什么是持久化?
持久化的意思就是说将RDD的数据缓存到内存中或者持久化到磁盘上,只需要缓存一次,后面对这个RDD做任何计算或者操作,可以直接从缓存中或者磁盘上获得,可以大大加快后续RDD的计算速度。
为什么要持久化?
在之前的文章中讲到Spark中有tranformation和action两类算子,tranformation算子具有lazy特性,只有action算子才会触发job的开始,从而去执行action算子之前定义的tranformation算子,从hdfs中读取数据等,计算完成之后,Spark会将内存中的数据清除,这样处理的好处是避免了OOM问题,但不好之处在于每次job都会从头执行一边,比如从hdfs上读取文件等,如果文件数据量很大,这个过程就会很耗性能。这个问题就涉及到本文要讲的RDD持久化特性,合理的使用RDD持久化对Spark的性能会有很大提升。
持久化带来的好处及原理
Spark可以将RDD持久化在内存中,当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD读取一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。
Spark 中一个很重要的能力是将数据持久化(或称为缓存),在多个操作间都可以访问这些持久化的数据。当持久化一个 RDD 时,每个节点的其它分区都可以使用 RDD在内存中进行计算,在该数据上的其他 action 操作将直接使用内存中的数据。这样会让以后的 action 操作计算速度加快(通常运行速度会加速 10倍)。
巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
如果不进行RDD持久化会有哪些影响
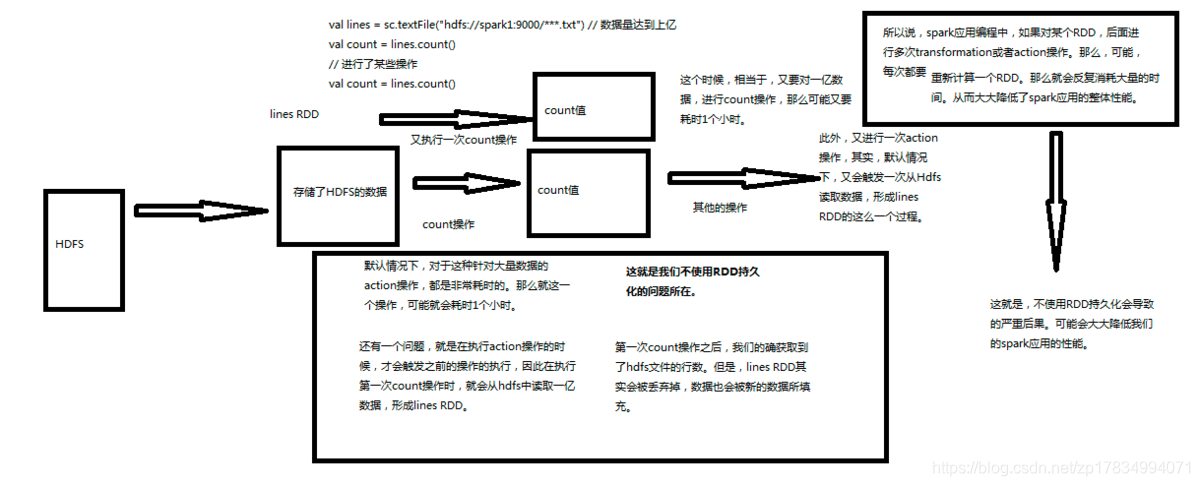
假设有一份文件,数据量很大,我们需要对这份文件做聚合操作,功能实现其实很简单,利用下面的代码就可以实现
val lines = sc.textFile("hdfs://spark1:9000/***.txt")
val count = lines.count()假设对这份文件做聚合操作之后我们又进行了某些操作,后面又需要对lines进行操作,看一下如果不使用RDD持久化会带来哪些问题.
