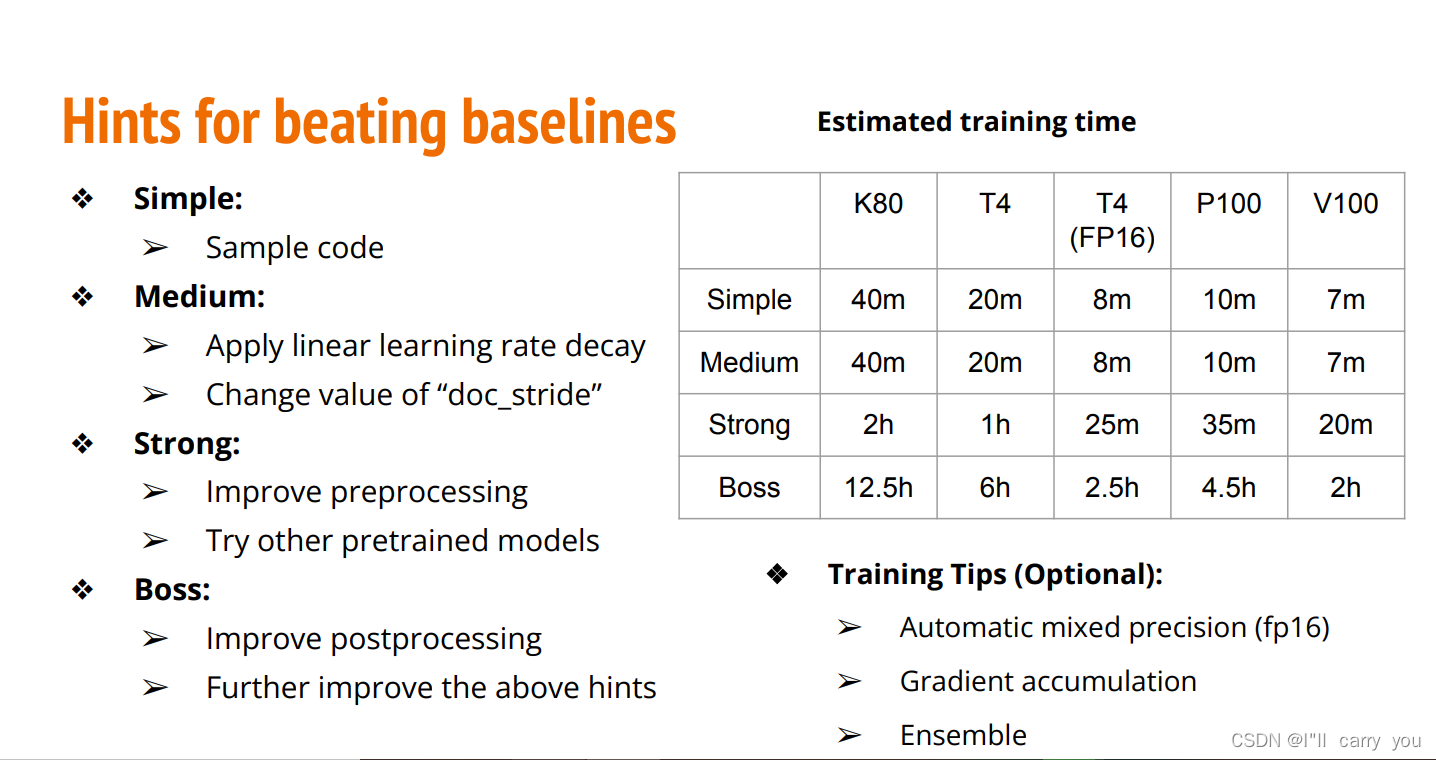
评分标准
实验记录
medium
Hyper parameter: max_question 40/ max_paragraph 350/ doc_stride 300
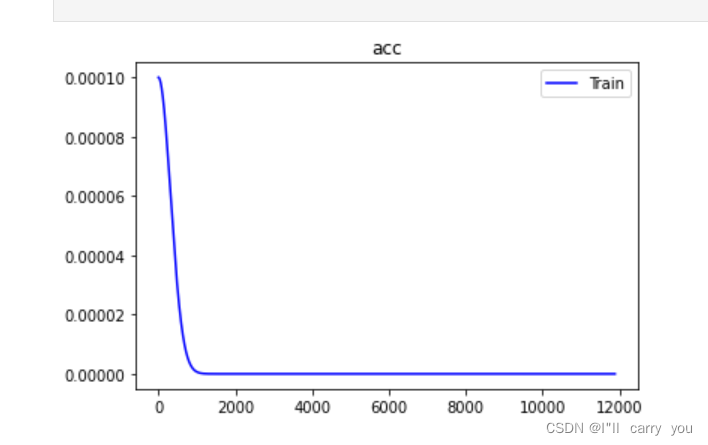
##### TODO: Apply linear learning rate decay #####
learning_rate = learning_rate * (1.0 / (1.0 + 0.00001 * step))
绘制的lr曲线:
训练技巧
fp16_training

官方示例:

Gradient accumulation
from: https://kozodoi.me/python/deep%20learning/pytorch/tutorial/2021/02/19/gradient-accumulation.html
# batch accumulation parameter
accum_iter = 4
# loop through enumaretad batches
for batch_idx, (inputs, labels) in enumerate(data_loader):
# extract inputs and labels
inputs = inputs.to(device)
labels = labels.to(device)
# passes and weights update
with torch.set_grad_enabled(True):
# forward pass
preds = model(inputs)
loss = criterion(preds, labels)
# normalize loss to account for batch accumulation
loss = loss / accum_iter
# backward pass
loss.backward()
# weights update
if ((batch_idx + 1) % accum_iter == 0) or (batch_idx + 1 == len(data_loader)):
optimizer.step()
optimizer.zero_grad()
收获:
训练得更快:fp16_training
更大的batch:Gradient accumulation
线性学习率下降:
from transformers import get_linear_schedule_with_warmup # 在https://huggingface.co/transformers/下,不在pytorch官网
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps= 0, # Default value
num_training_steps=total_steps) # 把num_warmup_steps=0就可以实现线性下降
又见到Hugging Face这个库:https://huggingface.co/