任务提交
一个线程启动一个任务
物理CPU包含多个逻辑CPU
local是本地的单机模式
集群模式就是下面的,
集群模式有三种:Standalone,Yarn,Mesos

yarn-client与yarn-cluster的区别就是driver所在地不一样。
本地模式启动参数

实例
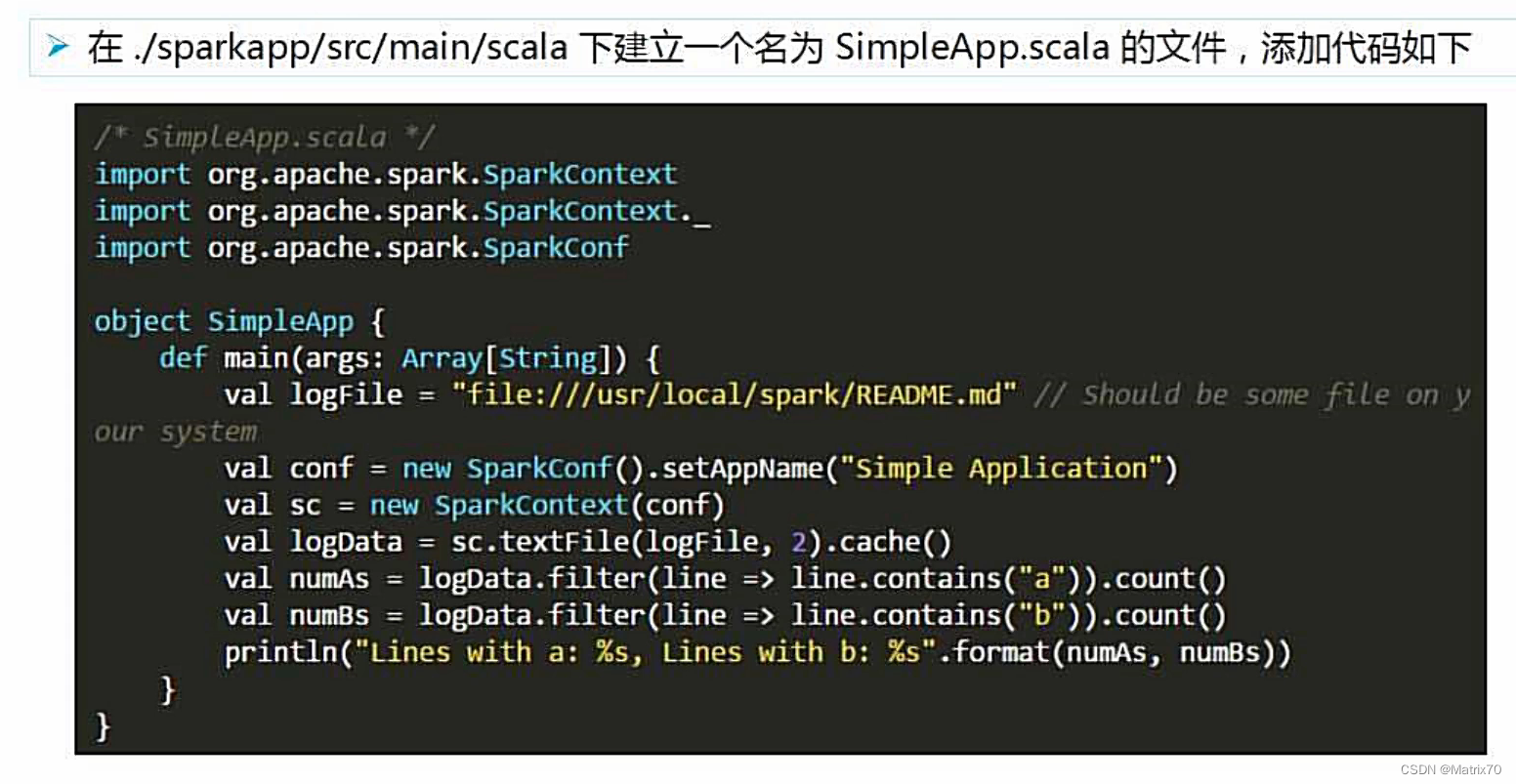
如上代码:
导包,单例对象,入口函数main,
