免费体验:一键完成商超商品识别模型部署
一、工作准备
1.1 注册账号、实名认证
已注册华为帐号并开通华为云,进行了实名认证,且在使用ModelArts前检查帐号状态,帐号不能处于欠费或冻结状态。
1.2 配置委托访问授权
ModelArts使用过程中涉及到OBS、SWR、IEF等服务交互,首次使用ModelArts需要用户配置委托授权,允许访问这些依赖服务
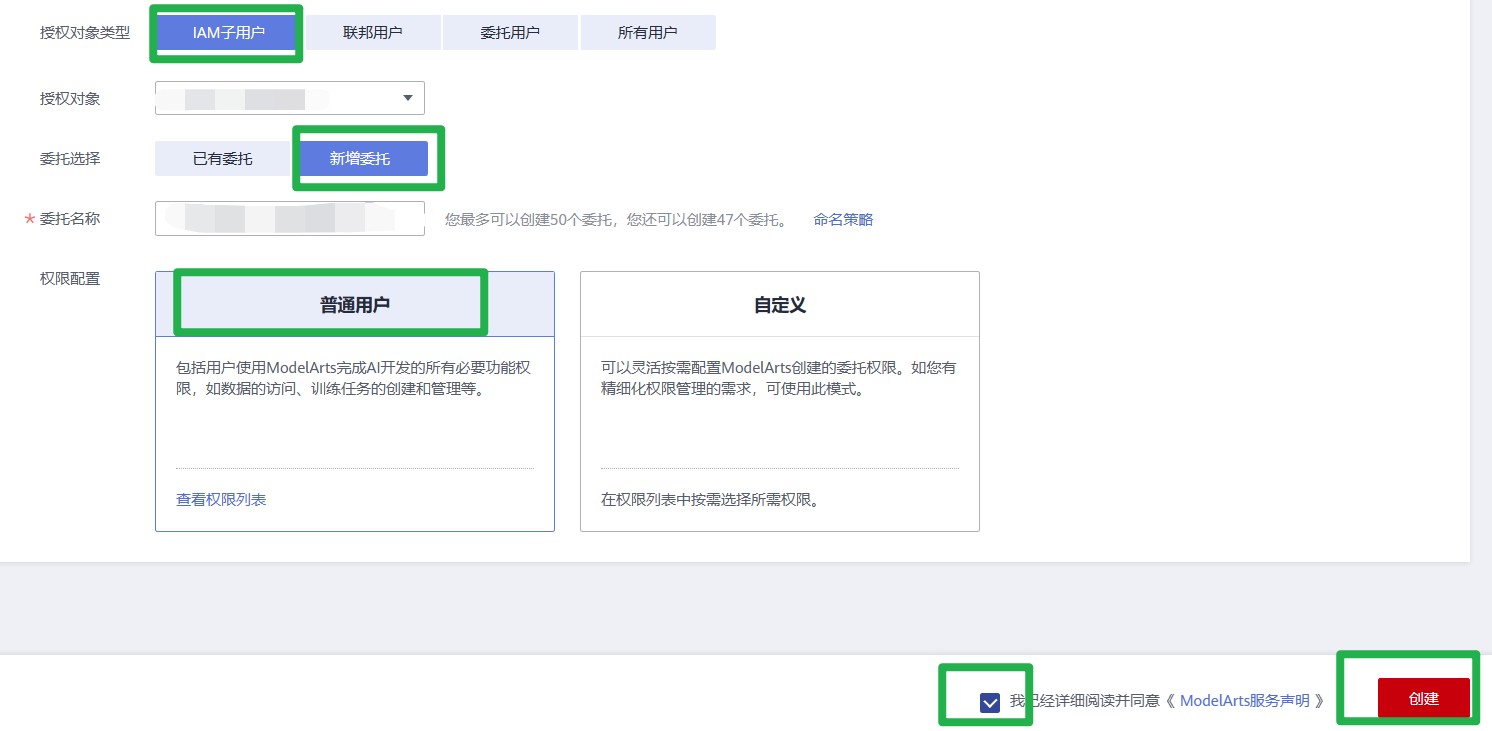
1.使用华为云帐号登录ModelArts管理控制台,在左侧导航栏单击“全局配置”,进入“全局配置”页面,单击“添加授权”。

2.在“访问授权”页面,选择需要授权的“用户名”,选择新增委托及其对应的权限“普通用户”,并勾选“我已经详细阅读并同意《ModelArts服务声明》”,然后单击“创建”。
二、订阅模型
