异常值
-
1.异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也称离群点,异常值的分析也称为离群点的分析
-
2.异常值的处理,先是辨别出哪些是异常值,再根据实际情况选择如何处理异常值。
- 伪异常,比如由于特定业务运营而产生的;
- 真异常,并非业务运营而产生的,是客观反映数据本身存在异常的分布。
-
3.异常值分析
- 3σ原则
- 箱型图
-
4.异常值的处理方法
- 剔除异常值
- 视为缺失值NaN,填补处理
- 不处理
异常值分析及处理
方法1 → 3σ原则
3σ原则是指若数据服从正态分布,异常值被定义为一组测定值与其平均值的差的绝对值超过3倍标准差值 → p(|x - μ| > 3σ) ≤ 0.003
但使用3σ原则需要先判断数据是否服从正态分布,服从正态分布才能使用该原则判断异常值
第一步:正态性检验
正态性检验是指利用观测数据判断总体是否服从正态分布的检验称为正态性检验,它是统计判决中重要的一种特殊的拟合优度假设检验
→ 正态性检验方法:KS检验
→KS检验理论简介:
- KS(Kolmogorov-Smirnov)检验用于检验数据是否符合某种分布,是比较一个频率分布f(x)与理论分布g(x)或者两个观测值分布的检验方法。
- 其原假设H0:两个数据分布一致或者数据符合理论分布。D=max| f(x)- g(x)|,当实际观测值D>D(n,α)则拒绝H0,否则则接受H0假设。KS检验与t-检验之类的其他方法不同,KS检验不需要知道数据的分布情况,可以算是一种非参数检验方法。
- 当然这样方便的代价就是当检验的数据分布符合特定的分布时,KS检验的灵敏度没有相应的检验来的高。在样本量比较小的时候,KS检验在为非参数检验在分析两组数据之间是否不同时,是相当常用。
- 虽然KS检验的定义中说检验的数据必须是连续的,若在非连续数据上用KS检验检验的显著性回下降,想要获得准确值就需要用其他检验,比如chi-square goodness-to-fit 但在实际操作中,如果离散分布的数据够多的话,用KS检验的显著性不会有太大影响,可以比较放心使用。
→ KS检验的参数解释:
- KS检验会返回两个值,D值和p值。
- D值:表示两个分布之间最大距离,即系D值越小,表示两个分布的差距越小,分布也就越一致。
- p值:表示假设检验中的p值,因为原假设为“待检验的两个数据的分布一致”,即系若p值>0.05(p值的设定取决于实际要求),那么就不能拒绝原假设,即系“待检验的两个数据分布一致”这个假设成立。
# 设置cell多行输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all' #默认为'last'
# 导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
os.chdir(r'E:\python_learn\train')
# 读取数据
file_name = 'data_abnormal.csv'
data = pd.read_csv(file_name,usecols=['key1','key2','key3'])
print(data.head())
key1 key2 key3
0 171.478895 31.816106 -235.872855
1 38.145928 -44.222959 -45.868820
2 -14.594276 7.455609 -39.576063
3 118.362921 15.007191 83.177483
4 -5.589237 114.340285 135.983500
# 直接用算法做KS检验
from scipy import stats
# 创建函数
def f(x):
return stats.kstest(x,'norm',(x.mean(),x.std()))
# .kstest方法:KS检验,参数分别是:待检验的数据,检验方法(这里设置成norm正态分布),均值与标准差
data_stats = data.apply(f) # 将算法直接映射到每一列
data_stats.values
# 结果返回两个值:statistic → D值,pvalue → P值
# p值大于0.05,为正态分布
array([KstestResult(statistic=0.009734859311949784, pvalue=0.7305177443558707),
KstestResult(statistic=0.008796876410950949, pvalue=0.8338347831965152),
KstestResult(statistic=0.013374626202709239, pvalue=0.3327578473536996)],
dtype=object)
从所返回的D值和p值得出,数据集每列数据都符合正态分布的规律,因此可以使用3σ进行异常值检测。
第二步:3σ检测异常值和异常值处理
公式: |x - μ| >3σ为异常值,也就是说一组测定值与其平均值的差的绝对值超过3倍标准差值即为异常值
# 数据缺失值查看
print(data.head())
data.isna().sum()
data.isna().sum().sum() # → 不存在缺失值
key1 key2 key3
0 171.478895 31.816106 -235.872855
1 38.145928 -44.222959 -45.868820
2 -14.594276 7.455609 -39.576063
3 118.362921 15.007191 83.177483
4 -5.589237 114.340285 135.983500
key1 0
key2 0
key3 0
dtype: int64
0
# 筛出异常值
df = data.copy() # 复制一份数据
lst = []
cols = df.columns
for col in cols:
df_col = df[col]
err = df_col[np.abs(df_col-df_col.mean())>3*df_col.std()] # 筛出异常数据
lst.append(err)
err_data = pd.concat(lst)
print('一共检测到异常值共:%i'%len(err_data),'\n')
print('异常值展示前10条:\n',err_data.head(10))
一共检测到异常值共:43
异常值展示前10条:
197 318.319213
1319 331.880033
