官方教程:https://platform.openai.com/docs/guides/fine-tuning
0. 设置API Key
在操作前需要在系统环境变量里加入OpenAI的 API Key(变量名:OPENAI_API_KEY)。
API Key获取:https://platform.openai.com/account/api-keys
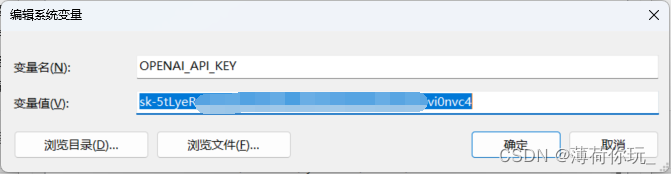
Linux可以直接用以下指令在终端里添加:
export OPENAI_API_KEY="自己的API_KEY"
1. 安装OpenAI-CLI工具
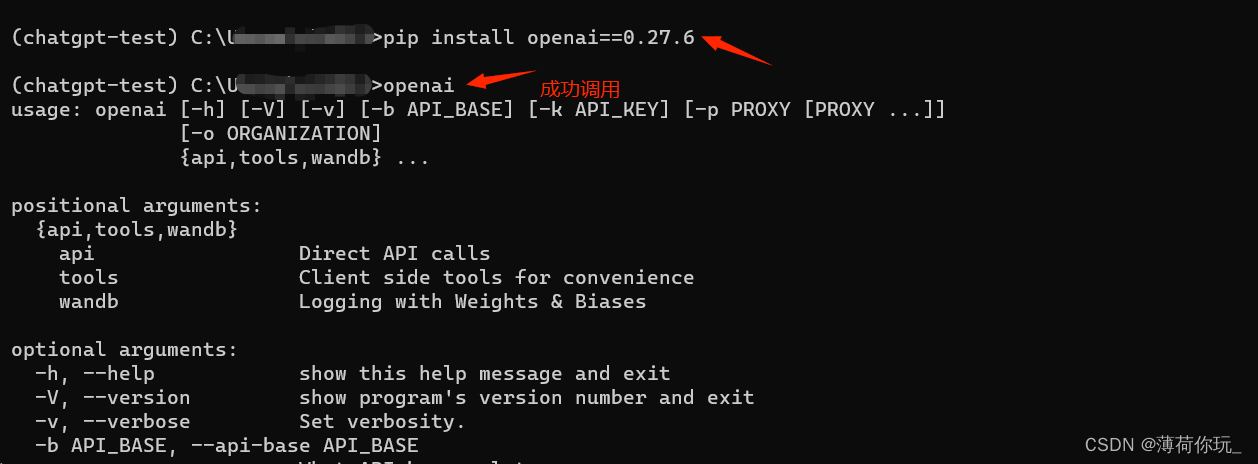
这里直接在 Python 环境里 pip 安装 openai 库就可以了。
但是! 官方的指令是 pip install --upgrade openai ,直接装的话可能会出现后续在 终端里输入 openai指令的时候提示 'openai' 不是内部或外部命令,也不是可运行的程序或批处理文件。
可靠的做法是指定版本安装:pip install openai==0.27.6
2. 处理自己的数据集
OpenAI要求的数据格式是
jsonl(一行一行的json数据) json 里两个key分别是prompt和
completion,分别表示模型输入和输出的文字。{ "prompt": "<prompt text>", "completion": "<ideal generated> text>"} { "prompt": "<prompt text>", "completion": "<ideal generated> text>"} { "prompt": "<prompt text>", "completion": "<ideal generated> text>"} ...数据规范(可以改善模型性能):
