FSDirectory.open(Paths.get("c:\\lucene"));
- SmartChineseAnalyzer analyzer=new SmartChineseAnalyzer();
- IndexWriterConfig iwc=new IndexWriterConfig(analyzer);
- IndexWriter writer = null;
- try {
- writer = new IndexWriter(dir, iwc);
- } catch (Exception e) {
- writer.rollback();
- e.printStackTrace();
- }
- return writer;
- }
- /* *//**
- * 添加博客索引
- * @param blog
- *//*
- */ public void addIndex(UBlog blog)throws Exception{
- IndexWriter writer=getWriter();
- Document doc=new Document();
- doc.add(new StringField("id",String.valueOf(blog.getBlogid()),Field.Store.YES));
- doc.add(new StringField("username",String.valueOf(blog.getUsername()),Field.Store.YES));
- doc.add(new TextField("title",blog.getTitle(),Field.Store.YES));
- doc.add(new StringField("releaseDate",DateUtil.formatDate(new Date(), "yyyy-MM-dd"),Field.Store.YES));
- doc.add(new TextField("content",blog.getContentNoTag(),Field.Store.YES));
- writer.addDocument(doc);
- writer.close();
- }
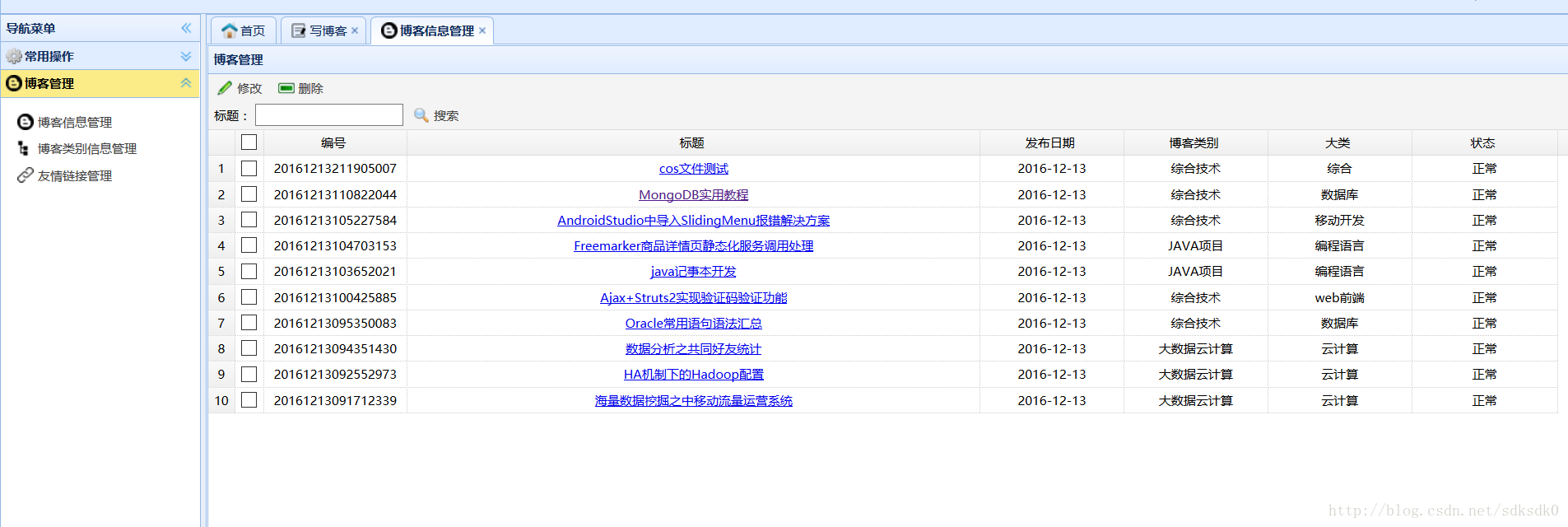
而管理员就可以查看所有用户的文章,以及可以进行冻结解冻操作。
后台管理员这里还有一个积分商城,主要是用户发表博客之后又积分,积分可以兑换K币,然后K币可以兑换这个积分商城中的东西。这个商品添加之后,是不能直接在前台进行查询的,因为我对于这个商品时启用了solr搜索服务的,在我的blog-search工程中做了一个定时任务,在每天凌晨两点进行数据导入操作,系统导入完成之后,就可以在前台查看到添加的这些商品了。
