
准备工作
作业九是Explainable AI(模型的可解释性),需要助教代码和数据集,运行代码过程中保持联网可以自动下载数据集,已经有数据集的情况可关闭助教代码中的下载数据部分。关注本公众号,可获得代码和数据集(文末有方法)。
CNN的可解释性
该部分使用了5种方法:Lime,Saliency Map,Smooth Grad,Filter Visualization,Integrated Gradients。我们以下逐个介绍。
-
Lime
Lime是Local Interpretable Model Agnostic Explanations的缩写,主要方法是先训练一个线性模型,模型的输入为切块的图片,将其训练为输出与CNN模型类似,然后通过线性模型的权重来判断图片的哪一个位置比较重要。LIME训练后效果图如下,食物的位置确实是被标记了,不过标记的并不全。
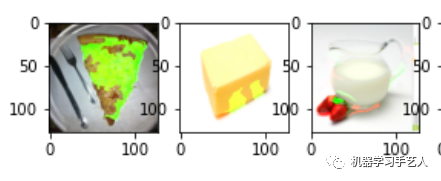
-
Saliency Map
该方法对图片的每个像素求导,根据导数的绝对值大小来判断像素的重要性。具体做法是构造loss函数,输入是图片,输出是模型输入与gound truth的差异,然后对loss函数的输入(图片)求导。Saliency Map效果对比图如下,食物所在的位置亮度是高的。


-
Smooth Grad
该方法是saliency map的进阶版,通过对图片加入noise得到一系列的图片,对每个图片算saliency map后作平均。效果图如下,看起来结果更好了些。

-
Filter Visualization
该部分可视化包括两个类型,一个是filter activation:观察图片的哪些位置会activate该filter,一个是filter visualization:什么样的图片能最大程度的activate该filter。下面两图是模型第六层第零个filter的activation图和visualization图,作业中visualization图的初始是从原图开始的,所以效果看起来还不错,在其他书本里面,初始化可能是从空白图开始的,最终看到的图类似于有规律的杂讯,注意这个区别。
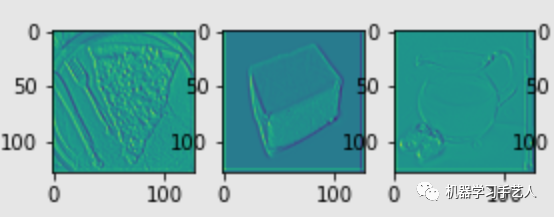
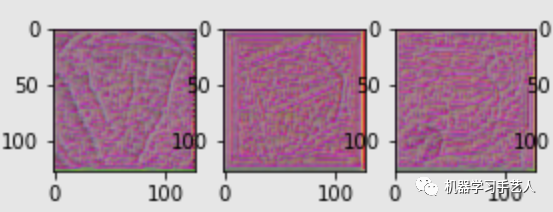
-
Integrated Gradients(IG)
IG是在图片和空白图片之间做线性插值产生多个图片,然后通过图片的模型输出对图片求导(saliency map是loss函数求导,这两者的求导函数不一样),最后将导数的结果进行平均加权。效果图对比图如下,看起来效果一般,优点是形状勾勒的还可以。