- 每个 prompt 应以固定的分隔符结尾,以通知模型 prompt 的结束和 completion 的开始。一个通常效果不错的简单分隔符是 \n\n###\n\n。分隔符不应在任何 prompt 中的其他位置出现。
- 每个 completion 应以空格开头,因为我们的分词将大多数单词与前导空格一起分词。
- 每个 completion 应以固定的停止序列结尾,以通知模型完成的结束。停止序列可以是 \n、### 或不在任何 completion 中出现的标记。
- 对于推理,您应该以与创建训练数据集时相同的方式对 prompt 进行格式化,包括相同的分隔符。还要指定相同的停止序列,以正确截断 completion 部分。
准备好自己的数据,可以利用 openai 的工具快捷将数据处理成上述的 JSONL 的格式。
自己的数据文件格式支持:CSV, TSV, XLSX, JSON 和 JSONL。
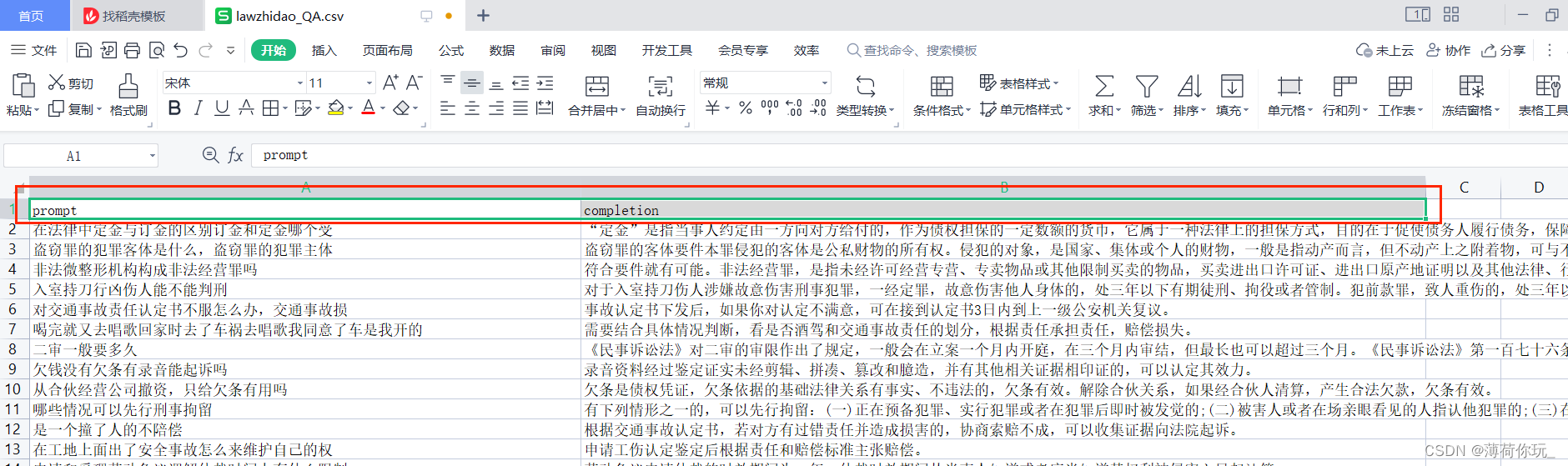
以csv为例,我们需要把数据处理成两列,分别是 prompt 和 completion。(注意:表头不能少)
prompt,completion
问题1,回答1
问题2,回答2
问题n,回答n
之后,在终端内调用 openai 的数据处理指令:
openai tools fine_tunes.prepare_data -f <处理好的数据文件路径>
如:openai tools fine_tunes.prepare_data -f lawzhidao_QA.csv
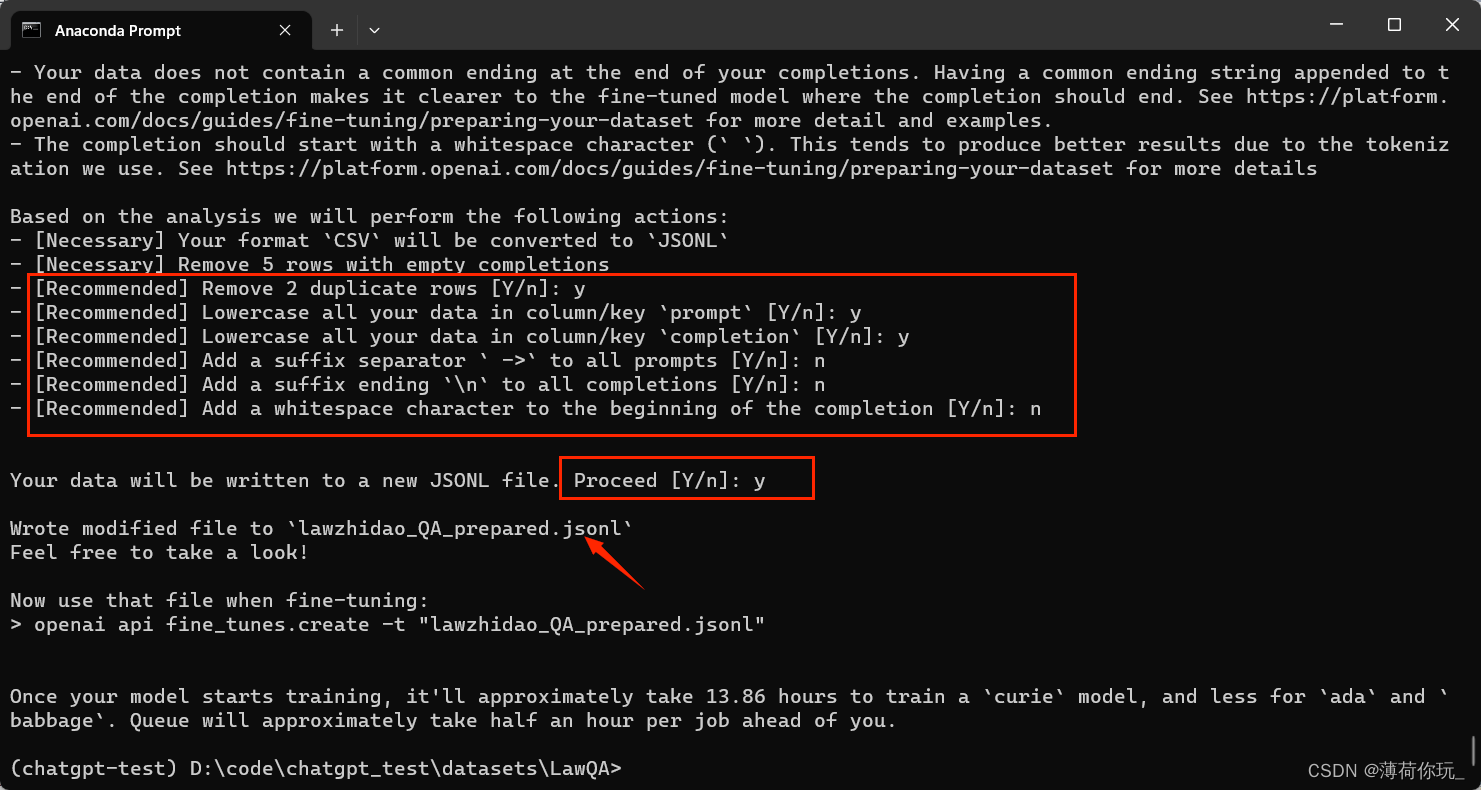
