
准备工作
作业五是机器翻译,需要助教代码,运行代码过程中保持联网可以自动下载数据集,已经有数据集的情况可关闭助教代码中的下载数据部分。关注本公众号,可获得代码和数据集(文末有方法)。
提交地址
这次作业在NTU上面提交,需要做一个survey才能提交,不过我当时做了也无法提交,原因未知,所以该作业没法给出提交分数了,关于作业有想讨论的可进QQ群:156013866。
数据预处理流程梳理
这次作业的数据预处理部分较多,这里梳理下预处理过程,数据集有两个压缩包:ted2020.tgz(包含raw.en, raw.zh两个文件),test.tgz(包含test.en, test.zh两个文件)。
第一步将解压后的文件全部放到一层目录中,目录位置是:"DATA/rawdata/ted2020",并将raw.en,raw.zh,test.en,test.zh分别改名称为train_dev.raw.en, train_dev.raw.zh, test.raw.en, test.raw.zh。
第二步是数据清洗操作,去掉或者替换一些特殊字符,例如符号单破折号’—‘会被删除,清洗后的文件名称是,train_dev.raw.clean.en, train_dev.raw.clean.zh, test.raw.clean.en, test.raw.clean.zh。
第三步是划分训练集和验证集,train_dev.raw.clean.en和train_dev.clean.zh被分成train.clean.en, valid.clean.en和train.clean.zh, train.clean.zh。
第四步是分词,使用sentencepiece中的spm对训练集和验证集进行分词建模,模型名称是spm8000.model,同时产生词汇库spm8000.vocab,使用模型对训练集、验证集、以及测试集进行分词处理,得到文件train.en, train.zh, valid.en, valid.zh, test.en, test.zh。
第五步是文件二进制化,该过程使用fairseq库,这个库对于序列数据的处理很方便。运行后最终生成了一系列的文件,文件目录是"DATA/data_bin/ted2020",这下面有18个文件,其中的一些二进制文件才是我们最终想要的训练数据。
数据的预处理流程基本不需要修改,如果在个人电脑上训练,跑一遍程序后,之后可直接从数据预处理结束开始跑,能节省不少时间。
Simple Baseline (score>14.58)
方法:直接运行助教代码。
Medium Baseline (score>18.04)
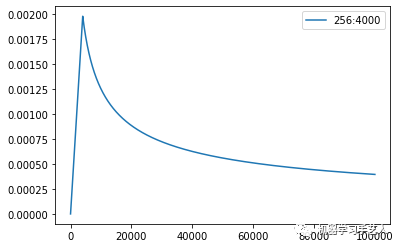
方法:修改get_rate函数+epoch改为30。lr随step变化形状如下图,运行后loss有所下降。
def get_rate(d_model, step_num, warmup_step):# TODO: Change lr from constant to the equation shown above#lr = 0.001lr = (d_model**(-0.5)) * min(step_num**(-0.5), step_num*(warmup_step**(-1.5)))return lr
Strong Baseline (score>25.20)
方法:修改get_rate函数+epoch改为30+transformer架构。与medium baseline相比,将RNN架构改为Transoformer架构,模型的参数改变采用了Attention is all you need论文中的table3 base模型进行适当修改,因为我们的数据量不够,所以相对论文中的模型,降低了维度,实现方法如下。运行后loss相比medium baseline有所下降。
# config里面savedir文件夹位置需要改变,否则无法loadcheckpoint的modelconfig = Namespace(datadir = "./DATA/data-bin/ted2020",#savedir = "./checkpoints/rnn",savedir = "./checkpoints/transformer",
#启用transoformer架构#encoder = RNNEncoder(args, src_dict, encoder_embed_tokens)#decoder = RNNDecoder(args, tgt_dict, decoder_embed_tokens)encoder = TransformerEncoder(args, src_dict, encoder_embed_tokensdecoder = TransformerDecoder(args, tgt_dict, decoder_embed_tokens)