- /**
- * 导入商品数据库到索引库
- */
- @Scheduled(cron = "0 0 2 * * ?") //每天凌晨两点执行
- @RequestMapping("/import")
- public void importAllItems() {
- System.out.println("开始执行");
- itemService.importAllItems();
- System.out.println("执行结束");
- }
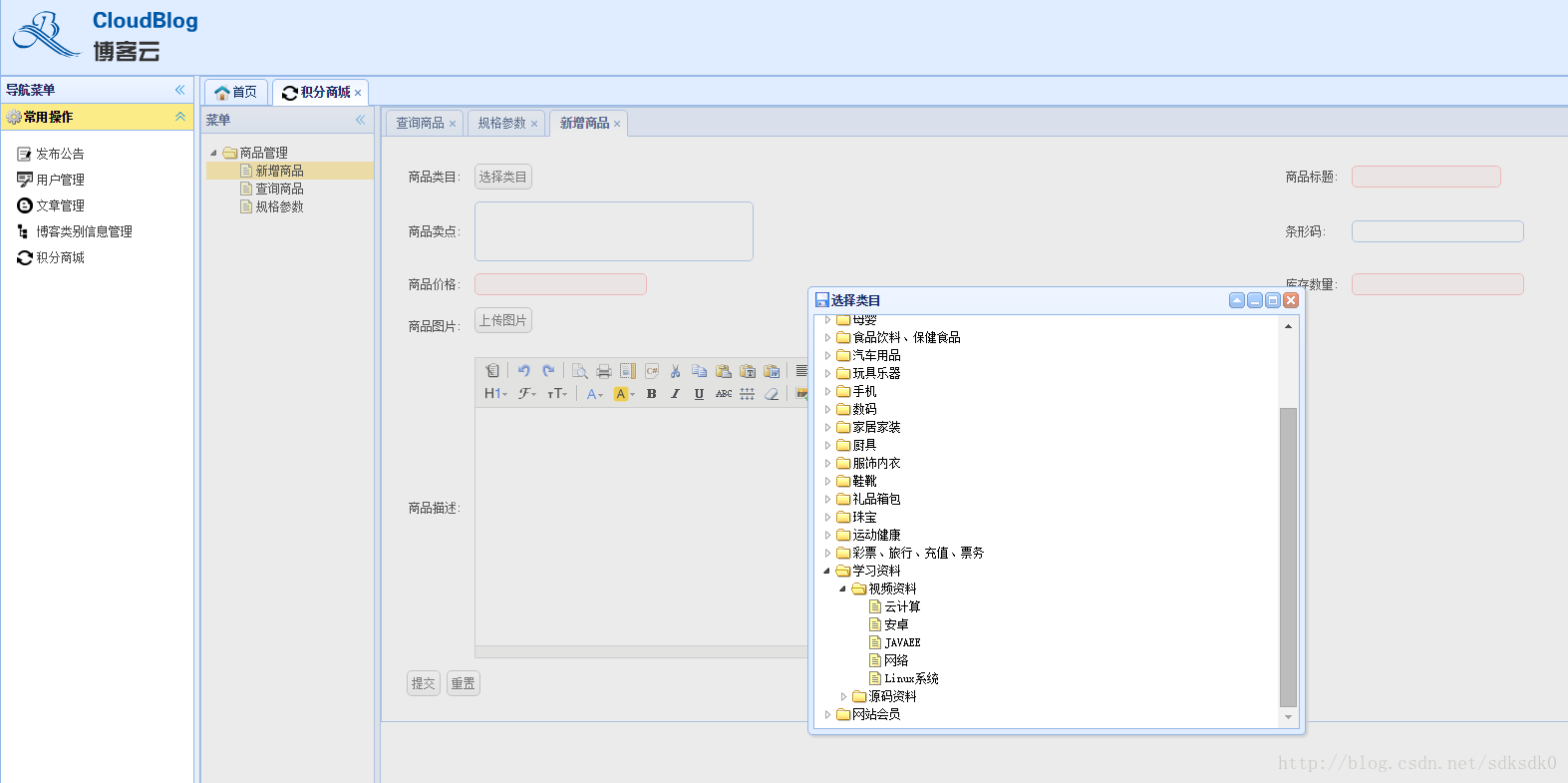
关于整个后台来说,界面非常简约,需要的功能还是基本上齐全的。因为是分布式系统的,所以我上线的时候都是分开上线的,在上线后台之后,这个规格参数和商品列表查询一个不能及时刷新$("#itemList").datagrid("reload");我开始以为是数据量太大导致刷新慢,后来发现并不是。例如我操作了删除,其实数据库中的数据已经删除了,但是这个datagrid却没有反应,查看状态码返回的是304.然后我想到了我后台是启动了CDN缓存加速的,所以我就又跑去看CDN的配置,然后就发现问题了,于是我把列表查询的/mg/item目录的刷新时间设置为0,这样就可以及时刷新,不再是一直在缓存。这样这个问题就解决了。

通过这个事情我知道,在本地的localhost操作和上线真的是不同的。在上线过程还遇到了很多在本地操作没有发生的事情,在本地都没有什么问题,一到云服务器上部署,马上问题就来了。哎!真是个磨人的小妖精。
二、前台
前台的话基本上也就这样了,因为审美水平问题,只能做到这个样子了,毕竟没有美工,毕竟我是做系统架构和数据处理数据分析的,哎,看来还是有不足之处啊。大家就将就着看吧,哈哈。 http://www.tianfang1314.cn/
前台的这个博客文章我都加入到了redis缓存中,所以访问速度理论上还是提升了的。前台页面在CDN缓存设置的是一分钟,所以后台增删改什么的理论上是要过一分钟之后,前台才会更新的。
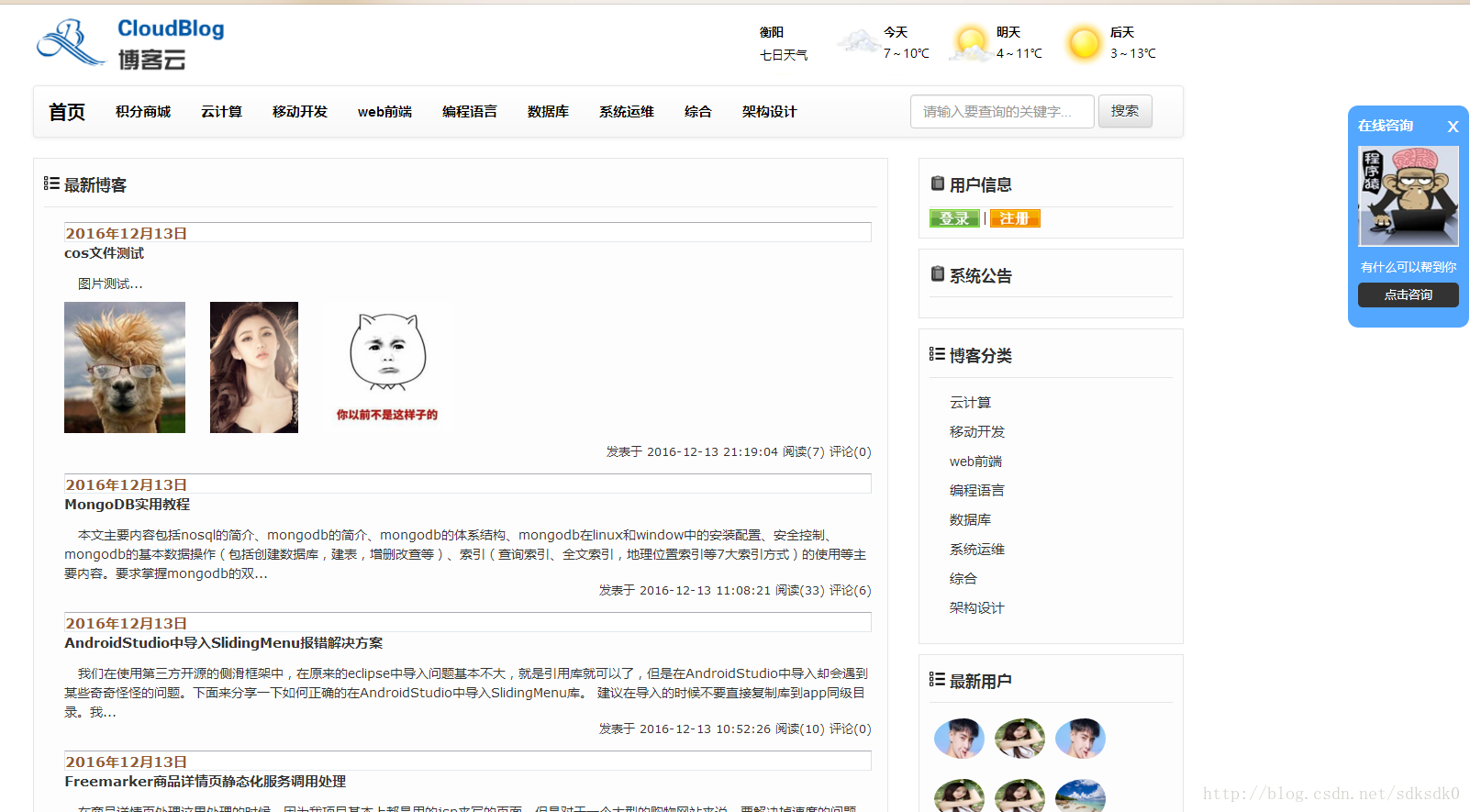
关于前台的lucene搜索就是:
- /**//**
- * 查询博客信息
- * @param q 查询关键字
- * @return
- * @throws Exception
- *//*