过程中会有几个选项让选择,根据自己的需求输入 y/n 就可以了。
处理完成后,会在数据目录下生成一个jsonl的文件,就是OpenAI微调需要的格式文件了。
3. 模型微调
OpenAI目前支持微调的模型有 ada, babbage, curie, davinci 四种,模型参数量依次增大。微调和调用价格表如下:
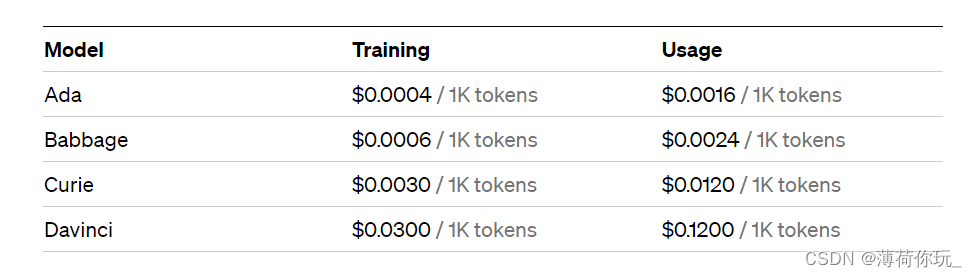
目前支持微调的模型列表里是没有 ChatGPT 的,所以 “基于ChatGPT微调” 的说法严格来说是错误的,目前实现不了,只能基于更基础的模型进行微调。(这些模型都是基于GPT-3的)
创建微调模型指令:
openai api fine_tunes.create -t <上面处理好的jsonl文件路径> -m <微调的模型名> --suffix "自定义微调后的模型名(可选项)"
如:openai api fine_tunes.create -t lawzhidao_QA_prepared.jsonl -m ada --suffix "law-QA" (–suffix指令非必需)
PS:此步骤需要调用OpenAI的服务器,需要开启加速代理。如果开启代理后终端内仍然无法访问OpenAI,可以在终端里再配置下代理
set http_proxy=https://<proxy_server>:<proxy_port>
set https_proxy=https://<proxy_server>:<proxy_port>
如:
set http_proxy=http://127.0.0.1:2802
set https_proxy=http://127.0.0.1:2802
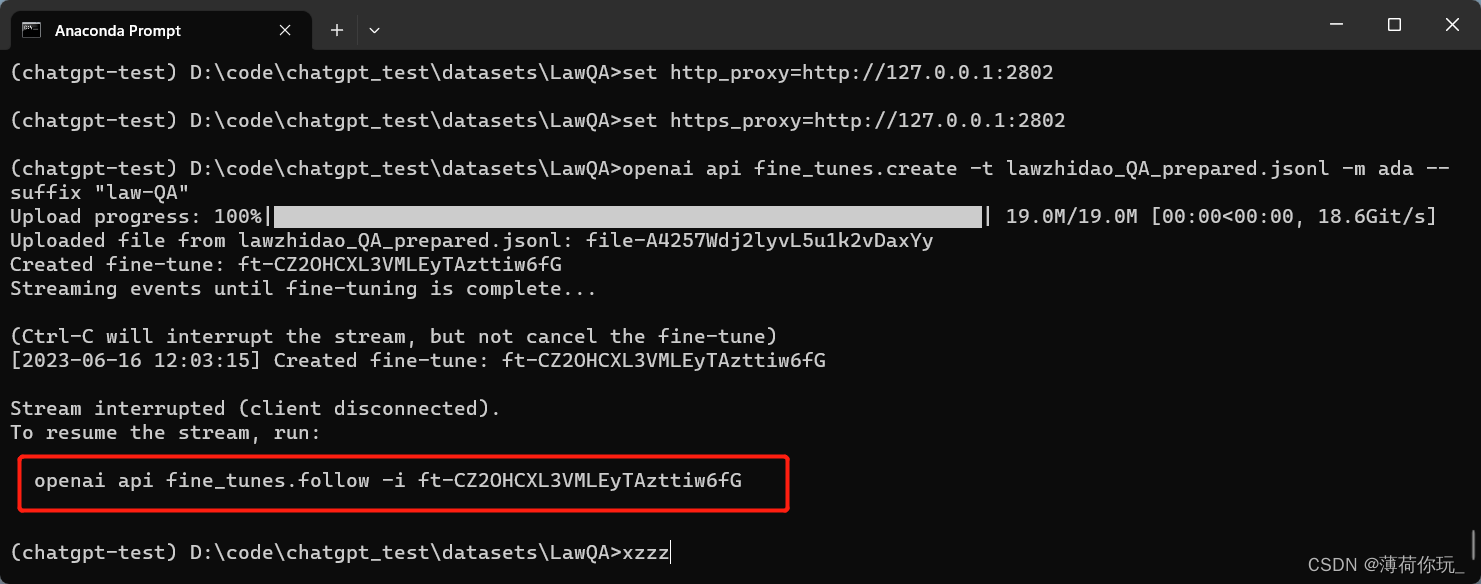
