CVPR2023的Occupancy Prediction比赛的前五名开源方案分析总结。
第一次参加CVPR的比赛,没有太多的比赛经验,以此文来总结一下大佬们开源出来的比赛方案,并提出一些自己的思考,欢迎评论区进行交流。
Occupancy Prediction任务描述
3D Occupancy Prediction(Occ)是Telsa在2022 AI Day里提出的检测任务,任务的提出是认为此前的3D目标检测所检测出的3D目标框,不足描述一般物体(数据集中没有的物体),在此任务中,则把物体切分成体素进行表达,要求网络可以在3D体素空间中,预测每个体素的类别,可以认为是语义分割在3D体素空间的扩展任务,具体预测图如下图所示。
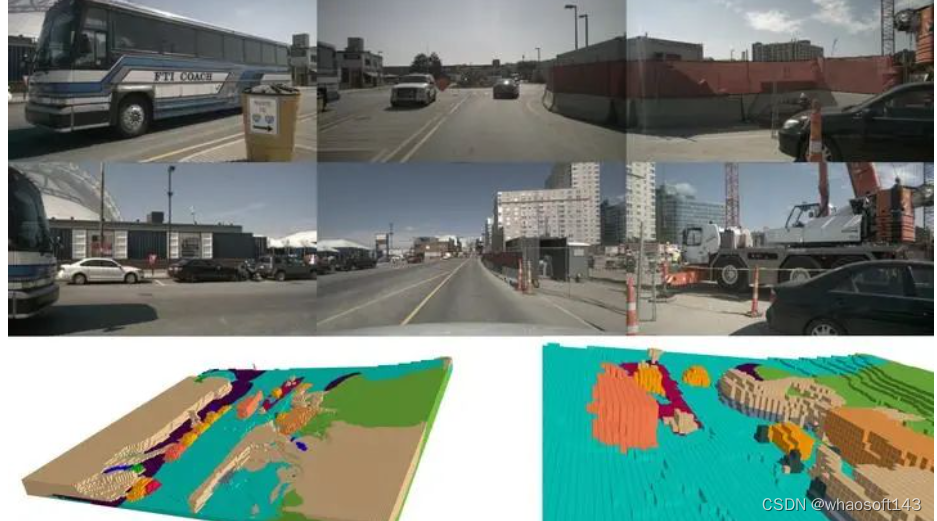 来源:https://github.com/NVlabs/FB-BEV
来源:https://github.com/NVlabs/FB-BEV
在本次比赛中,Occ数据集基于Nuscenes数据集进行构建,要求选手在仅使用图像这个模态的情况下,对200x200x16的3D体素空间的占据情况进行预测,其中评价指标采用MIoU,并且将仅对图像中的可视范围中的预测结果进行评估:

更详细的规则可以看看官方的GitHub:
https://github.com/CVPR2023-3D-Occupancy-Prediction/CVPR2023-3D-Occupancy-Prediction
Baseline介绍
在比赛中,一共有两个Baseline可供选择,一个是官方提供的基于BEVFormer框架的实现,另一个则是基于BEVDet框架实现的,也分别代表了在3D目标检测现在主流的两个实现路线,LSS和Transfromer。
两种Baseline都将原来输入检测头的特征,从BEV空间拉伸成200x200x16的3D体素空间,然后接上一个简单的语义分割头,来对3D占据的结果进行预测,具体性能表现如下表所示:
| Method | mIoU |
|---|---|
| BEVFormer-R101 | 23.67 |
| BEVDet-R50-256x704 | 36.1 |
| BEVDet-R50-384x704 | 37.3 |
| BEVDet-R50-Longterm-384x704 | 39.3 |
| BEVDet-STBase-512x1024 | 42.0 |
从官方及开源的Baseline中可以发现几个比较明显的提分方法:
-
更大的输入分辨率
-
利用更多的时序信息
-
使用更先进的Backbone来提取特征
其中官方的BEVFormer之所以和BEVDet差距比较大的原因在于,其在训练时没有使用mask camera,也就是其会计算图像可视范围外的损失,而BEVDet在训练时是不计算的,可以从第五名的消融实验中看出此原因。
接下来,将对前五名开源方法进行介绍,如有说的不对的地方,请在评论区指正!
FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation
第一名团队来自NVIDIA,其整体构建的框架并没有采用LSS和BEVFormer,而是基于NVIDIA自己开发的一套框架FB-BEV,目前其代码还为开源,也没有详细的论文介绍FB-BEV。下面,将从网络结构的设计,网络模型的扩大以及预训练的应用和后处理部分进行介绍
本次比赛的开源论文如下:
https://opendrivelab.com/e2ead/AD23Challenge/Track_3_NVOCC.pdf
网络结构设计
下面是个人对FB-BEV及FB-OCC网络的初步理解,欢迎在评论区交流。
对于BEV空间的生成,可以认为LSS是前向生成的过程,在前向推理时通过深度的估计,就可以生成一个粗略的BEV特征,而BEVFormer则是通过BEV queries的形式来生成BEV特征,在前向时这个BEV queries是未知的,是人为随意定义的,其BEV特征真正的生成,是通过反向传播模型学习来的。
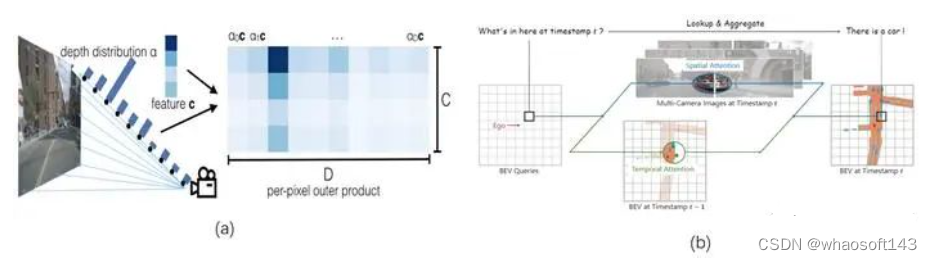 (a)LSS生成lift生成BEV空间;(b)BEVFormer使用BEV queries生成BEV空间
(a)LSS生成lift生成BEV空间;(b)BEVFormer使用BEV queries生成BEV空间
而FB-BEV则是结合了两者的优劣,设计了既包含前向又包含反向的BEV空间特征生成方法:由于LSS方法中对于深度估计是离散的,故其生成的3D空间特征也是较为稀疏的,而BEVFormer中BEV queries就不存在这个问题,但原先随机初始化的BEV queries会存在不好优化的问题,故FB-BEV利用LSS中生成的3D体素空间,来作为BEV queries的初始值,使其可以更好的优化,最后将两部分的特征进行融合,使网络对于3D空间有更好的精细化描述,其具体结构如下图所示。
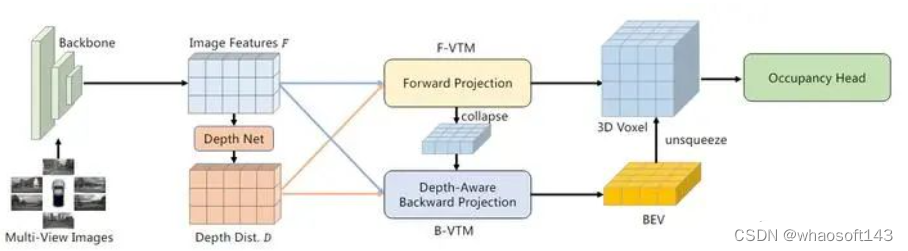 FB-OCC结构图,F-VTM表示前向BEV生成,类似LSS,B-VTM则表示反向BEV生成,类似BEVFormer
FB-OCC结构图,F-VTM表示前向BEV生成,类似LSS,B-VTM则表示反向BEV生成,类似BEVFormer
在最后,作者利用了多尺度的预测融合的预测方式,来设计占据检测头,具体结构如下图:
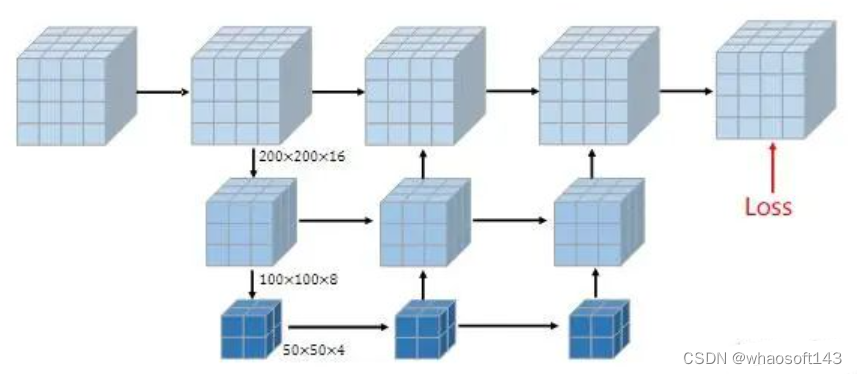 Occupancy Head结构图
