
各行各业的组织正在寻求利用生成式人工智能(Generative AI)和大型语言模型(LLM)的巨大潜力,显著改进用户体验的新方法。
在时尚行业,生成式人工智能完全改变了创作过程。人工智能算法分析用户喜好和数据,生成独具特色的服装图案和设计,将个性化和成本效益提升到全新的高度。
在线流媒体平台也得益于人工智能的强大功能,特别是视频相似性搜索和推荐方面。人工智能算法可分析用户行为,推荐与用户兴趣高度相似的视频,从而增强整体观看体验。此外,对于人工智能提供技术支持的图像和视频托管服务,它们可提供图像重复数据删除、图像相似性搜索,以及文本到图像相似性搜索,从而全面改进搜索功能。
人工智能在其他领域也发挥重要作用,例如化学信息学和生物信息学行业。人工智能利用分子相似性搜索和 DNA 序列分类相似性搜索,在药物发现和研究领域发挥重要作用。无论识别潜在备选药物或分析 DNA 序列,大众普遍认为人工智能是一种极具价值的工具。
在本博客中,我们将为您讲解如何集成 Amazon SageMaker 和 Amazon Relational Database Service (Amazon RDS) for PostgreSQL 的 pgvector插件,创建产品目录相似性搜索解决方案,从而生成相似的解决方案。
pgvector 是一款 PostgreSQL 的开源插件。该插件可存储和搜索机器学习生成的embedding数据。pgvector 具有不同功能,支持用户识别精确和近似的邻域数据。该插件旨在与其他 PostgreSQL 功能无缝协作,其中包含创建索引和执行查询。甚至,也可使用 pgvector,存储 Amazon Bedrock(部分预览)机器学习训练输出的embedding数据。
无论您所处零售、游戏、流媒体服务或生命科学等行业,本博客在使用人工智能和 PostgreSQL 插件pgvector 实施相似性搜索等其他操作方面,提供了非常独到的见解。现在就开始吧!
Vector Embeddings 概览
Embedding 是指,将文本、图像、视频或音频等对象转换为数字表征的过程;在此过程中,高维向量空间会保留这些数字表征。该技术的实现主要得益于机器学习(ML)算法;这些算法可读懂数据含义及上下文(语义关系),学习数据的复杂关系和模式(句法关系)。对于生成的向量表征,其应用范围多种多样,例如信息检索、图像分类、自然语言处理等。
由于 Vector Embeddings 以易于计算和可扩展的方式方便捕捉对象间的语义含义和相似性,因此它们越来越受欢迎。下图直观显示了Word Embeddings的外观。
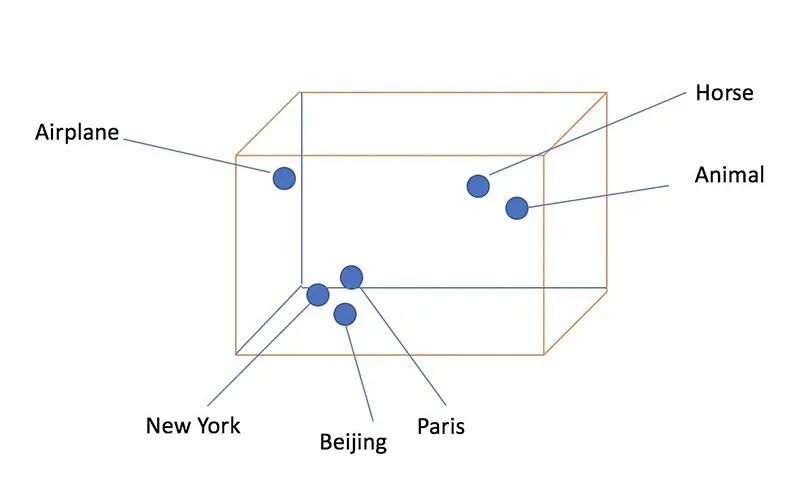
图 1:Word Embeddings:对于语义相似的词,它们在向量空间中密切相关。
在生成 Embeddings 后,应用程序或研究人员可在向量空间内执行相似性搜索。采用 Embedding 的相似性搜索对各行各业应用有益,其中包含电子商务、推荐系统和欺诈检测。例如,系统可识别产品或交易之间的数学相似性,便于创建相关产品推荐,或确定潜在的欺诈活动。
在本博客中,我们采用适用于 Amazon RDS for PostgreSQL 的开源 pgvector 插件。该插件便于存储向量数据,也可查询向量的最近邻域数据。利用为在线零售店生成的实验室方案,演示此功能。使用 SageMaker 为产品目录生成Embedding,采用 pgvector 插件将其存储到 RDS for PostgreSQL,并利用 Embedding 之间的相似性为产品目录提供向量相似性搜索功能。
使用 pgvector 实现Embedding向量的
高效相似度搜索
PostgreSQL 使用 pgvector 插件,对 Vector Embeddings 执行高效的相似性搜索,并为企业提供快速成熟的解决方案。
要为产品目录生成 Vector Embeddings,使用 Amazon SageMaker 或 Amazon Bedrock(部分预览)等机器学习服务。SageMaker 支持轻松训练和部署机器学习模型,其中包含为文本数据生成 Vector Embeddings 的模型。