需要我们人为创建一个SparkContext,作为链接集群的入口,new 一个SparkContext sc需要一个配置参数conf
注:我们在spark-shell中启动时,自动创建一个sc,我们可以直接拿来用
然后我们启动两个线程作为两个分片
随后过滤,我们的.filter后面跟的是一个lambda表达式,以line作为输入参数,=>右边执行的是把line中包含a的筛选出来,最后统计一下。
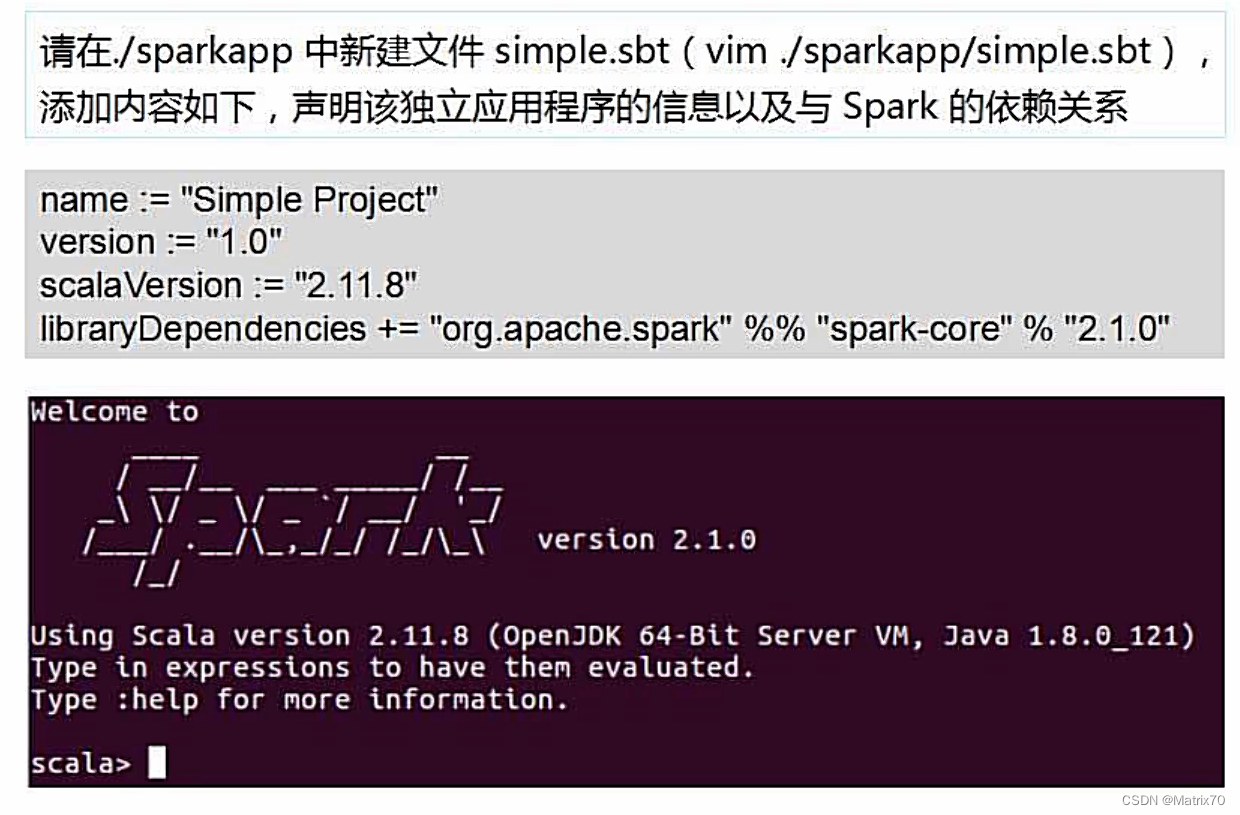
这里我们基本用的核心包spark-core.