商超商品识别的模型共享在AI Gallery中。您可以前往AI Gallery,免费订阅此模型。
2.1在AI Gallery搜索模型。
方式一:单击商超商品识别模型链接,进入模型详情页。
方式二:在ModelArts管理控制台的左侧菜单栏,单击**“AI Gallery”**进入AI Gallery。选择“资产集市 > 模型”,搜索“商超商品识别”,单击名称进入模型详情页。
2.2完成模型订阅。
在模型详情页,单击“订阅”,阅读并勾选同意《数据安全与隐私风险承担条款》 和 《华为云AI Gallery服务协议》,单击“继续订阅”。
订阅模型完成后,页面的“订阅”按钮显示为“已订阅”。

3.3进入ModelArts控制台的订阅列表。
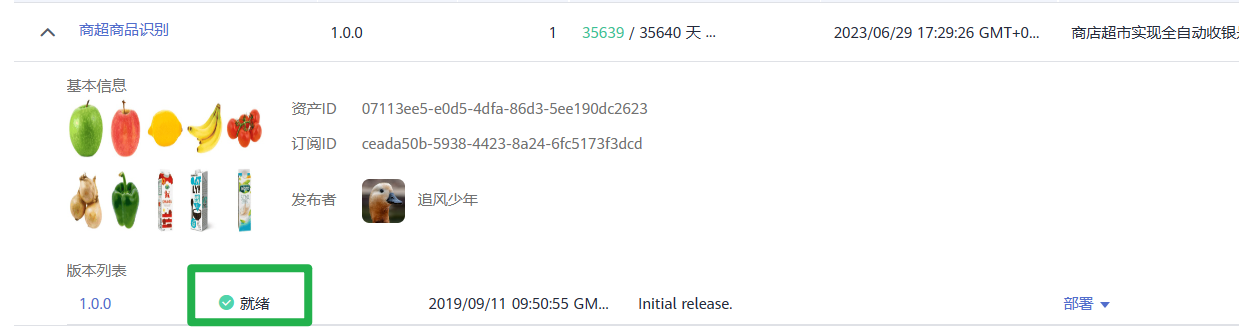