在本博客中,我们使用预先训练的模型 Hugging Face Inference Deep Learning Container (DLC) 和 Amazon SageMaker Python SDK,创建实时推理端点;该端点运行 all-MiniLM-L6-v2 语句转换器模型,生成文档 Embedding。使用 pgvector 插件,将 Vector Embeddings 存储到 RDS for PostgreSQL 数据库。然后,使用 pgvector 的相似性搜索功能,在产品目录中查找与客户搜索查询意图最匹配的项目。
pgvector 的索引功能将进一步增强搜索优化。您可为向量数据编制索引,从而加速搜索过程,并在确定任何指定向量的最近邻域方面,最大限度地缩短所需的时间。我们会测试如何集成 pgvector 插件与 PostgreSQL,从而为 Vector Embeddings 的相似性搜索提供简化高效的解决方案。
我们来了解 pgvector 的工作方式。首先,创建并连接到 RDS for PostgreSQL 数据库,并安装插件。在安装成功后,请在数据库中启动存储 Vector Embeddings,并按需搜索。
CREATE EXTENSION vector;左滑查看更多
pgvector 插件扩展引入了名为 vector 的数据类型。您会发现,安装 vector 数据类型需要使用下列 SQL 语句:
SELECT typname FROM pg_type WHERE typname = 'vector';左滑查看更多
输出应如下所示:
typname --------- vector (1 row)左滑查看更多
使用 sentence-transformers/all-MiniLM-L6-v2 模型(链接:
sentence-transformers/all-MiniLM-L6-v2
),生成 Vector Embeddings。该 Vector Embeddings 将语句和段落映射到 384 维密集向量空间,便于我们在解决方案中将其应用于向量大小。
我们回顾了使用 pgvector 的示例。使用下列代码,创建用于存储 3 维向量的测试表,插入一些示例数据,使用欧氏距离(Euclidean Distance,也称 L2 距离)执行查询,并删除测试表:
CREATE TABLE test_embeddings(product_id bigint, embeddings vector(3) ); INSERT INTO test_embeddings VALUES (1, '[1, 2, 3]'), (2, '[2, 3, 4]'), (3, '[7, 6, 8]'), (4, '[8, 6, 9]'); SELECT product_id, embeddings, embeddings <-> '[3,1,2]' AS distance FROM test_embeddings ORDER BY embeddings <-> '[3,1,2]'; DROP TABLE test_embeddings;左滑查看更多
SELECT 语句应返回以下输出:
product_id | embeddings | distance
------------+------------+-------------------
1 | [1,2,3] | 2.449489742783178
2 | [2,3,4] | 3
3 | [7,6,8] | 8.774964387392123
4 | [8,6,9] | 9.9498743710662
(4 rows)左滑查看更多
有关其他详细信息,请参阅 GitHub 仓库(https://github.com/pgvector/pgvector)。
演示:
使用相似性搜索,
增强在线零售店中执行产品目录搜索
鉴于已了解如何使用 pgvector 生成向量相似性搜索,我们现在学习如何使用 pgvector 为在线零售店的产品目录生成搜索解决方案。我们将生成搜索系统;该系统支持客户输入项目描述,查找相似项目返回给客户。
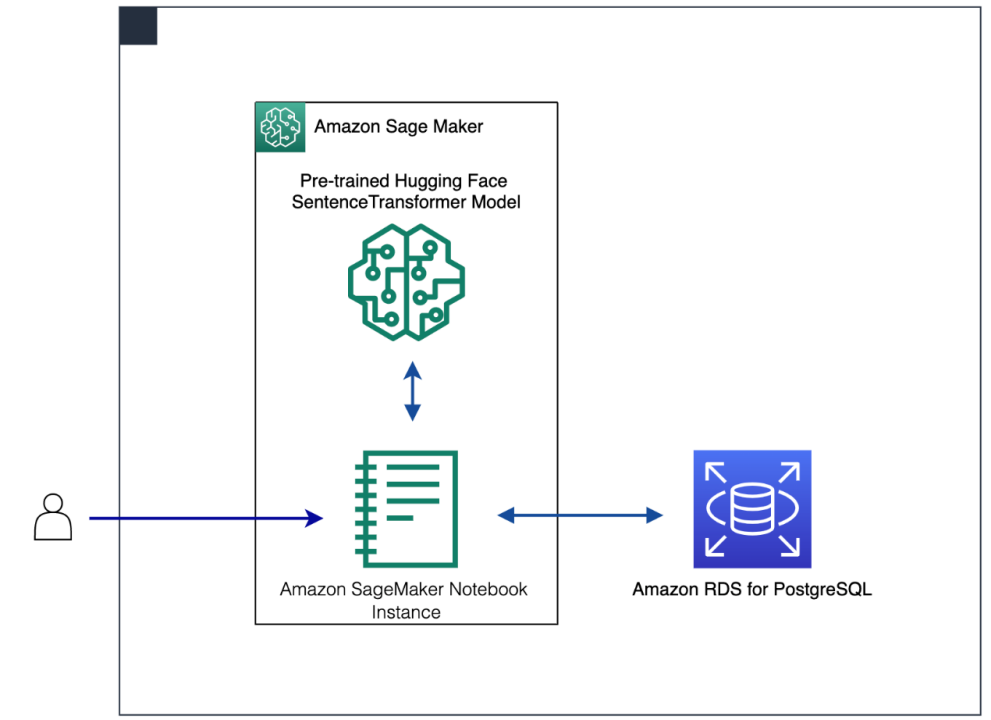
以下部分介绍了执行产品相似性搜索的分步演示。在 SageMaker 实例中,使用 Hugging Face 预训练的模型,为产品描述生成 Vector Embeddings。使用 Amazon RDS for PostgreSQL 进行存储,并利用 pgvector 插件对 Vector Embeddings 执行相似性搜索。
工作流步骤如下所示:
在 SageMaker notebook实例中,用户与 Jupyter notebook进行交互。SageMaker notebook实例是机器学习计算实例,并运行 Jupyter notebook应用程序。SageMaker 管理创建实例和相关资源。
最初,对于每个使用德语开源的项目描述,使用 Amazon Translate 将其翻译为英语。
要为项目描述生成Embedding,请将预先训练的 Hugging Face sentence transformer model 部署到 SageMaker,以便开展实时推理。
使用 SageMaker 实时推理,为产品目录描述生成Embedding。
使用 RDS for PostgreSQL,存储原始文本(产品描述)和文本Embedding。
使用 SageMaker 实时推理,对查询文本进行Embedding编码。
借助 RDS for PostgreSQL,使用pgvector 执行相似性搜索。
将 Amazon SageMaker Studio notebook 用作集成开发环境(IDE),开发解决方案。下图讲解了解决方案的体系结构。
先决条件
参加本演示,您应先创建亚马逊云科技账户,并拥有相应的 Amazon Identity and Access Management (IAM) 权限,才可以启动预制的 Amazon CloudFormation 模板。
部署解决方案
使用 CloudFormation 堆栈,部署此解决方案。堆栈会创建所有必要的资源,其中包含以下内容:
网络组件,例如 VPC 和子网资源。
SageMaker notebook实例(在 Jupyter notebook中运行 Python 代码)。
与notebook实例关联的 IAM 角色。
RDS for PostgreSQL 实例(存储和查询 Vector Embeddings)。
要开始使用,请完成下列步骤:
使用 IAM 用户名和密码,登录亚马逊云科技管理控制台。
选择“启动堆栈”,并使用新选项卡打开: Launch Stack
在“创建堆栈”页面中,选中复选框,确认创建 IAM 资源。
选择“创建堆栈”。
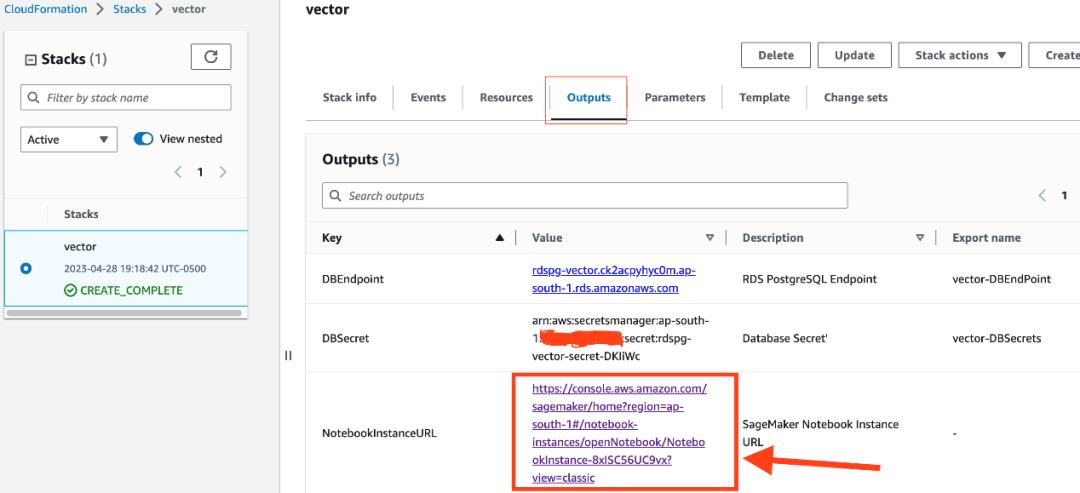
请等待堆栈创建完成。在“事件”选项卡中,检查堆栈创建过程中的各种事件。在堆栈创建完成时,将显示 CREATE_COMPLETE 状态。
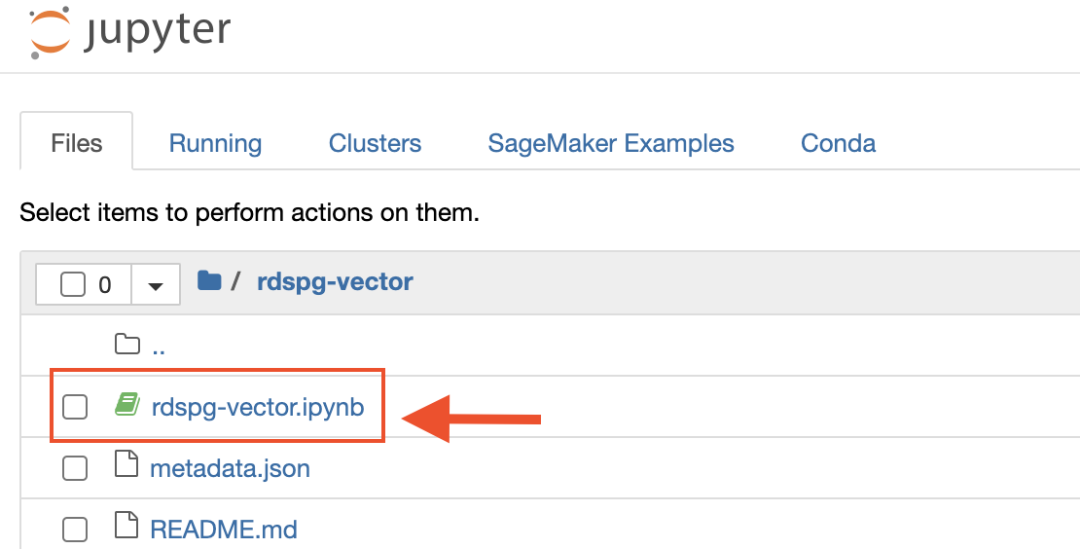
在“输出”选项卡中,选择 NotebookInstanceURL 。这个链接将在 SageMaker notebook 实例中打开 Jupyter notebook;可使用该 notebook,完成解决方案的剩余部分。
打开 notebook rdspg-vector.ipynb ,并按顺序在所有单元中运行代码,一次一个。
在以下部分中,我们将测试 Jupyter notebook中几个重要单元的部分代码,便于演示解决方案。
数据引入
使用 Zalando research FEIDEGGER 数据,其中包含 8,732 张高分辨率的时尚图像和 5 个德语文本注释,每个注释由不同的用户生成。使用 Amazon Translate,将每件连衣裙描述从德语翻译为英语。代码如下所示:
import urllib.request import os import json import boto3 filename = 'metadata.json' def download_metadata(url): if not os.path.exists(filename): urllib.request.urlretrieve(url, filename) def translate_txt(data): results = {} results['url'] = data['url'] results['descriptions'] = [] results['split'] = data['split'] translate = boto3.client(service_name='translate', use_ssl=True) for j in data['descriptions']: result = translate.translate_text(Text=str(j), SourceLanguageCode="de", TargetLanguageCode="en") results['descriptions'].append(result['TranslatedText']) return results download_metadata('https://raw.githubusercontent.com/zalandoresearch/feidegger/master/data/FEIDEGGER_release_1.2.json') with open(filename) as json_file: data = json.load(json_file) # we are using realtime traslation which will take around ~30 min. workers = 1 * cpu_count() chunksize = 32 #Translate product descriptions in German to English results = process_map(translate_txt, data, max_workers=workers, chunksize=chunksize)左滑查看更多
SageMaker 模型托管
在本部分中,将预先训练的 all-MiniLM-L6-v2 Hugging Face sentence transformer model 托管到 SageMaker,并为产品目录生成 384 维 Vector Embeddings。
步骤如下所示:
1. 运行下列代码:
from sagemaker.huggingface.model
import HuggingFaceModel # Hub Model configuration. <https://huggingface.co/models> hub = { 'HF_MODEL_ID': 'sentence-transformers/all-MiniLM-L6-v2', 'HF_TASK': 'feature-extraction' } # Deploy Hugging Face Model predictor = HuggingFaceModel( env=hub, # configuration for loading model from Hub role=role, # iam role with permissions to create an Endpoint transformers_version='4.26', pytorch_version='1.13', py_version='py39', ).deploy( initial_instance_count=1, instance_type="ml.m5.xlarge", endpoint_name="rdspg-vector", )左滑查看更多
2. 测试 SageMaker 实时推理端点,并生成 Embedding:
def cls_pooling(model_output): # first element of model_output contains all token embeddings return [sublist[0] for sublist in model_output][0] data = { "inputs": ' '.join(results[0].get('descriptions')) } res = cls_pooling( predictor.predict(data=data) ) print(len(res))左滑查看更多
结果将显示指定输入文本的 384 维 Vector Embeddings。
3. 使用 SageMaker 请求推理,从而为产品目录描述生成 Vector Embeddings(384 维):