Occupancy Head结构图
扩大模型及预训练应用
使用更好更大的模型,无疑是增加网络性能最简单粗暴的方法,但过大的模型有可能会在Nuscenes上造成过拟合等问题,最后,作者利用前段时间霸榜各大榜单的InterImage-H来作为他们的Backbone,而为了更好的应用InterImage-H,作者还将其在原先在COCO的预训练基础上,在object365上也进行了预训练,使其更好的应用在此任务上。
但就这么应用预训练模型,仅仅是Backbone层面的,对于网络的感知能力提升其实并没有很大,于是作者就想将网络在Nuscenes上进行深度估计的预训练,但单纯的深度估计任务的训练,又会导致预训练模型中的权重偏向于此任务,同样不利于感知任务,于是就将网络在深度估计和2D语义分割联合任务中进行预训练来达到提升预训练模型感知能力的效果。
但Nuscenes数据集是没有提供图片的2D语义分割标签的,所以作者就利用了最近很火的SAM来进行自动标注,并利用Nuscenes中检测框和点云分割的标签来生成更加精确的mask,预训练示意图如下图所示:

深度估计及2D语义分割联合预训练图
(其实这里我个人认为如果嫌麻烦,可以使用深度估计和3D目标检测任务或者2D目标检测任务进行联合训练,来达到差不多的效果,但由于2D语义分割其实和3D占据任务很相似,所以有可能效果会更好)
后处理
后处理中,和一些经典比赛中的策略不同的是,作者在TTA中还加入了时序的TTA操作,具体操作个人猜测就是在前向时使用不同数量的时序帧来TTA。
另外,作者观察到在同一个场景下,网络对于远处的识别效果并不如近景好,所以可以把近处中静止的物体预测结果固定起来,当车辆走到远处时,原来近景就变成了远景,则可以将静止的物体预测结果进行替换。
最后其融合结果在测试集上达到54.19%效果,在本次比赛也是毫无对手了,个人认为其对于预训练模型的思考相比于网络的结构设计而言,更值得学习和思考。
MiLO: Multi-task Learning with Localization Ambiguity Suppression for Occupancy Prediction
第二名团队来自42dot自动驾驶公司,其网络框架则整体采用了BEVDet进行开发。由于其对网络结构的改进不大,所以主要从以下两部分进行介绍,分别是多任务训练和后处理设计。
本次比赛的开源论文如下:
https://opendrivelab.com/e2ead/AD23Challenge/Track_3_42dot.pdf
多任务训练