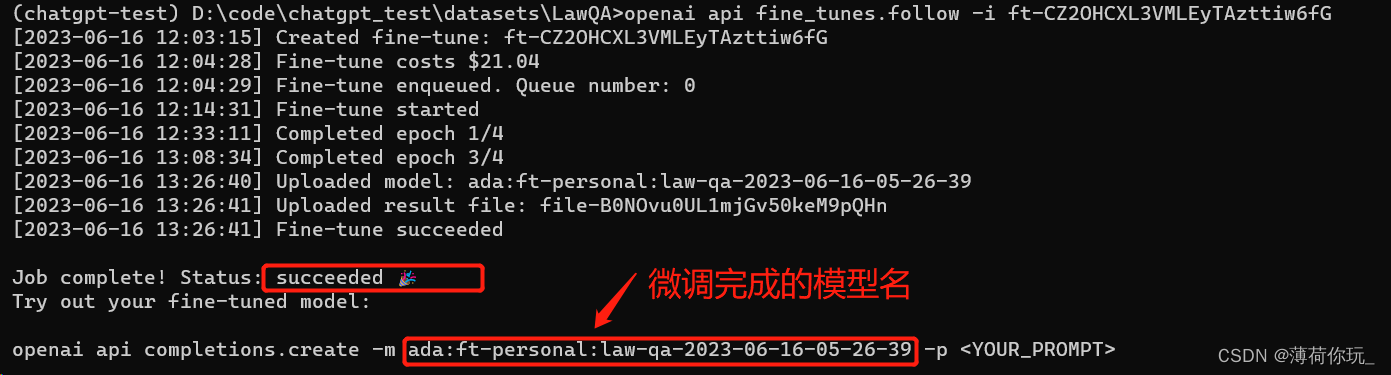
微调过程中如果连接中断可以使用openai api fine_tunes.follow -i 任务ID 来继续查看任务进度,OpenAI会有提示,如上图。

等待一定的时间后,微调完成会返回微调好的模型名。
4. 模型调用
微调完后,可以通过返回的模型名进行调用了,调用方式和 ChatGPT 差不太多。
Python为例:
import openai
openai.api_key = "sk-xxxxxxxxxxxxxxxxxxx"
def fine_tuned(prompt):
completion = openai.Completion.create(
model='ada:ft-personal:law-qa-2023-06-16-05-26-39', # 微调后的模型名
prompt=prompt,
max_tokens=9999 # 模型回复最大token数
)
print(completion.choices[0].text)
if __name__ == '__main__':
while True:
fine_tuned(input(">> "))

附:
- openai.Completion.create参数说明:https://platform.openai.com/docs/api-reference/completions/create
- OpenAI API调用价格:https://openai.com/pricing
- OpenAI Fine Tuning:https://platform.openai.com/docs/guides/fine-tuning
翻译版:http://e.betheme.net/article/show-1459696.html