2074 -416.500736
2109 300.174181
2922 -488.395881
3182 360.454103
3793 324.765684
3863 335.669291
4096 -307.131874
4272 -310.307727
dtype: float64
# 将异常值替换为NaN,并插补补全
normal = df[np.abs(df-df.mean())<3*df.std()] # 异常值是|x - μ| >3σ,反之小于3σ的值为正常
# 返回一个已用NaN替换掉异常值的DataFrame
normal.isna().sum() # 查看是否有空值 → 存在缺失值,表示已将异常值替换为NaN
normal.isna().sum().sum()
df_clean = normal.fillna(normal.median()) # 使用中位数插补
df_clean.isna().sum()
df_clean.isna().sum().sum() # 检查空值是否已处理
key1 11
key2 11
key3 21
dtype: int64
43
key1 0
key2 0
key3 0
dtype: int64
0
以上就是3σ原则检测异常值的操作过程
方法2 → 箱形图
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。
箱形图的六个数据节点:
- 上四分位数(Q1)
- 中位数(Q2)
- 下四分位数(Q3)
- 四分位距(IQR):IQR = Q3-Q1
- 上限(最大值区域):Q3+1.5IQR
- 下限(最小值区域):Q1-1.5IQR
- 异常值,被定义为小于Q1-1.5IQR或大于Q3+1.5IQR的值
箱形图的作用:
-
① 识别数据的异常值
- 箱型图的异常值被定义为小于Q1-1.5IQR或大于Q3+1.5IQR的值
- 3σ原则需要以数据服从正态分布为前提,但实际数据往往不能严格服从正态分布,且其判断异常值的标准以计算数据的均值和标准差为基础,而均值和标准差耐抗性较小,异常值本身对他们影响就较大,因此产生的异常值个数不会多于总数的0.7%。
- 但箱型图与值对比其优势是,不需事先假定数据服从特定的分布,没有对数据做限制要求,真实直观低呈现数据本来面貌,且箱型图以四分位数和四分位距作为基础,具有一定耐抗性,箱形图识别异常值的结果比较客观。
-
② 易于发现数据的偏态和尾重
- 标准正态分布的样本,只有0.7%的值是异常值,中位数位于上下四分位数的中央,箱型图的方盒关于中位线对称。
- 异常值集中在较大值一侧,则分布呈现右偏态;;异常值集中在较小值一侧,则分布呈现左偏态。尽管不能给出偏态和尾重程度的精确度量,但可作为粗略估计的依据。
-
③ 能用于数据性探索分析,分析数据的形状
- 多组数据箱型图并排对比,能一目了然的查看中位数,尾长,异常值,分布区间等信息。
print(data.head()) # 原始数据展示
# 查看缺失值
data.isna().sum()
data.isna().sum().sum() # → 不存在缺失
key1 key2 key3
0 171.478895 31.816106 -235.872855
1 38.145928 -44.222959 -45.868820
2 -14.594276 7.455609 -39.576063
3 118.362921 15.007191 83.177483
4 -5.589237 114.340285 135.983500
key1 0
key2 0
key3 0
dtype: int64
0
# 箱型图查看数据
color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray') # 颜色设置
box=df2.plot.box(figsize=(12,8),return_type='dict',color=color)
plt.title('异常值检测-箱型图',fontsize=14,pad=12)
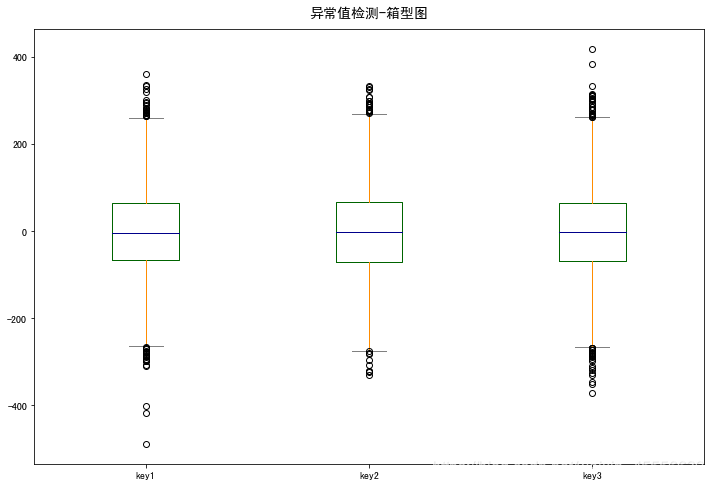
从箱型图反映的情况可知,每列数据都存在异常值的情况。
# 筛出异常值
df2 = data.copy() # 复制一份数据
lst = []
cols = df2.columns
for col in cols:
df2_col = df2[col]
q1 = df2_col.quantile(0.25)
q3 = df2_col.quantile(0.75)
iqr = q3-q1
ma = q3+iqr*1.5
mi = q1-iqr*1.5
error = df2_col[(df2_col>ma) | (df2_col<mi)] # 筛出异常
lst.append(error)
err_data = pd.concat(lst)
print('一共检测到异常值共:%i'%len(err_data),'\n')
print('异常值展示前10条:\n',err_data.head(10))
一共检测到异常值共:130
异常值展示前10条:
85 -296.923702
197 318.319213
344 -268.979898
461 266.571340
609 -294.773187
615 -278.354103
819 293.908994
860 -275.333416
946 -269.933060
1232 278.143495
dtype: float64
# 处理异常值 → 替换为NaN,并以插值方法处理
Q1 = df2.quantile(0.25)
Q3 = df2.quantile(0.75)
IQR = Q3-Q1
Max = Q3+IQR*1.5
Min = Q1-IQR*1.5
data_nor = df2[(df2 >= Min) & (df2 <= Max)] # 将正常的数据按数据框形式筛选出来,返回一个已用NaN替换掉异常值的DataFrame
data_nor.isna().sum()
data_nor.isna().sum().sum()
# 插值处理NaN
data_clean = data_nor.fillna(data_nor.median())
data_clean.isna().sum() # 确认缺失值已处理
key1 45
key2 32
key3 53
dtype: int64
130
key1 0
key2 0
key3 0
dtype: int64
以上就是箱型图检测异常值的操作过程*