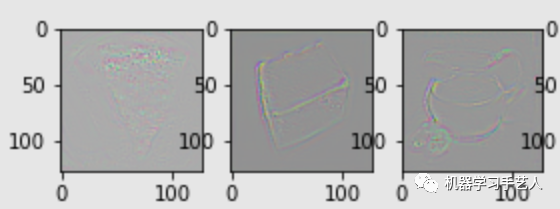
Bert的可解释性
该部分使用了3种方法:Attention Visualization,Embedding Visualization,Embedding Analysis,我们逐个介绍。
-
Attention Visualization
该部分是通过对bert可视化网站的使用来观察attention的变换。网址为:https://exbert.net/exBERT.html
-
Embedding Visualizaiton
作业中有3个阅读理解,每一个包括context, question和answer三部分。学生可以通过修改QUESTION参数来决定看哪一个问题。这里我选择QUESTION=1,该阅读理解信息如下。
context:"Nikola Tesla (Serbian Cyrillic: Никола Тесла; 10 July 1856 – 7 January 1943) was a Serbian American inventor, electrical engineer, mechanical engineer, physicist, and futurist best known for his contributions to the design of the modern alternating current (AC) electricity supply system."
questions: "In what year was Nikola Tesla born?"
answers: "1856"
然后我们使用HW7的bert模型生成context中单词的embedding(一共12层,单词维度是768),并使用PCA工具将embedding变为2维,然后对每个单词的2维信息可视化。如下以第1,6,12层为例子看可视化结果,发现第12层中answer对应的单词已经远离其他单词。
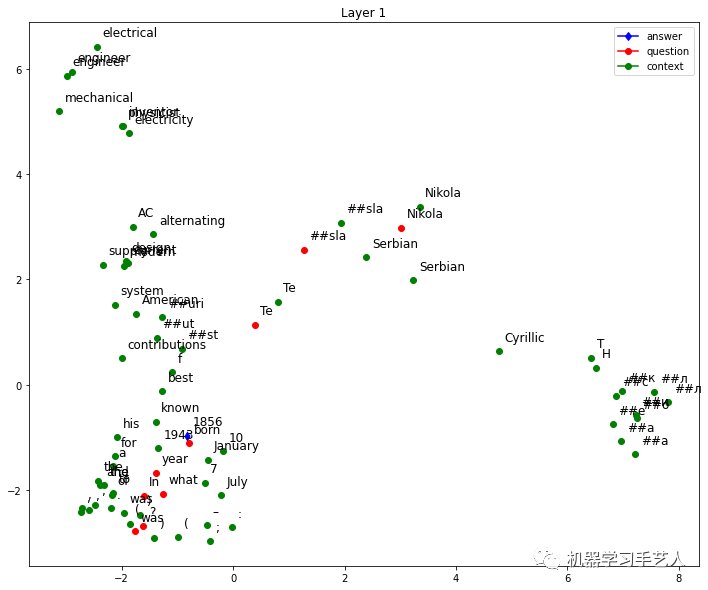
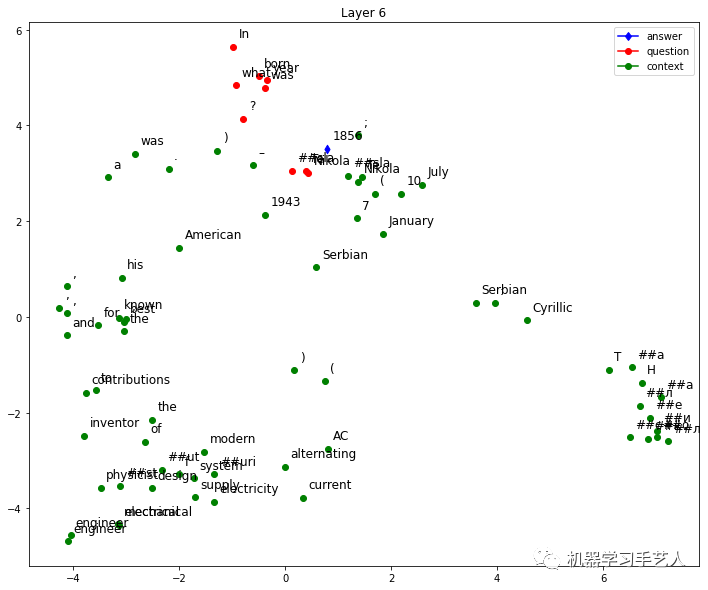
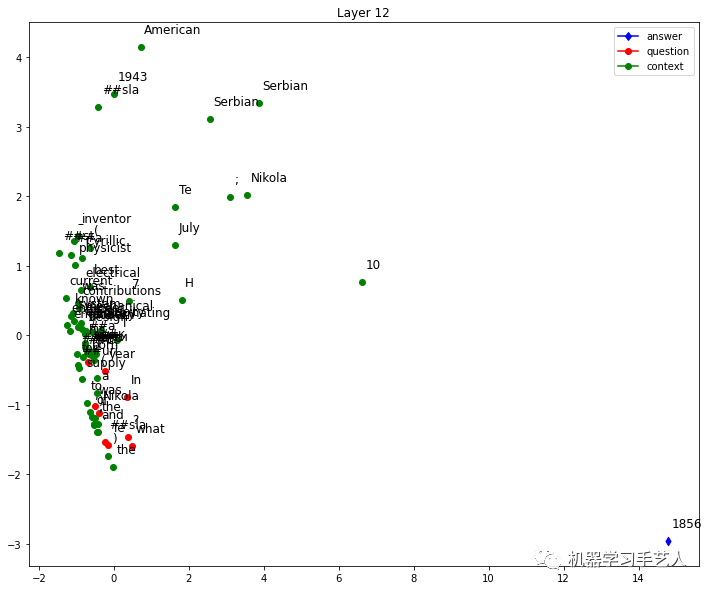
-
Embedding Analysis
这部分主要观察bert针对 ‘苹果’在不同语境下的意义区分(这个是bert与传统embedding的不同,传统embedding不考虑上下文信息,同样的单词无论在哪里都是一样的embedding)。这部分作业学生需要完成eucliden_distance和cosin_similarity函数,来判断两个embedding的相似性,这里我使用了euclidean_distance,该值越小说明2者越相似。最后得到的结果如下图,上面5个句子描述的是水果苹果,后面5个句子是苹果公司,可以看出,二者类内差别小,类间差别大,说明bert能分辨不同语境下‘苹果’的区别。
def l2_norm(a):return (a**2).sum()**0.5def euclidean_distance(a, b):return l2_norm(a - b)def cosine_similarity(a, b): return (a*b).sum()/(l2_norm(a)*l2_norm(b) + 1e-8)
作业九答案获得方式:
-
关注微信公众号 “机器学习手艺人”
-
后台回复关键词:202209