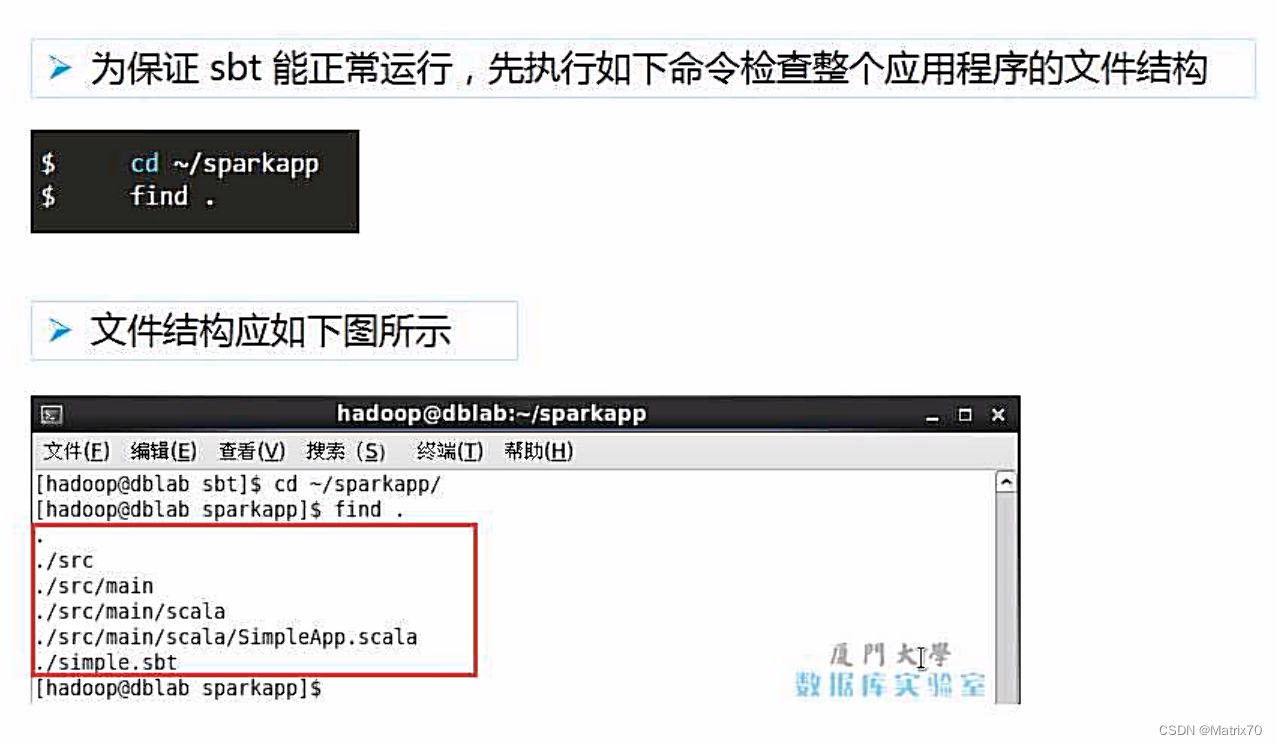 如果第一次使用sbt,那么会耗费很长时间,后面再使用时就会很快了。
如果第一次使用sbt,那么会耗费很长时间,后面再使用时就会很快了。

target目录是保存jar包的位置
spark-submit

object后面的就是主类
~表示用户主目录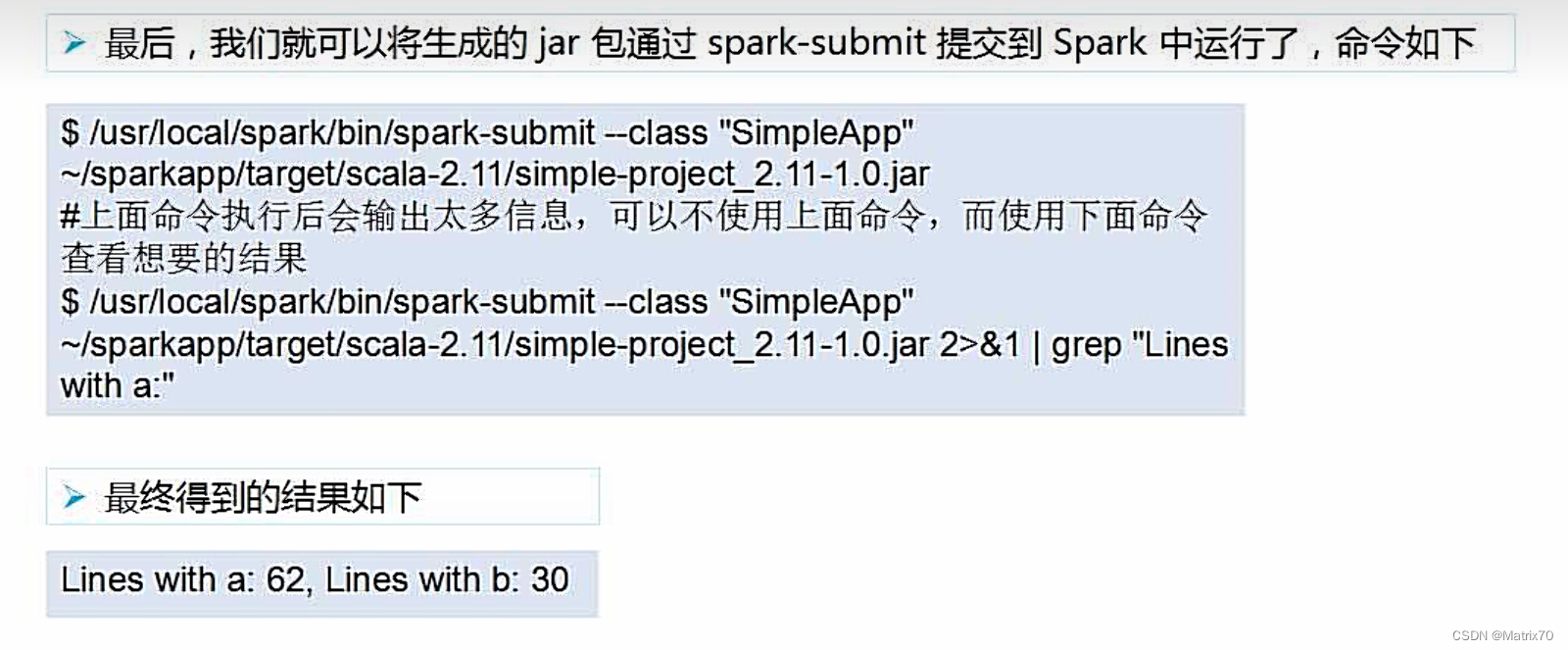
WordCount词频统计-在spark-shell中
读本地文件三个斜杆
