这是我去年选修数据科学时候的作业四,当时是肖若秀老师教的,但听说我们这届之后计科和物联信安一个难度授课了这篇文章可能也就只是自己记录帮不上学弟学妹了,但当时我上数据科学时候肖老师不签到老好了最后四个作业完成之后就有个还不错的分数虽然不出国选修课分数也无所谓就是了。
前文链接:
目录
一、作业描述
本次作业旨在通过对手写数字图像进行分析,得到识别的数字,主要考察学生对图像预处理、神经网络或相关机器学习算法的理解和应用。
具体要求:
1.对给定的手写字体训练集(8000张图片)进行预处理,统一处理为28*28像素,单通道8位灰度(0-255)的图像格式,编写代码将原始数据转为可训练数据。
2.对可训练的手写字体图像数据,进行合理的训练集和验证集划分,建立一个识别模型(模型类型不限,可以是神经网络、SVM、决策树等之一或集成)
3.选定合理的评价指标分析模型性能。
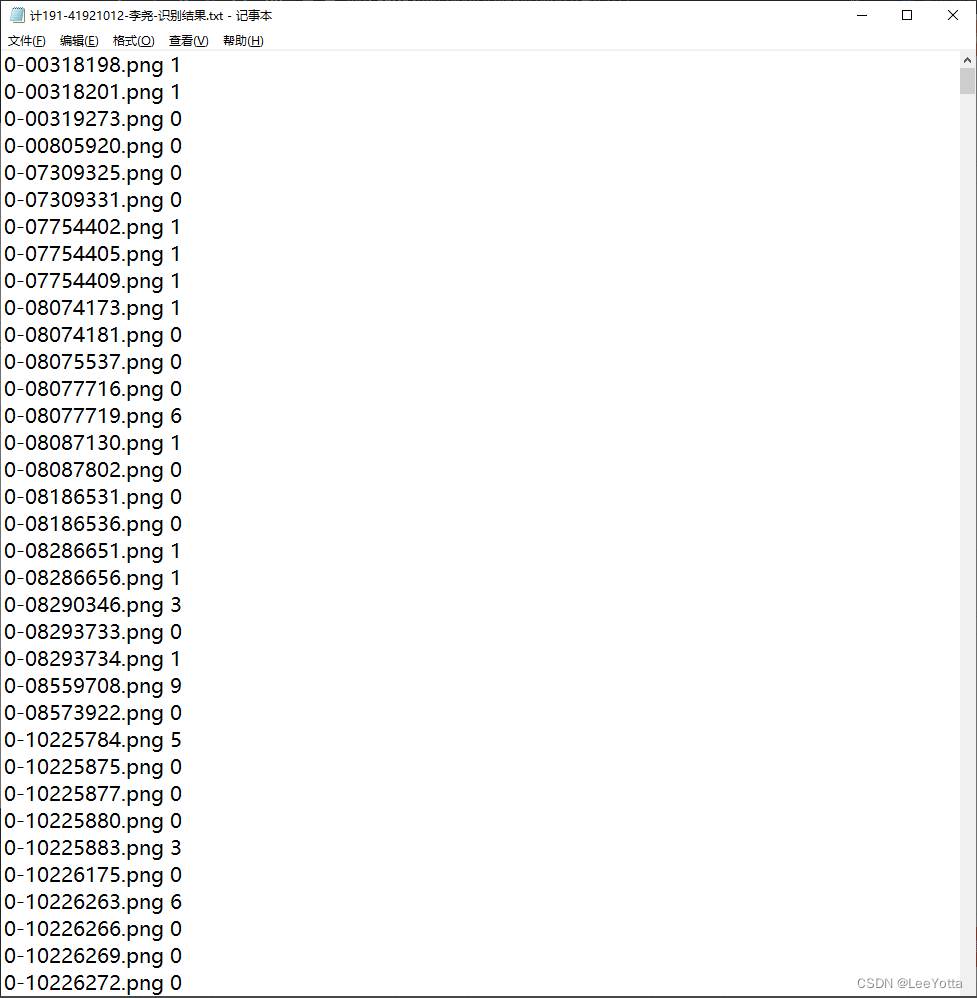
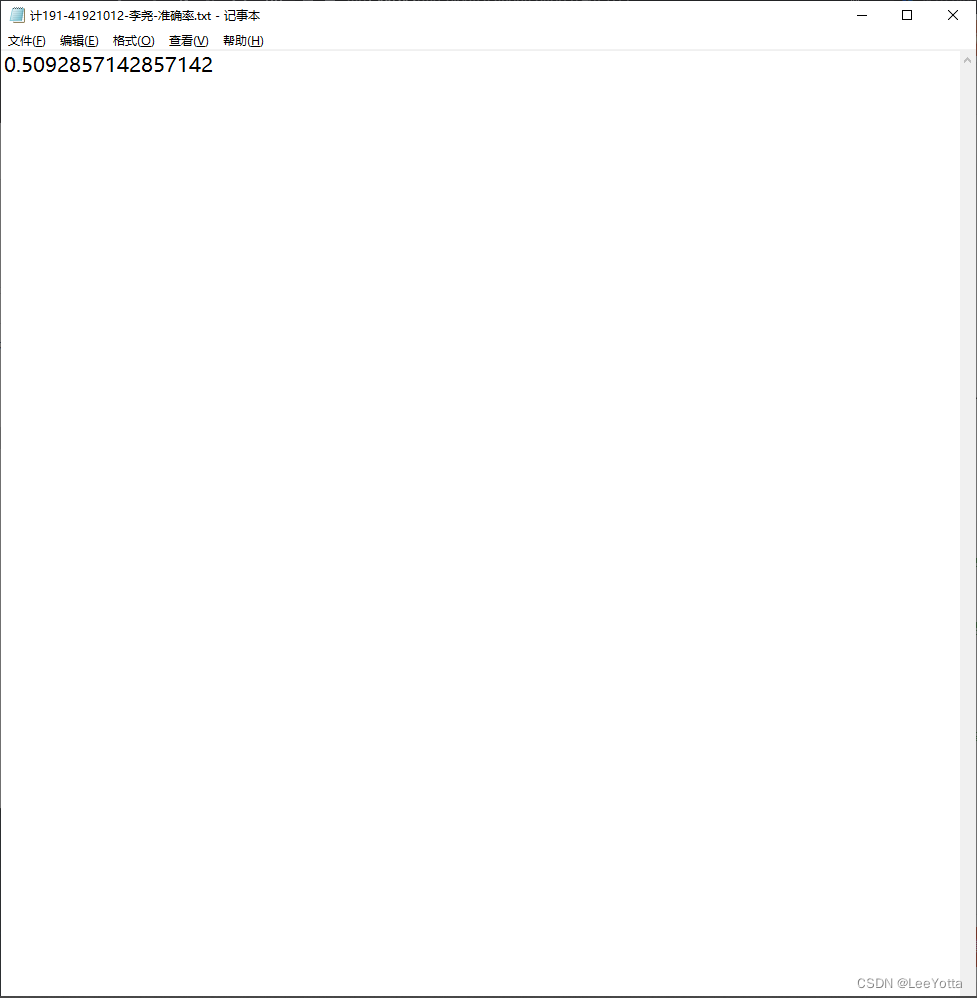
4.模型共有两个测试集,第一个测试集将发放用于自我测试(1400张),测试集也需要进行预处理。在提交作业时需要给出在测试集上的识别准确度(如97.1%等)并给出具体识别结果,不允许在模型构建阶段使用本部分数据。此部分结果作为评分排序依据之一。
二、作业过程
1.首先导入相关包
from sklearn.neighbors import KNeighborsClassifier as knn
import joblib
import numpy as np
import os
from PIL import Image
from sklearn.metrics import accuracy_score2.图像转为向量
def img2vec(file,name):
im = Image.open(file+"/"+name).convert('L')
im = im.resize((28,28))
a=im.getpixel((0,0))
if a<128:
for i in range(28):
for j in range(28):
im.putpixel((i,j),255-im.getpixel((i,j)))
tmp = np.array(im)
vec = tmp.ravel()
return vec3.文件名输出
def file_name(name):
x=[]
y=[]
