一、在spark-shell中运行代码
1、Spark Shell 提供了简单的方式来学习Spark API Spark Shell可以以实时、交互的方式来分析数据 Spark Shell支持Scala和Python
2、Spark shell命令
使用Spark单机模式,只需要进入Spark安装目录执行:./bin/spark-shell --master <master-url>
<master-url>是可以替换的参数
./bin/spark-shell --master <master-url>这样就表示只用了一个Worker去运行Spark,那么显然就没有并行化
./bin/spark-shell --master local因为我们的电脑一般是多核CPU那么我想使用多线程的话,就可以用[*]使用 逻辑CPU的多个线程来运行Spark,那么这个*也能被具体数字代替
./bin/spark-shell --master local[*]
Standalone模式(独立集群模式)
./bin/spark-shell -- master spark://127.0.0.1:7077
--jars: 这个参数用于把相关的JAR包添加到CLASSPATH中;如果有多个jar包,可以使用逗号分隔符连接它们
./bin/spark-shell --mster local[*] --jars wordcount.jar

可以执行“spark-shell --help”命令,获取完整的选项列表
spark-shell --help
二、编写Spark独立应用程序
使用 Scala 编写的程序需要使用 sbt或Maven 进行编译打包
安装编译打包工具
生产环境中我们常用的是sbt和Maven两种软件对代码进行打包编译。然后使用spark-submit命令提交jar包到集群或者单机环境中运行。
1.安装sbt
sbt是一款Spark用来对scala编写程序进行打包的工具,Spark 中没有自带 sbt,需要下载安装
解压sbt: tar -zxf sbt-0.13.18.tgz
tar -zxf sbt-0.13.18.tgz
将sbt移动到/usr/local/目录,,并进入目录 sudo mv sbt /usr/local/ cd /usr/local/sbt
sudo mv sbt /usr/local/
cd /usr/local/sbt创建sbt脚本
vim sbt
#添加一下代码
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar /usr/local/sbt/bin/sbt-launch.jar "$@" #红字绝对路径是sbt安装目录

将脚本设置为可执行 chmod u+x sbt
chmod u+x sbt

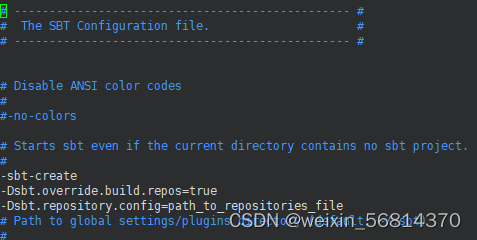
设置sbt更新国内镜像
vim conf/sbtopts
#添加以下代码
-Dsbt.override.build.repos=true
-Dsbt.repository.config=path_to_repositories_file
创建sbt国内镜像文件
cd /usr/local/sbt
vim repositories
#添加以下代码
[repositories]
local
huaweicloud-maven: https://repo.huaweicloud.com/repository/maven/
maven-central: https://repo1.maven.org/maven2/
sbt-plugin-repo: https://repo.scala-sbt.org/scalasbt/sbt-plugin-releases, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]

首次运行sbt脚本,更新sbt
./sbt sbt-version
编写Spark应用程序代码
1、创建应用程序目录
cd ~
mkdir ./sparkapp
mkdir -p ./sparkapp/src/main/scala

2、创建scala代码文件SimpleApp.scala
vim ./sparkapp/src/main/scala/SimpleApp.scala
#完整代码
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark-2.1.0/README.md"
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
编译打包
使用sbt打包
sbt打包必须满足的条件:
1. 在我们的应用程序文件夹根目录下
2. 打包文件必须以.sbt结尾
3. 所以我们使用 vim ./sparkapp/simple.sbt 构建打包文件
vim ./sparkapp/simple.sbtname:="XXX" #应用程序的名称是什么
version:="1.0" #应用程序当前版本号
scalaVersion:="2.11.8" #当前scala的版本
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
#依赖于GroupID为"org.apache.spark",artifact号是是2.1.0,这样就会自动去网上把相关的jar包下载下来使用#关于%: 在今后的书写过程中,要注意%的使用 1. %%代表不固定版本 2. %代表指定版本
检查目录结构:
cd ~/sparkapp/
find .

打包 cd ~/sparkapp /usr/local/sbt/sbt package
cd ~/sparkapp
/usr/local/sbt/sbt package

生成的Jar包位置 在当前的应用程序目录下有一个 /target/scala-2.11 子目录 这个目录下有一个子目录,里面的simple-project开头的文件就是打包好的jar包

通过spark-submit运行程序
进入spark安装目录使用 ./bin/spark-submit 命令上传jar包到Spark运行,注意这里的jar包可以放在任意一种spark运行模式运行 除基本命令以外,spark-submit命令还有许多可以添加参数

使用以下命令提交jar包作业
/usr/local/spark-2.1.0/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"
注意结尾 2>&1 | grep "Lines with a:"是Linux管道命令,可以过滤一些不必要的信息三、在集群上运行Spark应用程序
1. 打开集群
打开hadoop 然后再打开spark
2. 提交作业
cd /usr/local/spark-2.1.0 bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://192.168.131:7077 \
examples/jars/spark-examples_2.11-2.1.0.jar 100 2>&1 | grep "Pi is roughly"
cd /usr/local/spark-2.1.0 bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.131:7077 examples/jars/spark-examples_2.11-2.1.0.jar 100 2>&1 | grep "Pi is roughly"
提交作业(YARN模式)

集群中运行Spark-shell
