spark RDD持久化
简介
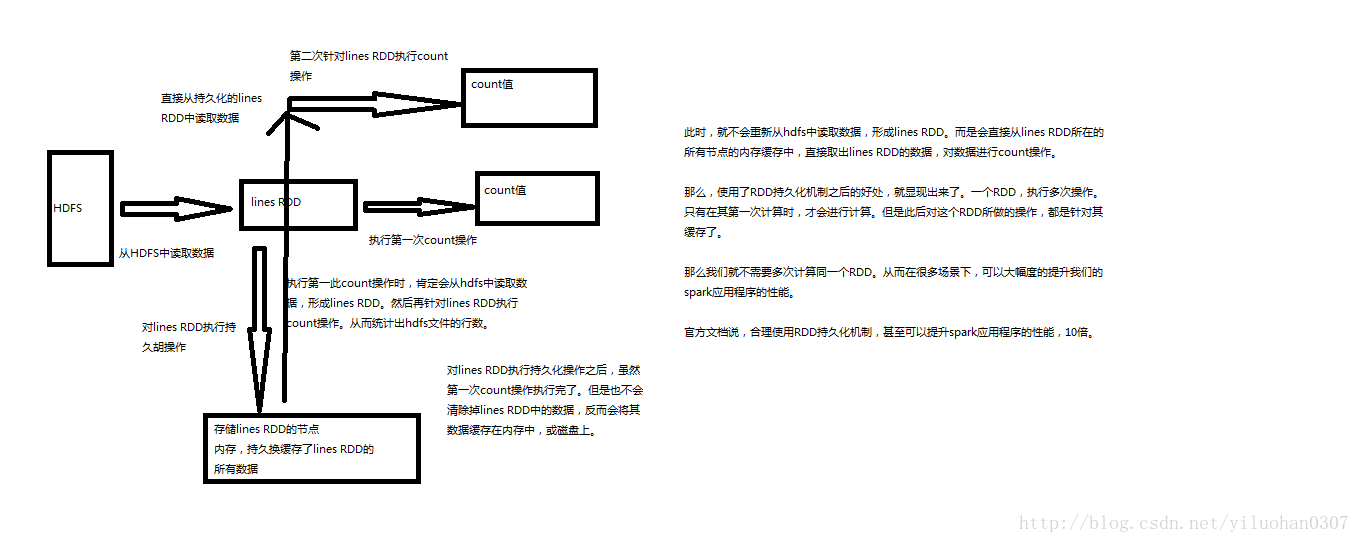
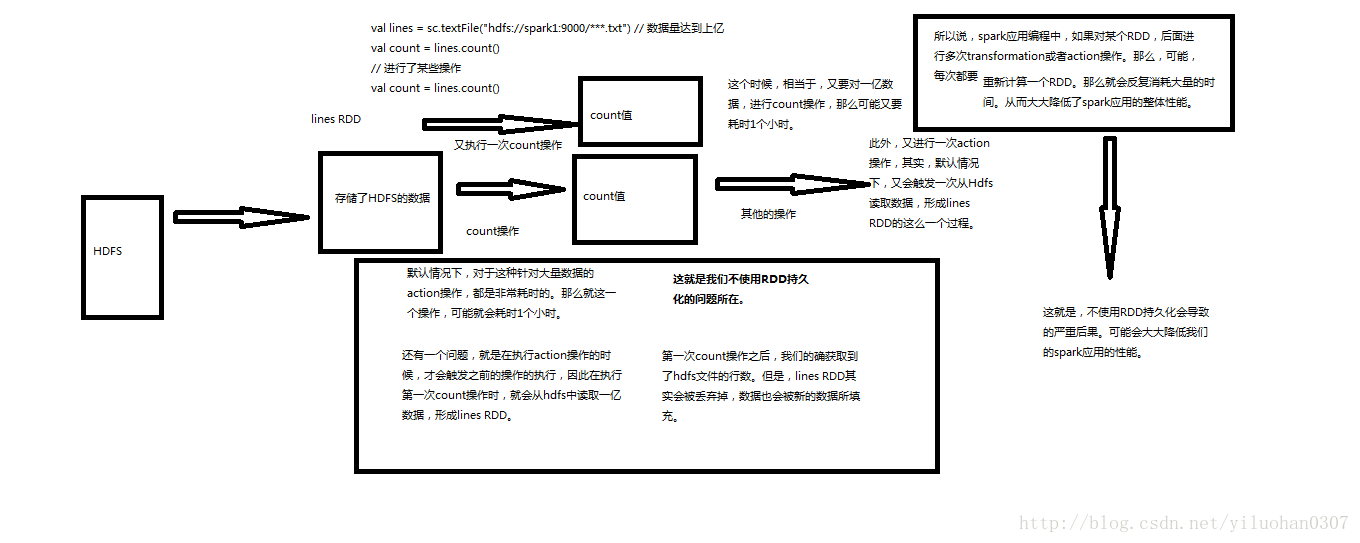
spark是分布式基于内存的数据处理引擎,它的一个基本功能是将RDD持久化到内存中。巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
cache和persist
spark有cache和persist两种方持久化方法。
# RDD.scala部分源码
/**
* Set this RDD's storage level to persist its values across operations after the first time
* it is computed. This can only be used to assign a new storage level if the RDD does not
* have a storage level set yet. Local checkpointing is an exception.