for i in list(os.walk(name))[0][2]:
x.append(img2vec(name,i))
y.append(i[0])
return x,y4.knn训练并测试
x,y=file_name("train")
knn1=knn()
knn1.fit(x,y)
x1,y1=file_name("test")
print("训练完成")
pre=knn1.predict(x1)
names=[]
for i in list(os.walk("test"))[0][2]:
names.append(i)
with open("result.txt","w") as f:
for i in range(len(names)):
print(names[i]+" "+str(pre[i]),file=f)
print(accuracy_score(y1,pre))三、运行结果

四、源代码附上:
'''
本次作业旨在通过对手写数字图像进行分析,得到识别的数字,主要考察学生对图像预处理、神经网络或相关机器学习算法的理解和应用。
具体要求:
1.对给定的手写字体训练集(8000张图片),附件为:
进行预处理,统一处理为28*28像素,单通道8位灰度(0-255)的图像格式,编写代码将原始数据转为可训练数据。
2.对可训练的手写字体图像数据,进行合理的训练集和验证集划分,建立一个识别模型
(模型类型不限,可以是神经网络、SVM、决策树等之一或集成)
3.选定合理的评价指标分析模型性能。
4.模型共有两个测试集,第一个测试集将发放用于自我测试(1400张),附件为:
测试集也需要进行预处理。在提交作业时需要给出在测试集上的识别准确度(如97.1%等)并给出具体识别结果,不允许在模型构建阶段使用本部分数据。此部分结果作为评分排序依据之一。
5.对约20%同学将进行抽查,会发放第二套测试集(1400)张(与第一个测试集格式全同),要求在10分钟内返回识别结果,由教师测程序自动计算识别率,此部分结果作为评分的另一依据。如果两次准确度差异较大将酌情扣分。
提交方式:压缩格式,文件后缀为ZIP。示例文件为:
其中:
(1)压缩文件根目录包含pdf文件,名称为“班级-学号-姓名-作业4.pdf”,为作业的文档,内容包括作业过程、公式推导、代码说明、模型训练过程和结果、可视化图表等。
(2)压缩包根目录含txt文件,名称为“班级-学号-姓名-作业4准确率.txt”,其中仅包含一行文字,参考格式为“1321/1400”,表示测试集1400张正确识别了1321张。
