一、IDEA+Maven来构建我们的Spark Application
1、Maven依赖-Spark


2、Maven依赖-HDFS



注意:由于是CDH版本,IDEA默认是加载不到依赖包的。需要添加repositories

<repositories>
<repository>
<id>cloudera</id>
<name>cloudera</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
</repositories>
3、Hadoop入口类
fileSystem.java
4、Spark写一个WordCount
1)新建com.ruozedata.spark.core包,再新建object

package com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
object WordCountApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
//TODO...
val textFile = sc.textFile(args(0))
val wc = textFile.flatMap(line => line.split("\t")).map((_,1)).reduceByKey(_ + _)
wc.collect().foreach(println)
sc.stop()
}
}
2)打包

注意:Scala2.11.0之后,pom.xml以下语句要注释掉

成功。

3)上传到linux
rz -- target目录下
![]()
4)将待处理文件传到HDFS上

5)提交作业
官网:

Once a user application is bundled, it can be launched using the bin/spark-submit script. This script takes care of setting up the classpath with Spark and its dependencies, and can support different cluster managers and deploy modes that Spark supports:
./spark-submit --help

由官网得知提交作业需:

./spark-submit \
--class com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/opt/lib/spark-train-1.0.jar \
hdfs://hadoop002:9000/wc_input -----因为源代码中textFile(args(0))是指命令行编译运行Scala程序时,传入的第一个参数,所以这里要传文件路径为第一个参数,以便将待处理文件的路径传到spark程序里的textFile方法里。
结果:

5、结果打印输出换成保存文本到其他地方
wc.saveAsTextFile(args(1))
1)传路径
![]()
2)传路径以及压缩方式
![]()
./spark-submit \
--class com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/opt/lib/spark-train-1.0.jar \
hdfs://hadoop002:9000/wc_input hdfs://hadoop002:9000/wc_output
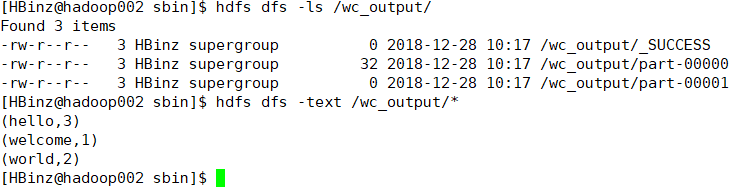
1)文件数(具体要根据文件大小来说,如果比block默认的大小要大,一个文件也会分成2个process):

6、处理多文件读取
1)HDFS上多存几个文件
hdfs dfs -put /opt/data/ruozeinput.txt /wc_input/1
hdfs dfs -put /opt/data/ruozeinput.txt /wc_input/2
hdfs dfs -put /opt/data/ruozeinput.txt /wc_input/3
hdfs dfs -put /opt/data/ruozeinput.txt /wc_input/4
2)改一下输出路径,这里跟HDFS一样,不能有相同的文件名
./spark-submit \
--class com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/opt/lib/spark-train-1.0.jar \
hdfs://hadoop002:9000/wc_input hdfs://hadoop002:9000/wc_output2

7、读取文件的时候,允许通配符过滤文件规则
./spark-submit \
--class com.ruozedata.spark.core.WordCountApp \
--master local[2] \
/opt/lib/spark-train-1.0.jar \
hdfs://hadoop002:9000/wc_input/*.txt hdfs://hadoop002:9000/wc_output3

8、结果降序排序
.sortByKey()
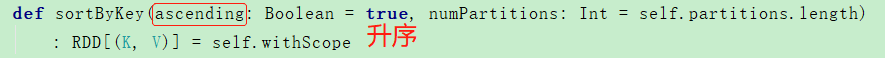
(3,hello)
(1,welcome)
(2,world)
======>sortByKey(false)
(1,welcome)
(2,world)
(3,hello)
======>map(x => (x_.1,x_.2)
代码如下:
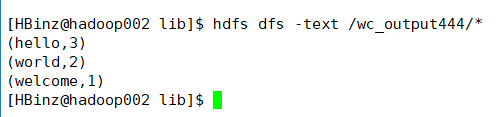
val sorted = wc.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1))
./spark-submit \
--class com.ruozedata.spark.core.SortWordCountApp \
--master local[2] \
/opt/lib/spark-train-1.0.jar \
hdfs://hadoop002:9000/wc_input/*.txt hdfs://hadoop002:9000/wc_output444
9、Spark-shell测试
源代码:
val textFile = sc.textFile("hdfs://hadoop002:9000/wc_input/*.txt")
val wc = textFile.flatMap(line => line.split("\t")).map((_,1)).reduceByKey(_ + _)
val sorted = wc.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1))
注意:如果是默认参数,方法的括号不能省略,如果没有参数,可以省略。
sorted.saveAsTextFile(args(1))

二、求用户访问量的TopN的Hive实现以及Spark Core实现过程分析
1、求用户访问量的TOP5
需求分析:
1)用户
使用tab分割 ==> split
拿到userid ==> splits(5)
(userid,1)
2)访问量
根据userid分组求总次数reduceByKey( _ + _ )
3)TOP5
按总次数排序,取前5条
反转
===>
sortByKey
===>
反转
take(5)
源代码:
//TODO...
val pageViews = sc.textFile(args(0))
//1 获取用户ID
val userid = pageViews.map(x => x.split("\t")(5))
//2 分组为每个用户ID赋值1
val useridCount = userid.map(x => (x,1))
//3 统计每组的总次数
val useridCounts = useridCount.reduceByKey(_ + _)
//3 排序
val sortuseridCounts = useridCounts.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)).take(5).foreach(println)
引申:
1、在工作中,很多场景的统计,你都可以看到wc的影子
拿到需求之后
1)分析
2)功能拆解:中文描述<====详细设计说明书
3)代码的开发:代码实现<====码农干的事情
2、求平均年龄(年龄的总和/个数)
数据格式:ID + “ ” + 年龄
实现思路
1)年龄
2)人数
3)年龄相加/人数
源代码:
//TODO...
val dataFile = sc.textFile(args(0))
//1 取出年龄
val age = dataFile.map(x => x.split(" ")(1))
//2 求人数
val count = dataFile.count()
//3 年龄相加
val totalage = age.map(age => age.toInt).reduce(_ + _)
//4 平均年龄
val avgAge = totalage/count
3、求男女人数
数据:ID + " " + 性别 + " " + "身高"
需求:
1)统计男女人数
2)男性中最高和最低身高
3)女性中最高和最低身高
分析:
1)RDD ==> MRDD + FRDD
lines.filter(line=>line.contains("F")2)MRDD sort 或者 max min
3)FRDD sort 或者 max min
二、Spark调优
1、内存调优
1)改变数据结构
2)存储数据以序列化的方式
后台查storage
或者用sizeEstimator的estimate方法也可以获取消耗的内存值