*/
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
// This means the user previously called localCheckpoint(), which should have already
// marked this RDD for persisting. Here we should override the old storage level with
// one that is explicitly requested by the user (after adapting it to use disk).
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
}
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
/**
* Mark the RDD as non-persistent, and remove all blocks for it from memory and disk.
*
* @param blocking Whether to block until all blocks are deleted.
* @return This RDD.
*/
def unpersist(blocking: Boolean = true): this.type = {
logInfo("Removing RDD " + id + " from persistence list")
sc.unpersistRDD(id, blocking)
storageLevel = StorageLevel.NONE
this
}从spark的源码中可以看出,cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中,persist方法可以手工设定StorageLevel来满足工程需要的存储级别。如果需要从内存中清楚缓存,都使用unpersist()方法。cache或者persist并不是action。
持久化级别
从StorageLevel的源码中我们可以将持久化级别分为以下几种:
# StorageLevel.scala部分源码
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
.
.
.可以看到这里列出了12种缓存级别,但这些有什么区别呢?可以看到每个缓存级别后面都跟了一个StorageLevel的构造函数,里面包含了4个或5个参数,如下
val MEMORY_ONLY = new StorageLevel(false, true, false, true)# StorageLevel.scala部分源码
/**
* :: DeveloperApi ::
* Flags for controlling the storage of an RDD. Each StorageLevel records whether to use memory,
* or ExternalBlockStore, whether to drop the RDD to disk if it falls out of memory or
* ExternalBlockStore, whether to keep the data in memory in a serialized format, and whether
* to replicate the RDD partitions on multiple nodes.
*
* The [[org.apache.spark.storage.StorageLevel$]] singleton object contains some static constants
* for commonly useful storage levels. To create your own storage level object, use the
* factory method of the singleton object (`StorageLevel(...)`).
*/
@DeveloperApi
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
extends Externalizable {
// TODO: Also add fields for caching priority, dataset ID, and flushing.
private def this(flags: Int, replication: Int) {
this((flags & 8) != 0, (flags & 4) != 0, (flags & 2) != 0, (flags & 1) != 0, replication)
}
def this() = this(false, true, false, false) // For deserialization
def useDisk: Boolean = _useDisk
def useMemory: Boolean = _useMemory
def useOffHeap: Boolean = _useOffHeap
def deserialized: Boolean = _deserialized
def replication: Int = _replication
.
.
.可以看到StorageLevel类的主构造器包含了5个参数:
- useDisk:使用硬盘(外存)
- useMemory:使用内存
- useOffHeap:使用堆外内存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
- deserialized:反序列化,其逆过程序列化(Serialization)是java提供的一种机制,将对象表示成一连串的字节;而反序列化就表示将字节恢复为对象的过程。序列化是对象永久化的一种机制,可以将对象及其属性保存起来,并能在反序列化后直接恢复这个对象
- replication:备份数(在多个节点上备份)
理解了这5个参数,StorageLevel 的12种缓存级别就不难理解了。
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)就表示使用这种缓存级别的RDD将存储在硬盘以及内存中,使用序列化(在硬盘中),并且在多个节点上备份2份(正常的RDD只有一份)
持久化级别总结
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算。 |
| MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取。 |
| MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销。 |
| MEMORY_AND_DSK_SER | 同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象 |
| DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上。 |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2等等 | 如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可。 |
| OFF_HEAP(experimental) | RDD的数据序例化之后存储至Tachyon。相比于MEMORY_ONLY_SER,OFF_HEAP能够减少垃圾回收开销、使得Spark Executor更“小”更“轻”的同时可以共享内存;而且数据存储于Tachyon中,Spark集群节点故障并不会造成数据丢失,因此这种方式在“大”内存或多并发应用的场景下是很有吸引力的。需要注意的是,Tachyon并不直接包含于Spark的体系之内,需要选择合适的版本进行部署;它的数据是以“块”为单位进行管理的,这些块可以根据一定的算法被丢弃,且不会被重建。 |
如何选择RDD持久化策略?