对textFile-RDD的操作,把一行单词用空格区分,牌匾掉
再把单词映射为键值对,map中就是一堆键值对
.reduceByKey(),对有相同键进行求和汇总
例如hadoop,1 hadoop,2 =》 hadoop,3
在集群中,我们想在driver所在的节点把其他节点统计结果汇总,那就用.collect()

写一个单独的程序编译打包
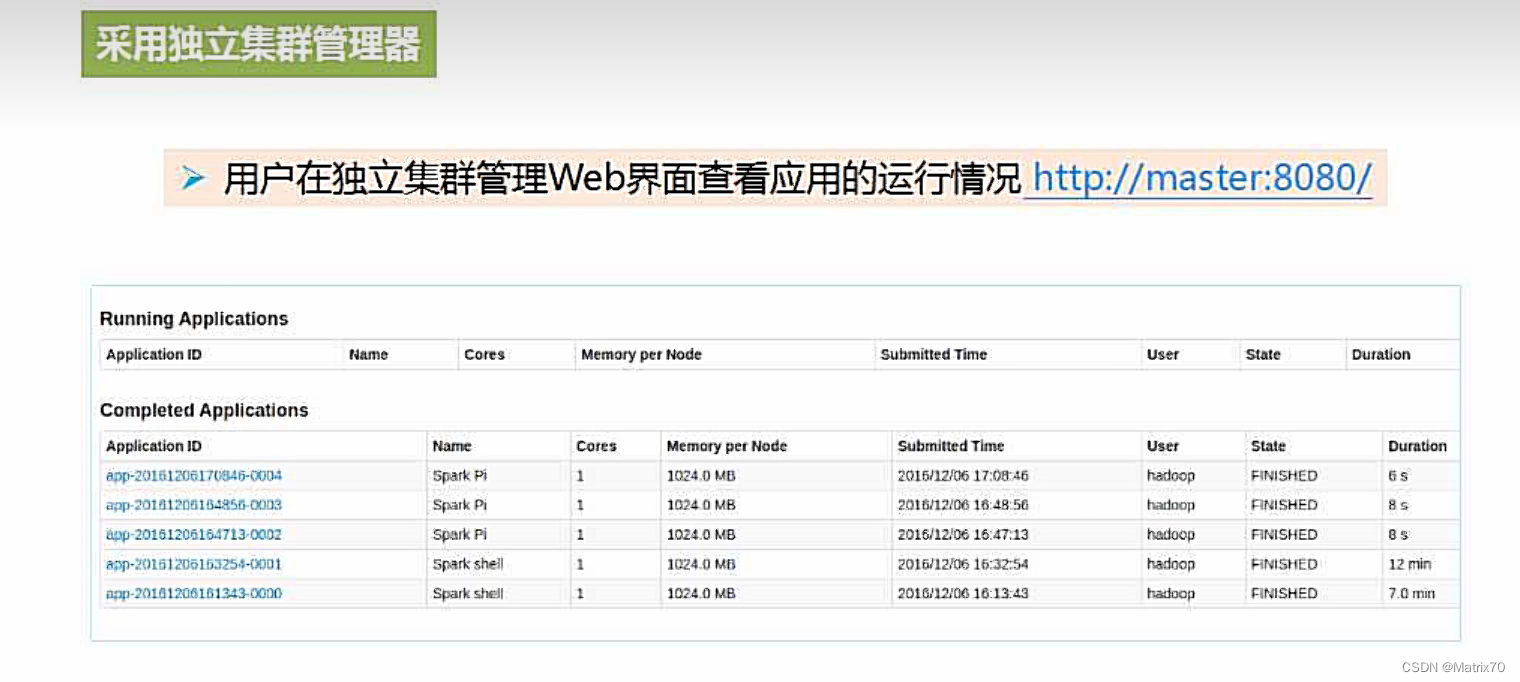
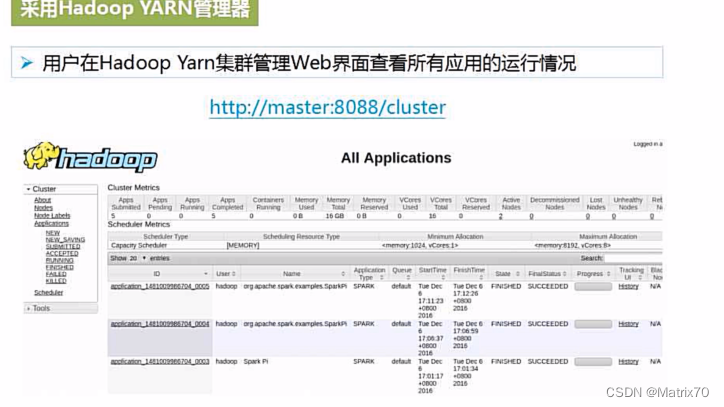