def generate_embeddings(data): r = {} r['url'] = data['url'] r['descriptions'] = data['descriptions'] r['split'] = data['split'] inp = {'inputs' : ' '.join( data['descriptions'] ) } vector = cls_pooling( predictor.predict(inp) ) r['descriptions_embeddings'] = vector return r workers = 1 * cpu_count() chunksize = 32 # generate embeddings data = process_map(generate_embeddings, results, max_workers=workers, chunksize=chunksize)左滑查看更多
4. 连接到 RDS for PostgreSQL,创建包含向量数据类型的产品表,并摄入数据。然后,为相似性搜索创建对应的索引,便于查找 L2 距离最近的邻域向量数据:
import psycopg2 from pgvector.psycopg2 import register_vector
import boto3 import json client = boto3.client('secretsmanager') response =
client.get_secret_value( SecretId='rdspg-vector-secret' )
database_secrets = json.loads(response['SecretString']) dbhost =
database_secrets['host'] dbport = database_secrets['port'] dbuser =
database_secrets['username'] dbpass =
database_secrets['password'] dbconn =
psycopg2.connect(host=dbhost, user=dbuser, password=dbpass, port=dbport, connect_timeout=10)
dbconn.set_session(autocommit=True)
cur = dbconn.cursor()
cur.execute("CREATE EXTENSION IF NOT EXISTS vector;")
register_vector(dbconn)
cur.execute("DROP TABLE IF EXISTS products;")
cur.execute("""CREATE TABLE IF NOT EXISTS products( id bigserial primary key, description text, url text, split int, descriptions_embeddings vector(384) );""") for x in data:
cur.execute("""INSERT INTO products (description, url, split, descriptions_embeddings) VALUES (%s, %s, %s, %s);""", (' '.join(x.get('descriptions', [])), x.get('url'), x.get('split'), x.get('descriptions_embeddings') ))
cur.execute("""CREATE INDEX ON products USING ivfflat (descriptions_embeddings vector_l2_ops) WITH (lists = 100);""")
cur.execute("VACUUM ANALYZE products;")
cur.close() dbconn.close()左滑查看更多
5. 运行查询,使用 pgvector,从而对 RDS for PostgreSQL 中的产品表执行相似性搜索:
import numpy as np from skimage
import io
import matplotlib.pyplot as plt
import requests data = {"inputs": "red sleeveless summer wear"} res1 = cls_pooling(predictor.predict(data=data))
client = boto3.client('secretsmanager')
response =
