笔记说明:本文是我的学习笔记,大部分内容整理自 黄红梅,张良均等.Python数据分析与应用[M].北京:人民邮电出版社,2018:133-163. 还有部分片断知识来自网络搜索补充。
目录
0.数据来源
来源于这本书,黄红梅,张良均等.Python数据分析与应用[M].北京:人民邮电出版社,2018,的第五章附带数据。
CSDN的数据不可以免费共享,至少要一个金币,有能力的就去下载一下数据下载链接CSDN数据。不方便的,在底下头评论留言,留下邮箱号,我看到之后就会把数据发给你,或者你可以在这本书的出版社网站人民邮电出版社教育社区或者“泰迪杯数据挖掘比赛”泰迪杯数瑞思的网站上找这本书的附带资源,都是免费下载的。
0.1说明
这本书吧,第一部分是pandas和数据库MySQL的对接处理.sql数据。一般的公司的话,有专门的做数据分析的小组或者部门的,需要什么数据跟他们提需求让他们获取,拿.csv就好了。所以我就跳过了sql里面的inner join\outer join\主键合并。我的笔记直接是读取csv数据。
喔还有就是,做这行的话,sql是基础技能,一定要会基础的取数!
1.清洗数据
1.1检测与处理重复值
1.1.1记录重复
import pandas as pd
detail=pd.read_csv("D:\\codes\\python\\data\\detail.csv",
index_col=0,encoding='gbk')
#方法一:定义去重函数
def delrep(list1):
list2=[]
for i in list1:
if i in list1:
if i not in list2:
list2.append(i)
return list2
##去重
dishes=list(detail['dishes_name'])
print('去重前菜品总数是:',len(dishes))
dish=delrep(dishes)
print('方法一去重后数据总数是:',len(dish))
#方法二:利用集合唯一性
print('去重前菜品总数为:',len(dishes))
dish_set=set(dishes)
print(len(dish_set))
这两种方法,区别在,set会将数据顺序打乱。
#方法三:.drop_duplicates
pd.DataFrame(series).drop_duplicates(self,subset=None,keep='first',
inplace=False)
| 参数名字 | 说明 |
|---|---|
| subset | 接收string或sequence,表示进行去重的列,默认none,全部列 |
| keep | 接收string,表示重复时保留第几个数据 |
| keep | first:保留第一个;last:最后一个;false:只要有重复就都不保留。默认first |
| inplace | 接收boolean,表示是否在原表上进行操作,默认false |
dishes_name=detail['dishes_name'].drop_duplicates()
print(len(dishes_name))
1.1.2特征重复
这里的重复是指,特征之间的相似度=1!所以可以作为特征工程海筛特征的一步!
method参数可以是:spearman,person,kendall
注意这个不能计算分类变量的相似度。
corrdet=detail[['counts','amounts']].corr(method='spearman')
print(corrdet)
corrdet1=detail[['dishes_name','counts','amounts']].corr(method='pearson')
print(corrdet1)
分类变量的话,可以自己写一个判断特征矩阵是否完全相同的函数
1.2检测与处理缺失值
print('缺失值数目是:',detail.isnull().sum())
print(detail,notnull().sum())
1.2.1删除法
dropna(self, axis=0, how='any', thresh=None,
subset=None, inplace=False)
| 参数 | 说明 |
|---|---|
| asix | 0/1,0是对列操作,删除记录行;1是删除列。 |
| how | 接收string,表示删除的形式,any表示只要有缺失值就会被删除,all表示当且仅当全部为缺失值时才会执行删除操作,默认any |
| subset | 接收array,表示进行去重的行列。默认是none,表示所有行列 |
| inplace | 接收Boolean,表示是否在原表上进行操作,默认是false |
print('删除之前',detail,shape)
print('之后',detail.dropna(axis=1).shape)
1.2.2替换法
pd.DataFrame.fillna(self, value=None, method=None, axis=None,
inplace=False, limit=None, downcast=None, **kwargs)
| 参数 | 说明 |
|---|---|
| value | 接收scalar,dict,series,dataframe,表示用来替换缺失值,无默认 |
| method | 接收待定string。backfill或bfill表示使用下一个非缺失值来填补空缺;pad或ffill表示使用上一个非缺失值来填补,默认none |
| axis | 轴向。1为“跨列!”这个词解释很透彻 |
| inplace | 接收Boolean,表示是否在原表上操作,默认False |
| limit | 接收int,表示填补缺失值个数上限,默认none |
detail=detail.fillna(777)
print(detail.isnull().sum())
1.2.3插值法
常用的插补法有:线性插补、多项式插补(拉格朗和牛顿)、样条插值
这里使用的是scipy包的interpolate模块
还有这个在图像领域常用的插值法是重心坐标插值,BarycentricInterpolator
from scipy.interpolate import interp1d
import numpy as np
x=np.array([1,2,3,4,5,8,9])
y1=np.array([2,8,18,32,50,128,162]) ##y1=2*x^2
y2=np.array([3,5,7,9,11,17,19]) ##y2=2*x+1
# 线性插补
linearinsvalue1=interp1d(x,y1,kind='linear')
linearinsvalue2=interp1d(x,y2,kind='linear')
print(linearinsvalue1([7,11]),linearinsvalue2([7,11]))
out:[102. 246.] [15. 23.]