默认情况下,针对大量数据的action操作是很耗时的。Spark应用程序中,如果对某个RDD后面进行了多次transmation或者action操作,那么,可能每次都要重新计算一个RDD,那么就会反复消耗大量的时间,从而降低Spark的性能。第一次统计之后获取到了hdfs文件的字数,但是lines RDD会被丢弃掉,数据也会被新的数据填充,下次执行job的时候需要重新从hdfs上读取文件,不使用RDD持久化可能会导致程序异常的耗时。
- 一般来说对于大量数据的action操作都是非常耗时的。可能一个操作就耗时1个小时;
- 在执行action操作的时候,才会触发之前的操作的执行,因此在执行第一次count操作时,就会从hdfs中读取一亿数据,形成lines RDD;
- 第一次count操作之后,我们的确获取到了hdfs文件的行数。但是lines RDD其实会被丢弃掉,数据也会被新的数据丢失;
- 所以,如果不用RDD的持久化机制,可能对于相同的RDD的计算需要重复从HDFS源头获取数据进行计算,这样会浪费很多时间成本;
如下图所示:
持久化带来的好处及工作原理
对lines RDD执行持久化操作之后,虽然第一次统计操作执行完毕,但不会清除掉lines RDD中的数据,会将其缓存在内存中,或者磁盘上。
第二次针对lines RDD执行操作时,此时就不会重新从hdfs中读取数据形成lines RDD,而是会直接从lines RDD所在的所有节点的内存缓存中,直接取出lines RDD的数据,对数据进行操作,那么使用了RDD持久化之后,只有在其第一次计算时才会进行计算,此后针对这个RDD所做的操作,就是针对其缓存了,就不需要多次计算同一个RDD,可以提升Spark程序的性能。
如下图所示:

RDD持久化的使用场景
RDD持久化虽然可以提高性能,但会消耗内存空间,一般用在如下场景:
- 第一次加载大量的数据到RDD中
- 频繁的动态更新RDD Cache数据,不适合使用Spark Cache、Spark lineage
如何对RDD进行持久化操作
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。
而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。
如果需要从内存中清除缓存,那么可以使用unpersist()方法。
Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。
RDD持久化是可以手动选择不同的策略的,默认是持久化到内存中的。还可以持久化到磁盘上,使用序列化的方式持久化,对持久化的数据进行复用,只要在调用persist()方法时传入对应的StorageLevel即可。
缓存(持久化)的方式
-
MEMORY_ONLY
数据全部缓存在内存中 -
MEMORY_ONLY_2
数据以双副本的方式缓存在内存中 -
MEMORY_ONLY_SER
数据全部以序列化的方式缓存到内存中 -
MEMORY_AND_DISK
数据一部分缓存在内存中,一部分持久化到磁盘上 -
MEMORY_AND_DISK_SER
数据以序列化的方式一部分缓存在内存中,一部分持久化到磁盘上 -
MEMORY_AND_DISK_2
数据以双副本的方式一部分缓存到内存中,一部分持久化到磁盘上 -
DISK_ONLY
数据全部持久化到磁盘上
缓存策略
-
持久化+可序列化
如果按照正常的策略将数据直接缓存到内存中,如果内存不够大的话就会导致内存占用过大,从而导致OOM(内存溢出)情况的出现。
针对这种情况,当内存无法支撑公共RDD数据完全存入内存的时候,就可以考虑将RDD数据序列化成一个大的字节数组(一个大的对象),就可以大大降低内存的占用率,由于序列化和反序列化需要消耗一定的性能,所以比直接持久化到内存的方式性能稍微差一些。 -
内存+磁盘+序列化
如果序列化纯内存方式,还是导致OOM,内存溢出;就只能考虑磁盘的方式,内存+磁盘的普通方式(无序列化)。如果还是不行的话,那么就采用内存+磁盘+序列化的方式缓存数据。 -
持久化+双副本机制
为了数据的高可靠性,而且内存充足,可以使用双副本机制进行数据持久化,这种方式可以保证持久化数据的安全性。因为如果只有一个副本,机器宕机缓存数据就会丢失,那么就会导致还得重新计算一次;
持久化的每个数据单元,如果有两个副本,另一个副本存储放在其他节点上面;从而进行容错;一个副本丢了,不用重新计算,还可以使用另外一份副本。这种方式,仅仅针对你的内存资源极度充足。
通过上面的几个概念介绍,我相信大家应该明白了该如何选取缓存策略了吧.