(3)压缩包根目录含txt文件,名称为“班级-学号-姓名-作业4识别结果.txt”,其中包含1400行文字,每行参考格式为“abcde.png 1”,表示测试集中名称为”abcde.png”的文件被识别为数字1。
(4)压缩文件包含src子目录,其中包含所有的相关代码等。原始数据无需放置在压缩包内。
'''
from sklearn.neighbors import KNeighborsClassifier as knn
import joblib
import numpy as np
import os
from PIL import Image
from sklearn.metrics import accuracy_score
def img2vec(file,name):
im = Image.open(file+"/"+name).convert('L')
im = im.resize((28,28))
a=im.getpixel((0,0))
if a<128:
for i in range(28):
for j in range(28):
im.putpixel((i,j),255-im.getpixel((i,j)))
tmp = np.array(im)
vec = tmp.ravel()
return vec
def file_name(name):
x=[]
y=[]
for i in list(os.walk(name))[0][2]:
x.append(img2vec(name,i))
y.append(i[0])
return x,y
if __name__=="__main__":
x,y=file_name("train")
knn1=knn()
knn1.fit(x,y)
x1,y1=file_name("test")
print("训练完成")
pre=knn1.predict(x1)
names=[]
for i in list(os.walk("test"))[0][2]:
names.append(i)
with open("result.txt","w") as f:
for i in range(len(names)):
print(names[i]+" "+str(pre[i]),file=f)
print(accuracy_score(y1,pre))
五、心得体会
通过对手写数字识别案例的练习,我初步了解到了深度学习的内容,感受到了这一门学科的魅力