Spark提供的多种持久化级别,主要是为了在CPU和内存消耗之间进行取舍。下面是一些通用的持久化级别的选择建议:
1、优先使用MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
2、如果MEMORY_ONLY策略,无法存储的下所有数据的话,那么使用MEMORY_ONLY_SER,将数据进行序列化进行存储,纯内存操作还是非常快,只是要消耗CPU进行反序列化。
3、如果需要进行快速的失败恢复,那么就选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了。
4、能不使用DISK相关的策略,就不用使用,有的时候,从磁盘读取数据,还不如重新计算一次。
RDD持久化的例子
object sparkStudy {
def main(args: Array[String]) {
/*
*RDD持久化
* cache()或者persist()的使用,是有规则的
* 必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以
* 如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的
* 而且,会报错,大量的文件会丢失
*/
val conf = new SparkConf().setAppName("persist").setMaster("local")
val sc = new SparkContext(conf)
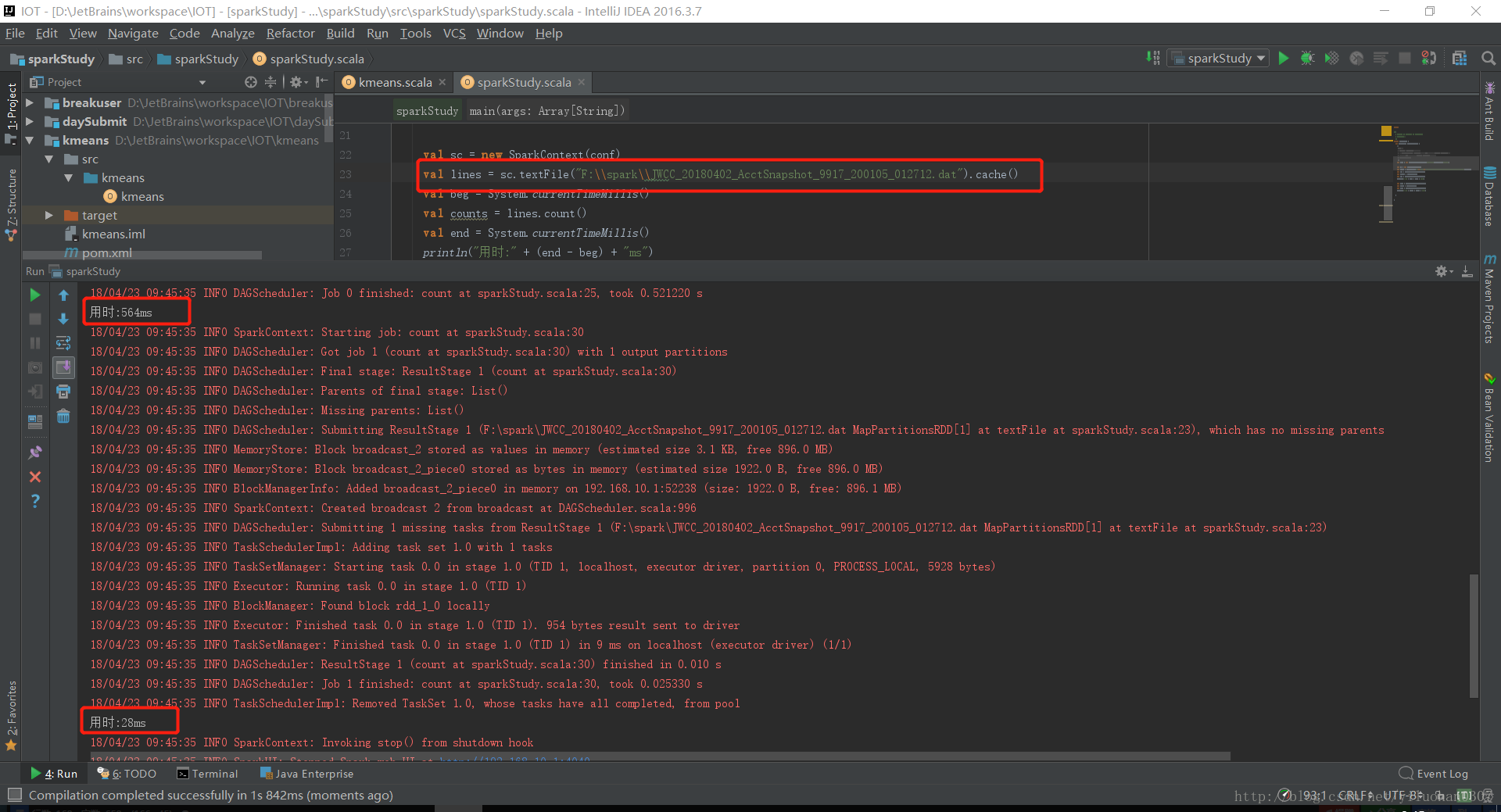
val lines = sc.textFile("F:\\spark\\JWCC_20180402_AcctSnapshot_9917_200105_012712.dat")
//val lines = sc.textFile("F:\\spark\\JWCC_20180402_AcctSnapshot_9917_200105_012712.dat").cache()
val beg = System.currentTimeMillis()
val counts = lines.count()
val end = System.currentTimeMillis()
println("用时:" + (end - beg) + "ms")
val begt = System.currentTimeMillis()
val count = lines.count()
val endt = System.currentTimeMillis()
println("用时:" + (endt - begt) + "ms")
}
}不是用cache()
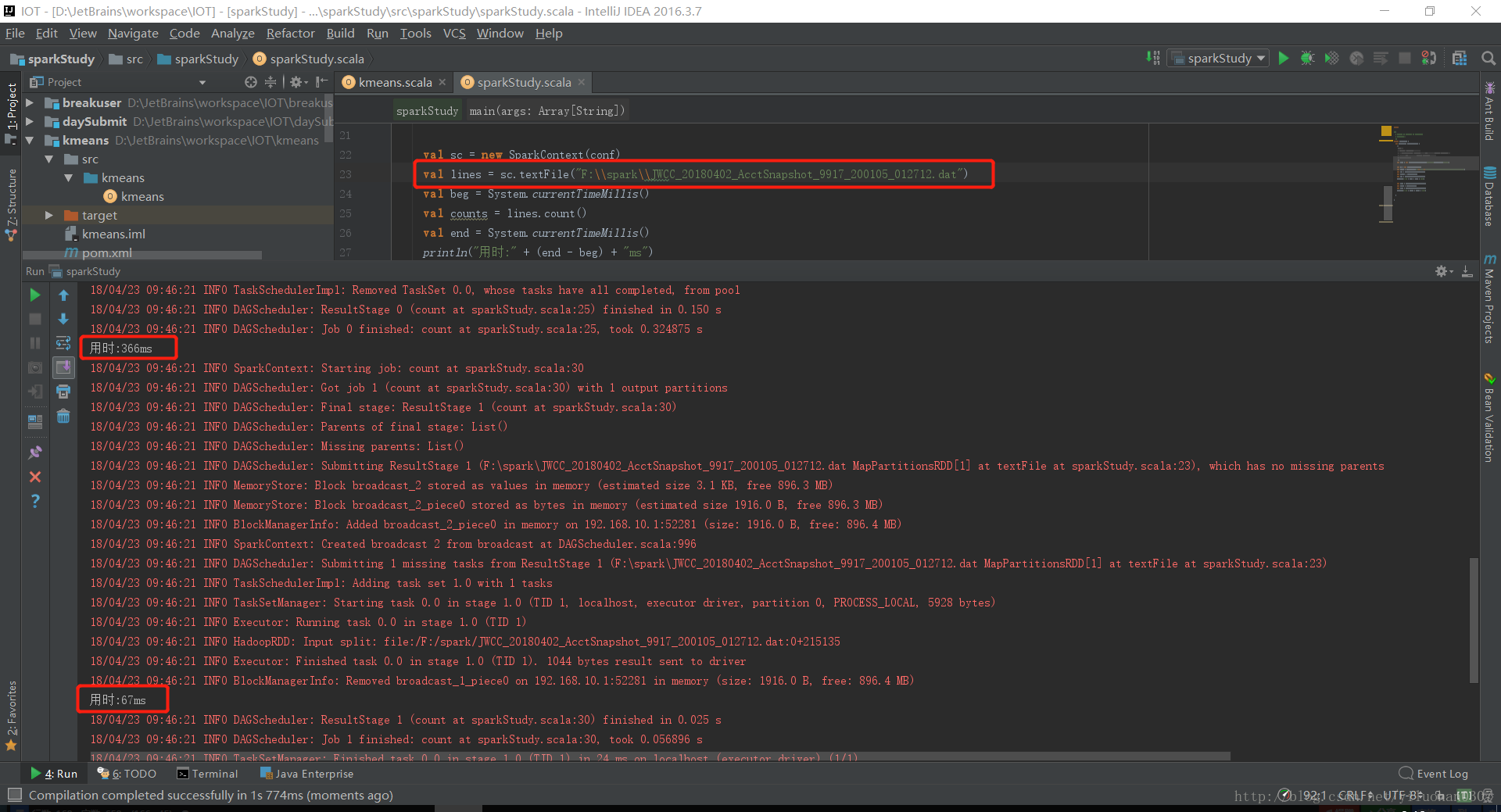
使用cache()