# 拉格朗日插补
from scipy.interpolate import lagrange
largeinsvalue1=lagrange(x,y1)
largeinsvalue2=lagrange(x,y2)
print(largeinsvalue1([7,11]),largeinsvalue2([7,11]))
out:[ 98. 242.] [15. 23.]
#样条插补
from scipy.interpolate import spline
splineinsvalue1=spline(x,y1,xnew=np.array([7,11]))
splineinsvalue2=spline(x,y2,xnew=np.array([7,11]))
print(splineinsvalue1,splineinsvalue2)
out:[ 98. 242.] [15. 23.]
对比看到不同方法的准确性哈~
main:1: DeprecationWarning: spline is deprecated!
spline is deprecated in scipy 0.19.0, use Bspline class instead.
这个函数要改变了,以后叫Bspline()
1.3 检测与处理异常值
1.3.1 正态分布的3σ原则
#写一个函数判断数据是否符合均值±3倍标准差的范围
def outrange(data):
boolind=(data.mean()-3*data.std()>data) | \
(data.mean()+3*data.std()<data)
index=np.arange(data.shape[0])[boolind]
print("这个",index) ##我就是想近距离感受一下index这个东西
outrange=data.iloc[index]
return outrange
outlier=outrange(detail['counts'])
print(outlier.shape[0])
print(outlier.max())
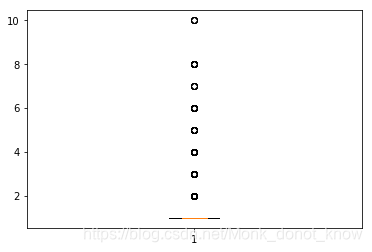
1.3.2箱线图
绘制箱线图之后,这里的异常值标签直接就是fliers,不需要再写函数判断了.
IQR=QL-QU
QL-1.5*IQR
QU+1.5*IQR
离群点是通过距离上下四分位数的距离来判断的
import matplotlib.pyplot as plt
plt.figure(figsize=(6,4))
p=plt.boxplot(detail['counts'].values,notch=True)
outlier1=p['fliers'][0].get_ydata()
plt.show()
print(len(outlier1),max(outlier1),min(outlier1))
print(p) ###近距离感受一下p的内容
print(p['fliers']) ###p['fliers'][0]获取点的坐标
outlier2=p['fliers'][0].get_xdata() ###再次感受下p['fliers'][0],就比较明确这个东西了
1.4上栗子!
在1.1.2中省略的自定义函数遍历所有数据分类型数据去重
在& |运算在dataframe上,我走了点弯路,搞了好久才找到一个靠谱的解释。在此排雷,上链接:
这个人的博文第三部分~https://blog.csdn.net/weixin_40041218/article/details/80868521
import pandas as pd
detail = pd.read_csv("D:\\codes\\python\\data\\detail.csv",
index_col=0,encoding='gbk')
print('这个么去重前的样本形状:',detail.shape)
#去重
detail.drop_duplicates(inplace=True)
# 特征去重
def featureEquals(df):
#这个自定义函数就是说白了就是每一列每一列元素一个一个去做比较,使用的是dataframe.equals函数,返回的是逻辑判断值
dfequals=pd.DataFrame([],columns=df.columns,index=df.columns)
for i in df.columns:
for j in df.columns:
dfequals.loc[i,j]=df.loc[:,i].equals(df.loc[:,j])
return dfequals
detequals=featureEquals(detail)
print('这个是近距离观察下自定义函数的返回值:',detequals)
#遍历所有数据
lendet=detequals.shape[0]
dupcol=[]
for k in range(lendet):
for l in range(k+1,lendet):
if detequals.iloc[k,l] & \
(detequals.columns[l] not in dupcol):
dupcol.append(detequals.columns[l])
#上面的输出结果是dupcol最终是所有的重复列
detail.drop(dupcol,axis=1,inplace=True)
print("去重之后的样本形状:",detail.shape)