这里多任务的训练思想其实和第一名对于预训练模型的应用目的是一样的,就是为了更好的优化网络,由于BEVDet整体框架在多个视角下进行变换(2D,2D-3D, 3D),如果只在最后的输出特征进行监督训练,难以很好的对底层的网络进行优化,这个问题在PANet中同样提到过。于是作者在2D的FPN部分,引入新的分支来做2D的语义分割任务,来监督2D部分网络的优化,而2D-3D和3D则采用了和BEVDet相同的深度监督以及3D占据任务监督。
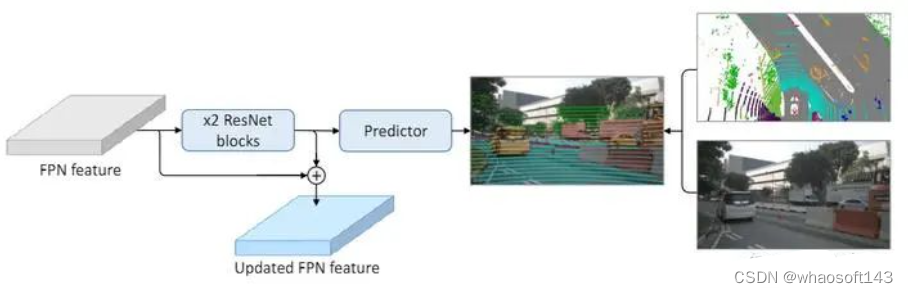 在FPN后接入两层ResNet去做2D语义分割,并利用此特征来更新FPN的特征,送入2D-3D网络
在FPN后接入两层ResNet去做2D语义分割,并利用此特征来更新FPN的特征,送入2D-3D网络
这里作者并没有使用第一名中较为复杂的方法生成2D图像中的语义分割标签,而是直接把点云分割的标签投影到图像空间中,并且计算loss时也只会对这些点进行计算。
后处理
作者注意到从图像中进行定位是比较模糊的,如下图所示,在一定区域内确实是预测到了行人,但其预测的具体位置却是模糊的。
 作者然后分析了自己的预测结果,设置了6种不同距离,并观察6种不同距离上的mIoU表现,发现有些类别,如bicycle和motorcycle等,在最远处的mIoU几乎等于0。于是作者根据推理观察和在验证集上的测试等,为6种不同的距离设置了不同的阈值,若预测的分数低于此阈值,则将其类别设置为free类,来缓解此问题。
作者然后分析了自己的预测结果,设置了6种不同距离,并观察6种不同距离上的mIoU表现,发现有些类别,如bicycle和motorcycle等,在最远处的mIoU几乎等于0。于是作者根据推理观察和在验证集上的测试等,为6种不同的距离设置了不同的阈值,若预测的分数低于此阈值,则将其类别设置为free类,来缓解此问题。
最后其结果在测试集上达到了52.45%的成绩,由1、2名的成功,不论是对于2D语义分割的预训练还是引入多任务训练,2D任务的引入,可以更好的优化此任务下的网络。
UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
第三名团队来自小米汽车,其在不使用标签数据,单模型的情况下拿到51.27%的成绩,可以认为别人只是来玩玩的而已了。其并没有拘泥于LSS或者BEVFormer的框架形式,而是针对此任务提出一些plug-and-play的东西来提升网络效果。
本次比赛的开源论文如下:
https://opendrivelab.com/e2ead/AD23Challenge/Track_3_UniOcc.pdf
其把3D占据任务认为是一种渲染问题,尝试使用NeRF的思路进行解决,并最后利用Teacher-Student的训练思路来对模型进行训练,在这里重点讲讲如何把3D占据认为转为NeRF的过程。
NeRF
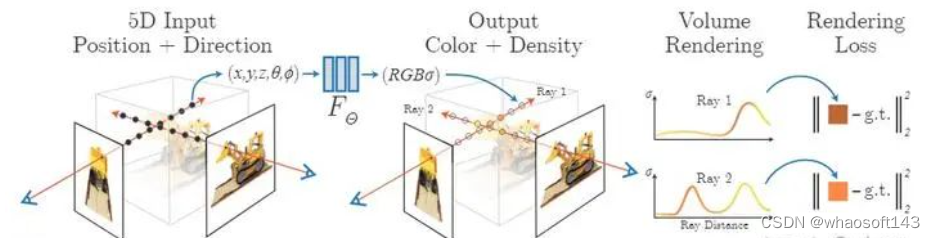 NeRF处理过程
NeRF处理过程


而由于计算资源的限制,NeRF并不能在一条光线上采样过多的点,但有时候,有些地方的点能提供的信息很少,甚至是空的,不利于网络的建模,比较理想的采样方法是在实体上点密集的地方多采样,所以提出了一种分层的采样方式,也可以认为是粗粒度和细粒度同时进行的采样方式:其首先先随机的在光线上进行采样,进行粗粒度的估计,而后根据估计结果,在密度较高的地方进行重新采样,得到细粒度的估计,而优化时则是粗粒度和细粒度同时进行优化,其细粒度得到的颜色值如下:
 From Occupancy to NeRF
From Occupancy to NeRF
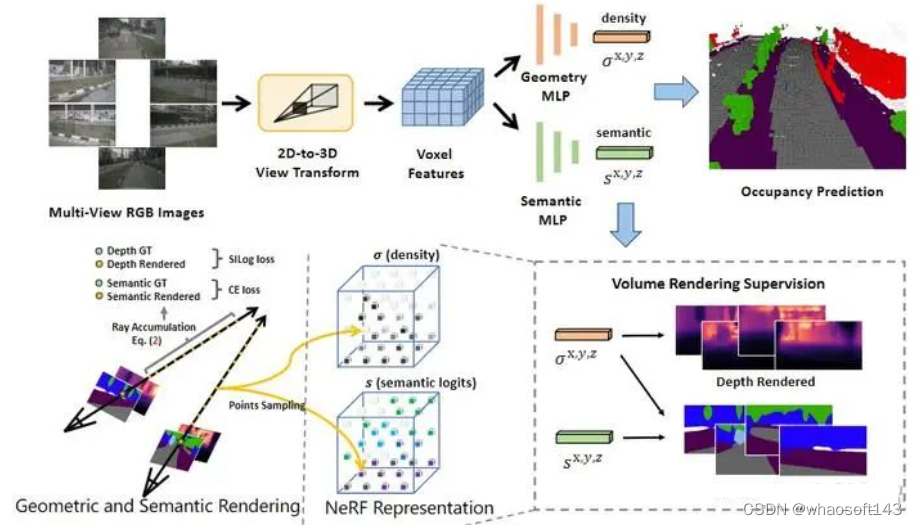 UniOcc整体框图
UniOcc整体框图

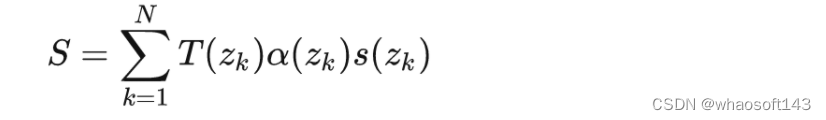 其中 βk=zk+1−zk\beta_{k}=z_{k+1}-z_{k}\beta_{k}=z_{k+1}-z_{k} ,也就是两个采样点直接的距离,通过几何信息和语义信息的渲染,则可以得到预测的3D占据情况。(本人对NeRF的理解还不是很好,有可能这里有讲解问题的地方)
其中 βk=zk+1−zk\beta_{k}=z_{k+1}-z_{k}\beta_{k}=z_{k+1}-z_{k} ,也就是两个采样点直接的距离,通过几何信息和语义信息的渲染,则可以得到预测的3D占据情况。(本人对NeRF的理解还不是很好,有可能这里有讲解问题的地方)
Multi-Scale Occ: 4th Place Solution for CVPR 2023 3D Occupancy Prediction Challenge
第四名来自上汽 AI LAB,其整体框架设计采用BEVDet的设计思路,主要提出利用多尺度信息来进行训练和预测以及一种解耦头的预测方法。
本次比赛的开源论文如下:
https://opendrivelab.com/e2ead/AD23Challenge/Track_3_occ-heiheihei.pdf
多尺度网络结构设计