client.get_secret_value( SecretId='rdspg-vector-secret' )
database_secrets = json.loads(response['SecretString']) dbhost =
database_secrets['host'] dbport = database_secrets['port'] dbuser =
database_secrets['username'] dbpass = database_secrets['password'] dbconn =
psycopg2.connect(host=dbhost, user=dbuser, password=dbpass, port=dbport, connect_timeout=10)
dbconn.set_session(autocommit=True) cur = dbconn.cursor() cur.execute("""SELECT id, url, description, descriptions_embeddings FROM products ORDER BY descriptions_embeddings <-> %s limit 2;""", (np.array(res1),)) r =
cur.fetchall() urls = [] plt.rcParams["figure.figsize"] = [7.50, 3.50] plt.rcParams["figure.autolayout"] = True for x in r: url = x[1].split('?')[0] urldata = requests.get(url).content print("Product Item Id: " + str(x[0])) a =
io.imread(url) plt.imshow(a) plt.axis('off') plt.show() cur.close() dbconn.close()左滑查看更多
以上代码应返回与以下示例相似的输出:

现在,客户在线零售应用程序中输入“red sleeveless summer dress”等搜索查询时,向量相似性搜索功能将为客户返回匹配度最接近的结果。
清理
在 Jupyter notebook 窗口中,运行下列代码,删除模型和端点:
predictor.delete_model() predictor.delete_endpoint()左滑查看更多
然后,删除 CloudFormation 模板,清理其余资源。
结论
对于优化产品目录的相似性搜索体验的场景,通过SageMaker生成的Embeddings数据,将其与 Amazon RDS PostgreSQL 的 pgvector 开源插件集成,可以提供功能强大的高效解决方案。企业使用机器学习模型和 Vector Embeddings,提高相似性搜索、个性化推荐和欺诈检测的准确性和速率,最终也将显著提高用户满意度,并提供更具个性化的体验。
使用 pgvector 既可为查询大型数据集赋予可扩展性,也可集成 PostgreSQL 的现有功能。无论浏览内容宽泛的电子商务产品目录或提供高度相关的内容推荐,集成 SageMaker 与 pgvector 将为组织提供必要的工具,便于该组织在多变的和数据驱动的业务领域中独占鳌头。
借助 PostgreSQL 的可扩展性,在工作负载不断增加的情况下,开发人员可生成新的向量数据类型和索引机制。随着人工智能和机器学习的不断创新,我们可使用 PostgreSQL,构建以人工智能/机器学习模型为核心的应用程序。
有关本博客所用代码示例的更多信息,请参阅 GitHub 仓库(https://github.com/aws-samples/rds-postgresql-pgvector)。
本篇作者

克里希纳·萨拉布
在亚马逊云科技担任高级数据库专家解决方案架构师。日常工作是与 Amazon RDS 团队协作,共同专注于开源数据库引擎 Amazon RDS for PostgreSQL 和 Amazon Aurora PostgreSQL。在管理金融行业的商业和开源数据库解决方案方面,他本人拥有 20 多年丰富的经验,十分喜欢与客户合作,帮助他们在亚马逊云科技中设计、部署并优化关系数据库工作负载。


听说,点完下面4个按钮
就不会碰到bug了!