#修改模型参数并启用add_transformer_args函数#模型根据attention is all you need文章中table3 base适当修改arch_args = Namespace(encoder_embed_dim=256,encoder_ffn_embed_dim=1024,encoder_layers=4,decoder_embed_dim=256,decoder_ffn_embed_dim=1024,decoder_layers=4,share_decoder_input_output_embed=True,dropout=0.15,)# HINT: these patches on parameters for Transformerdef add_transformer_args(args):args.encoder_attention_heads=4args.encoder_normalize_before=Trueargs.decoder_attention_heads=4args.decoder_normalize_before=Trueargs.activation_fn="relu"args.max_source_positions=1024args.max_target_positions=1024# patches on default parameters for Transformer (those not set above)from fairseq.models.transformer import base_architecturebase_architecture(arch_args)add_transformer_args(arch_args)
Boss Baseline (acc>29.13)
方法:先训练中文到英文的反向模型+下载中文数据+利用反向模型将中文翻译为英文+中英文对应+数据合并+训练。时间太长了,这个没具体的跑,等我电脑升级一定跑一遍,坐等显卡崩盘。

Report 1
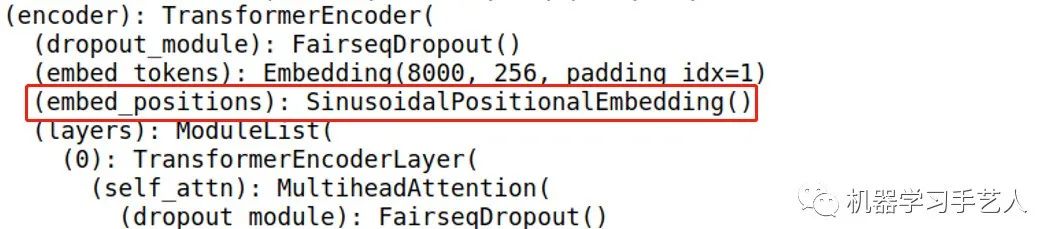
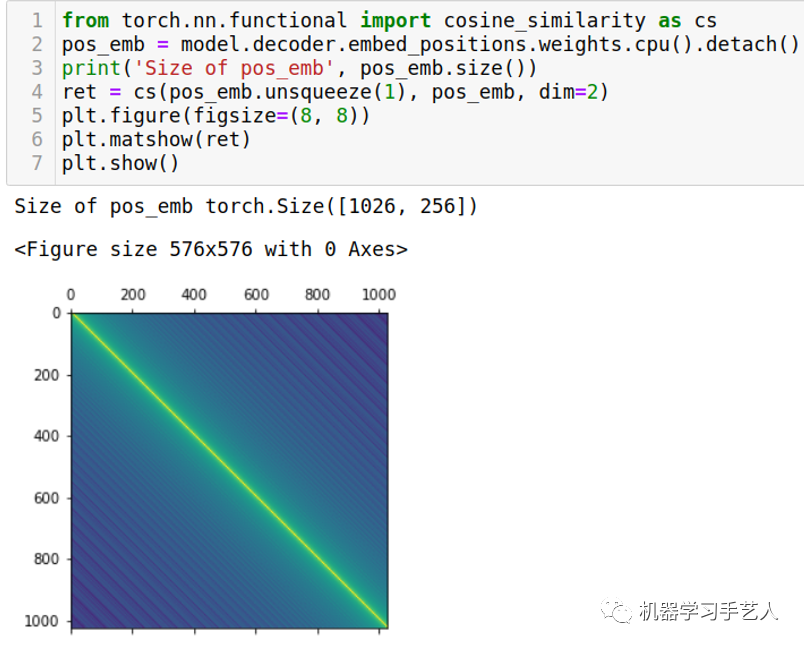
作业中另外要求了两个report,第一个是关于Postional Embedding以及可视化。在strong baseline任务中,可以看到encoder下embed_positions层,该层即是positional embedding层,model.decoder.embed_positions.weights就是positional embedding值,使用pytorch自带的cosine similarity,辅助torch tensor的广播应用,可以得到similarity矩阵,最后用plt.matshow画出该矩阵,可以看出对角线上的相似度最强(对角线是求自身的相似度,都是1),并且相似性是对角线对称的(对称性)且距离对角线同等距离的位置相似度一样(平移不变性)。
Report 2
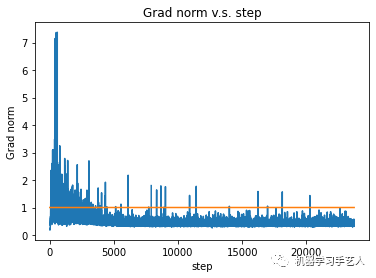
第二个report是关于Clipping Gradient Norm以及可视化。这个工作在meidium baseline版本中实现,我在函数train_one_epoch之前定义了一个列表全局变量gnorms,并在函数内部将gnorm的值放到gnorms中,等训练结束,对gnorms做可视化,gnorms和直线y=1.0的交界处即为clipping生效的地方。注意gnorm是函数nn.utils.clip_grad_norm_的返回值,该值为model.parameters()的L_p norm,p的值默认为2,可通过参数调节。
gnorms = []def train_one_epoch(epoch_itr, ...):......gnorm = nn.utils.clip_grad_norm_(model.parameters(), config.clip_norm)# grad norm clipping prevents gradient explodinggnorms.append(gnorm.cpu().item())......
plt.plot(range(1, len(gnorms)+1), gnorms)plt.plot(range(1, len(gnorms)+1), [config.clip_norm]*len(gnorms), "-")plt.title('Grad norm v.s. step')plt.xlabel("step")plt.ylabel("Grad norm")plt.show()
作业五答案获得方式:
-
关注微信公众号 “机器学习手艺人”
-
后台回复关键词:202205