其网络多尺度的设计,参考了SurroundOcc设计,其利用FPN建立多尺度的特征,然后利用不同尺度的特征去生成不同大小空间的3D体素特征,在这里使用了50x50x4,100x100x8和200x200x16这三个大小的体素空间,最后利用3D UNet的形式去融合不同尺度的特征来预测3D占据情况,训练时不同尺度的信息都将计算loss。
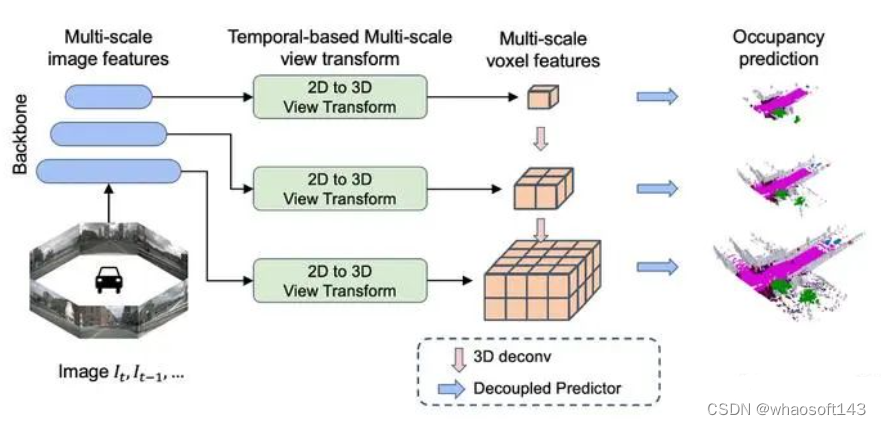 解耦头设计
解耦头设计
由于在此任务中,存在比较明显的类别不平衡问题,Free类别在训练集中就占据了96%的数量,为了解决此问题,作者将预测头进行解耦,分为是否是Free类的二分类头,还有其他16个类别的语义分割头两部分。二分类头采用BCE作为损失函数,而语义分割头则采用Focal loss来作为损失函数,最后总的损失函数如下:

OccTransformer: Improving BEVFormer for 3D camera-only occupancy prediction
第五名团队来自哈工大,其网络结构整体采用BEVFormer的设计思路,其网络设计主要在头部进行了3D UNet的改进,其他部分改动不大,不过其方法是所有方法中唯一使用了额外数据增强和结合3D目标检测进行后处理的方法。
本次比赛的开源论文如下:
https://opendrivelab.com/e2ead/AD23Challenge/Track_3_occ_transformer.pdf
数据增强
为了使模型发掘更多局部特征,作者对图像进行了cutout的数据增强操作来增强图像。
(其实这里我在比赛初期也尝试使用过额外的数据增强,但我们的框架整体借鉴于BEVDet,但在BEVDet论文中也谈及,单纯的在图像空间做数据增强,而不在BEV空间做增强,反而会降低网络的性能,所以一些尝试都失败了,在这里cutout等数据增强,也许也仅适用于BEVFormer框架)
模型融合后处理

作者发现,在动态物体上,3D目标检测的效果要好于3D占据任务的表现。所以作者利用StreamPETR去生成3D检测框,并将检测框转换成3D占据的形式。具体为,根据不同类别,设置不同的阈值,选择高置信度的检测框,并在框内生成间距为 ttt 的点云,并对点云进行体素化,然后根据预测的类别打上语义标签,最后,将此结果和Occ网络的预测结果进行融合。
总结
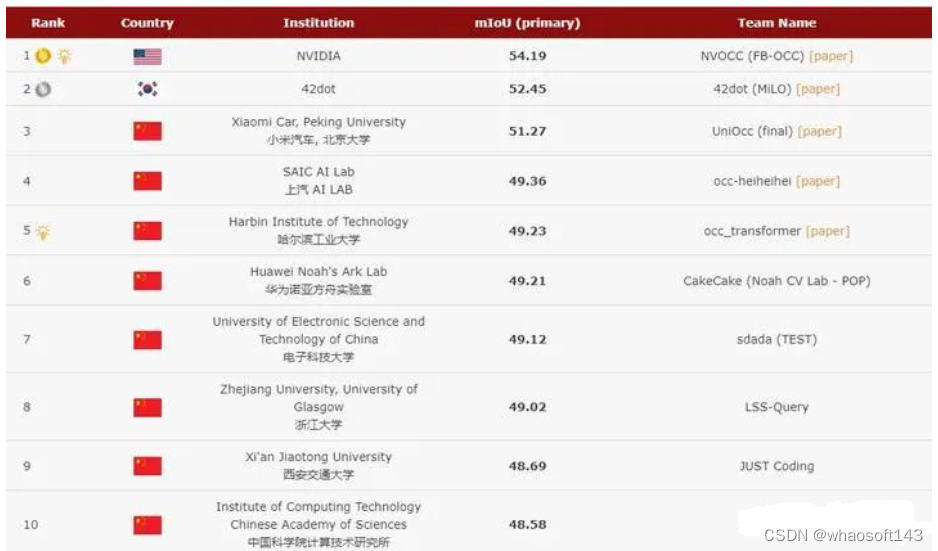
最后前10名榜单如下 whaosoft aiot http://143ai.com