近日 Meta 发布了一个名为 Segment Anything Model(SAM)的 AI 模型,可以识别图像和视频中的单个物体,甚至是训练中没有遇到的物体。除此之外,Meta 还发布了 Segment Anything 1-Billion mask 数据集(SA-1B),这更是有史以来发布的最大分割数据集。
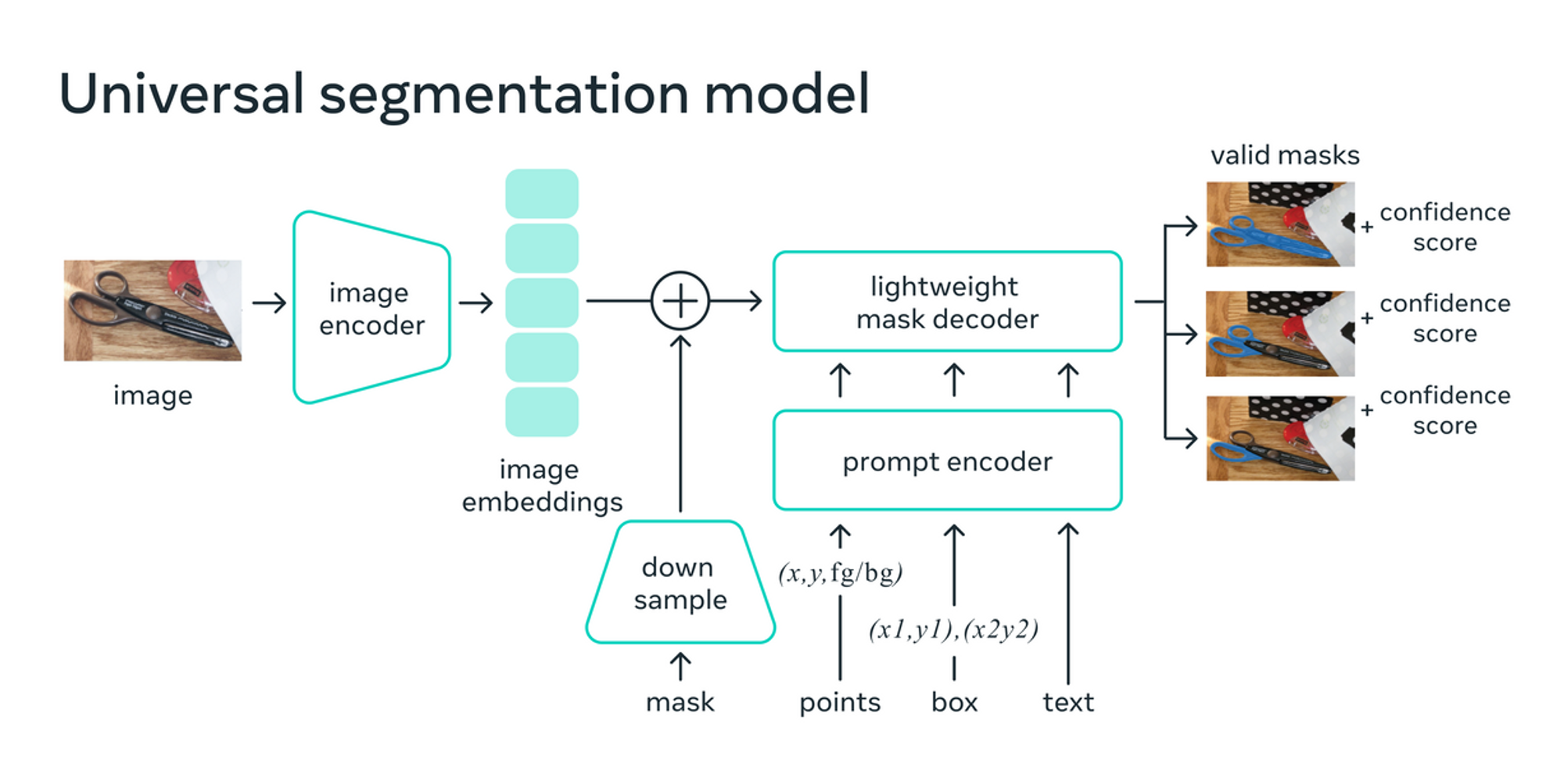
SAM 是一个图像分割模型,可以对文本提示或用户点击做出反应,在图像中分离出特定的物体。目前为特定用例创建准确的分割模型是大多数 AI 无法完成的任务,因为它需要技术专家进行高度专业化的工作,并需要获得极其强大的 AI 训练基础设施和大量有注释和特定领域的数据集。
Meta 则表示,上述这些难题都是 SAM 和 SA-1B 能够克服的问题,通过减少对特定任务的建模专业知识、训练计算和定制数据注释的需求来帮助研究人员。

SAM 模型可以为图像或视频中的任何物体生成 "遮罩",甚至是它以前没有遇到过的物体和图像。遮罩是一种技术,包括根据物体边缘的对比度变化来识别物体,并将其与场景的其他部分分开。Meta公司的研究人员说,SAM 的通用性足以覆盖广泛的用例,并且不需要再进行额外的训练。
SAM 结合了交互式分割和自动分割两种常见的分割方法,前者是人类通过迭代完善一个遮罩来指导模型,后者是模型在经过数百或数千个注释对象的训练后自行完成。
用于训练 SAM 的 SA-1B 图像数据集目前包含超过 11 亿个分割遮罩,这些遮罩是从 1100 万张已经获得许可,并且保护隐私的图像中收集的,它的遮罩数量也是任何现有数据集的 400 倍。
Meta 的人工智能研究人员表示:
SAM 可以成为 AR/VR、内容创作、科学领域和更普遍的 AI 系统等领域的一个强大组件。当我们展望未来时,我们看到在像素层面理解图像和更高层次的视觉内容语义理解之间的紧密耦合,释放出更强大的 AI 系统。
相比于其他模型,SAM 所面临的挑战是训练这样的一个模型,它所需的数据在网上或其他任何地方都无法获得,而文本、图像和视频则不同,这些数据在网上都十分丰富。
目前 SAM 的相关代码都以 Apache 2.0 许可上传至 GitHub,Meta 还创建了交互式的 Demo,感兴趣的用户可以尝试一下。