为什么setAppName呢,会在Spark-UI访问监控界面,有助于监测当前程序运行状态。
注意:下面代码的textFile与sc.textFile是两个不同,sc.textFile是一个方法,生成的textFile是一个RDD

在集群上运行Spark应用程序
在集群中运行应用程序JAR包

在集群中运行spark-shell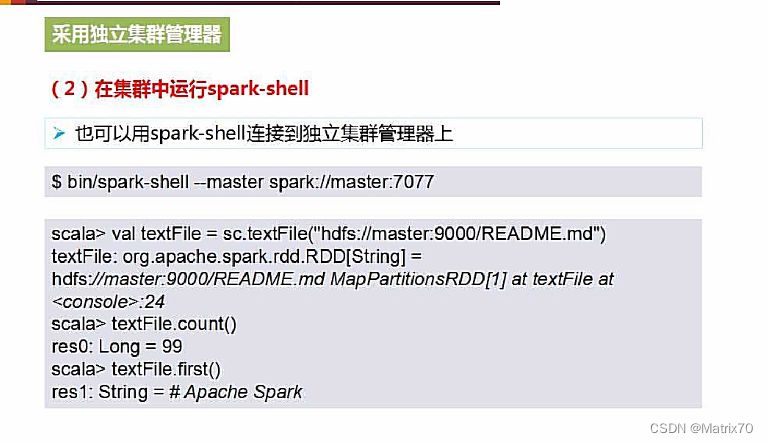
查看Spark-UI界面,查看8080端口