RDD持久化策略选择
- 优先使用MEMORY_ONLY,如果可以缓存所有数据的化,那么就使用这种级别,纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
- 如果MEMORY_ONLY策略无法存储所有的数据的化,使用MEMORY_ONLY_SER,将数据进行序列化存储,节约空间,纯内存操作速度块,只是需要消耗cpu进行反序列化.
- 如果需要进行快速的失败恢复,选择带后缀为2的策略,进行数据的备份,这样节点在失败时不需要重新计算。
- 能不使用DISK相关的策略就不使用,有时从磁盘读取的速度还不如重新计算来的快。
RDD的缓存机制
当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。
RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false)
.......
}
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
extends Externalizable {
def useDisk: Boolean = _useDisk
def useMemory: Boolean = _useMemory
def useOffHeap: Boolean = _useOffHeap
def deserialized: Boolean = _deserialized
def replication: Int = _replication
......
}可以看到StorageLevel类的主构造器包含了5个参数:
-
useDisk:使用硬盘(外存)
-
useMemory:使用内存
-
useOffHeap:使用堆外内存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
-
deserialized:反序列化,其逆过程序列化(Serialization)是java提供的一种机制,将对象表示成一连串的字节;而反序列化就表示将字节恢复为对象的过程。
-
serialization:序列化是对象永久化的一种机制,可以将对象及其属性保存起来,并能在反序列化后直接恢复这个对象。序列化方式存储对象可以节省磁盘或内存的空间,一般
序列化:反序列化=1:3 -
replication:备份数(在多个节点上备份)
理解了这5个参数,StorageLevel 的12种缓存级别就不难理解了。
另外还注意到有一种特殊的缓存级别:
val OFF_HEAP = new StorageLevel(false, false, true, false)
使用了堆外内存,StorageLevel 类的源码中有一段代码可以看出这个的特殊性,它不能和其它几个参数共存。
RDD是如何进行缓存的
- rdd.cache操作和 rdd.persist操作,通过这两个操作就能够缓存RDD的数据
- rdd缓存操作也是懒加载的,也是有action算子进行触发
- rdd数据缓存以后,后续在使用这个RDD的时候其运行速度要比第一次rdd创建时候速度要快至少10倍
rdd.cache与 rdd.persist比较
cache和persist实际上是一个方法都是调用的 persist(StorageLevel.MEMORY_ONLY);
cache()和persist()的区别在于,cahe()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本。
注意:
cache()或者persist()的使用,是有规则的:
-
必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以;
如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的。而且,会报错,大量的文件会丢失。 -
cache之后一定不能立即有动作算子,不能直接去接算子,必须创建一个变量去接收,再调用动作算子;因为在实际工作的时候,cache后有算子的话,它每次都会重新触发这个计算过程。
RDD的12种缓存级别
1. 不使用缓存
val NONE = new StorageLevel(false, false, false, false)
2. 仅仅缓存到磁盘
val DISK_ONLY = new StorageLevel(true, false, false, false)
3. 缓存到磁盘并且备份
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
4. 缓存到内存当中 默认常用
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
5. 缓存到内存当中并且备份
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
6. 缓存到内存当中并且序列化
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
7. 缓存到内存当中并且序列化 备份
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
8. 缓存到内存当中和磁盘 常用
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
9. 缓存到内存当中和磁盘 备份
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
10. 缓存到内存当中和磁盘 序列化 常用
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
11. 缓存到内存当中和磁盘 序列化 备份
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
12. 堆外内存
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
注意:
- RDD的缓存也是分布式的,每个节点只缓存其当前节点的数据。
- 释放资源rdd.unpersist
- RDD使用内存和磁盘缓存,使用内存可能会被JVM垃圾回收。使用磁盘可能会损坏或者被人为删除掉。