- */ public List<UBlog> searchBlog(String q)throws Exception{
- dir=FSDirectory.open(Paths.get("/home/tf/work/data/lucene1/"));
- IndexReader reader = DirectoryReader.open(dir);
- IndexSearcher is=new IndexSearcher(reader);
- BooleanQuery.Builder booleanQuery = new BooleanQuery.Builder();
- SmartChineseAnalyzer analyzer=new SmartChineseAnalyzer();
- QueryParser parser=new QueryParser("title",analyzer);
- Query query=parser.parse(q);
- QueryParser parser2=new QueryParser("content",analyzer);
- Query query2=parser2.parse(q);
- booleanQuery.add(query,BooleanClause.Occur.SHOULD);
- booleanQuery.add(query2,BooleanClause.Occur.SHOULD);
- TopDocs hits=is.search(booleanQuery.build(), 100);
- QueryScorer scorer=new QueryScorer(query);
- Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);
- SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("<b><font color='red'>","</font></b>");
- Highlighter highlighter=new Highlighter(simpleHTMLFormatter, scorer);
- highlighter.setTextFragmenter(fragmenter);
- List<UBlog> blogList=new LinkedList<UBlog>();
- for(ScoreDoc scoreDoc:hits.scoreDocs){
- Document doc=is.doc(scoreDoc.doc);
- UBlog blog=new UBlog();
- blog.setBlogid(doc.get(("id")));
- blog.setUsername(doc.get("username"));
- blog.setReleaseDateStr(doc.get(("releaseDate")));
- String title=doc.get("title");
- String content=StringEscapeUtils.escapeHtml(doc.get("content"));
- if(title!=null){
- TokenStream tokenStream = analyzer.tokenStream("title", new StringReader(title));
- String hTitle=highlighter.getBestFragment(tokenStream, title);
- if(StringUtil.isEmpty(hTitle)){
- blog.setTitle(title);
- }else{
- blog.setTitle(hTitle);
- }
- }
- if(content!=null){
- TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(content));
- String hContent=highlighter.getBestFragment(tokenStream, content);
- if(StringUtil.isEmpty(hContent)){
- if(content.length()<=200){
- blog.setContent(content);
- }else{
- blog.setContent(content.substring(0, 200));
- }
- }else{
- blog.setContent(hContent);
- }
- }
- blogList.add(blog);
- }
- return blogList;
- }
效果还是不错的,大家可以去试一下,文末提供访问网址。说到这个文章啊,遇到最头疼的问题就是编码问题了,因为页面展示是一种,然后我mysql数据库的编码,还有redis中存放的文章的编码。添加缓存的时候又各种进行转换。都快转晕了,哈哈,当然最终还是解决了,挺开心的。
- blog.setContent(new String(blog.getContent().getBytes("iso-8859-1"),
- "utf-8"));