在模型详情页,单击“前往控制台”。在弹出的“选择云服务区域”页面选择ModelArts所在的云服务区域,单击“确定”跳转至ModelArts控制台的“AI应用管理 > AI应用 > 我的订阅”页面。

在“我的订阅”列表,单击模型名称前面的 ,当订阅模型的版本列表的状态显示为“就绪”时表示模型可以使用。
,当订阅模型的版本列表的状态显示为“就绪”时表示模型可以使用。
三、使用订阅模型部署在线服务
模型订阅成功后,可将此模型部署为在线服务。
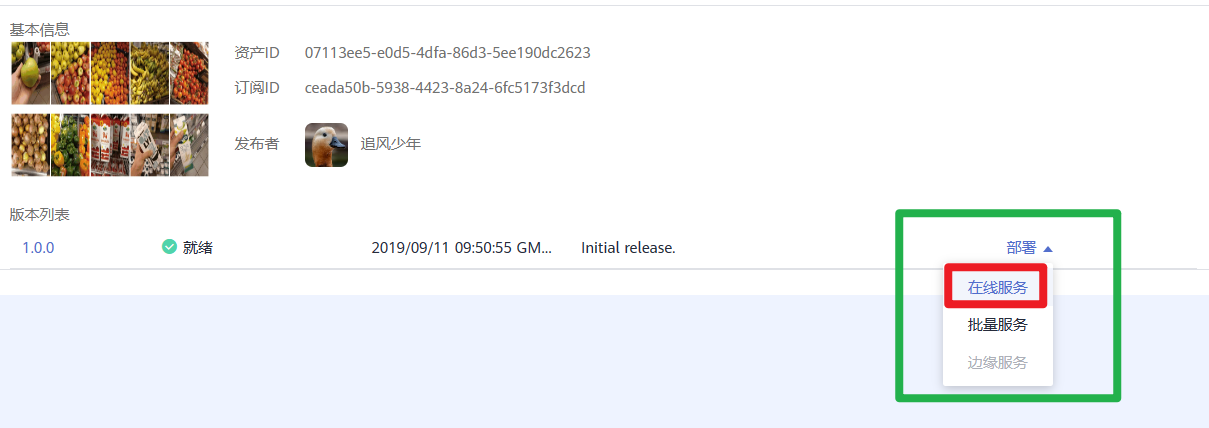
1.在“AI应用管理 > AI应用 > 我的订阅”页面,单击模型名称前面的 ,在展开的版本列表中单击“部署 > 在线服务”跳转至部署页面。
,在展开的版本列表中单击“部署 > 在线服务”跳转至部署页面。
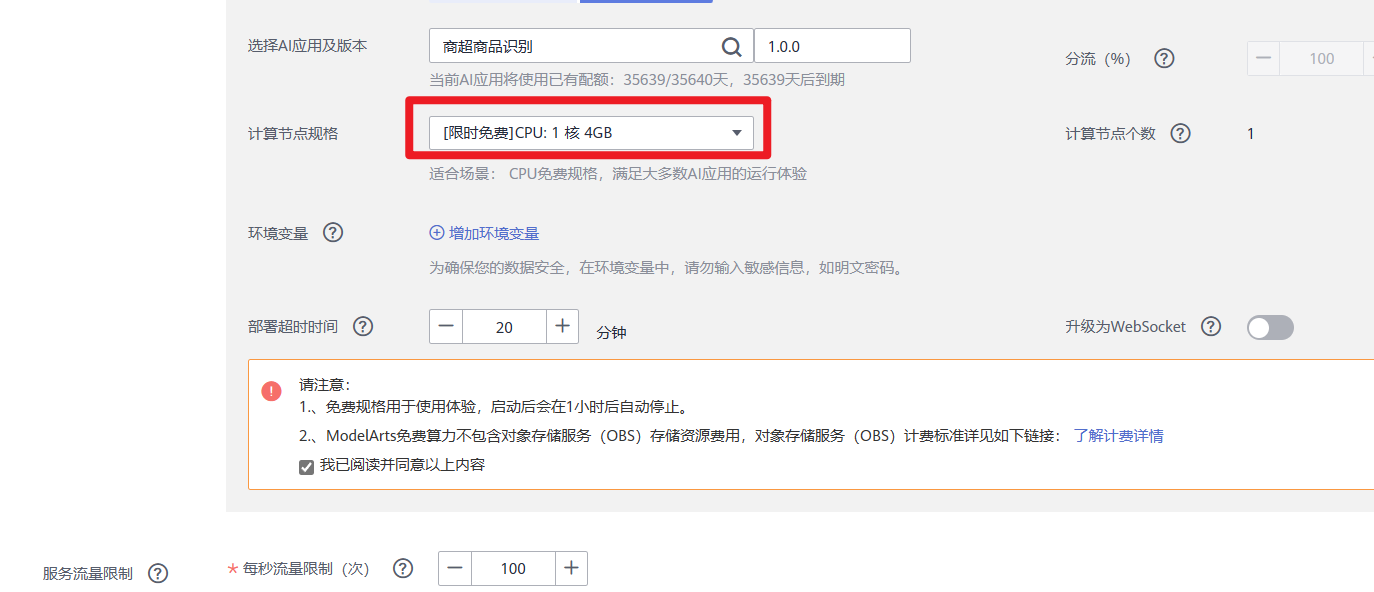
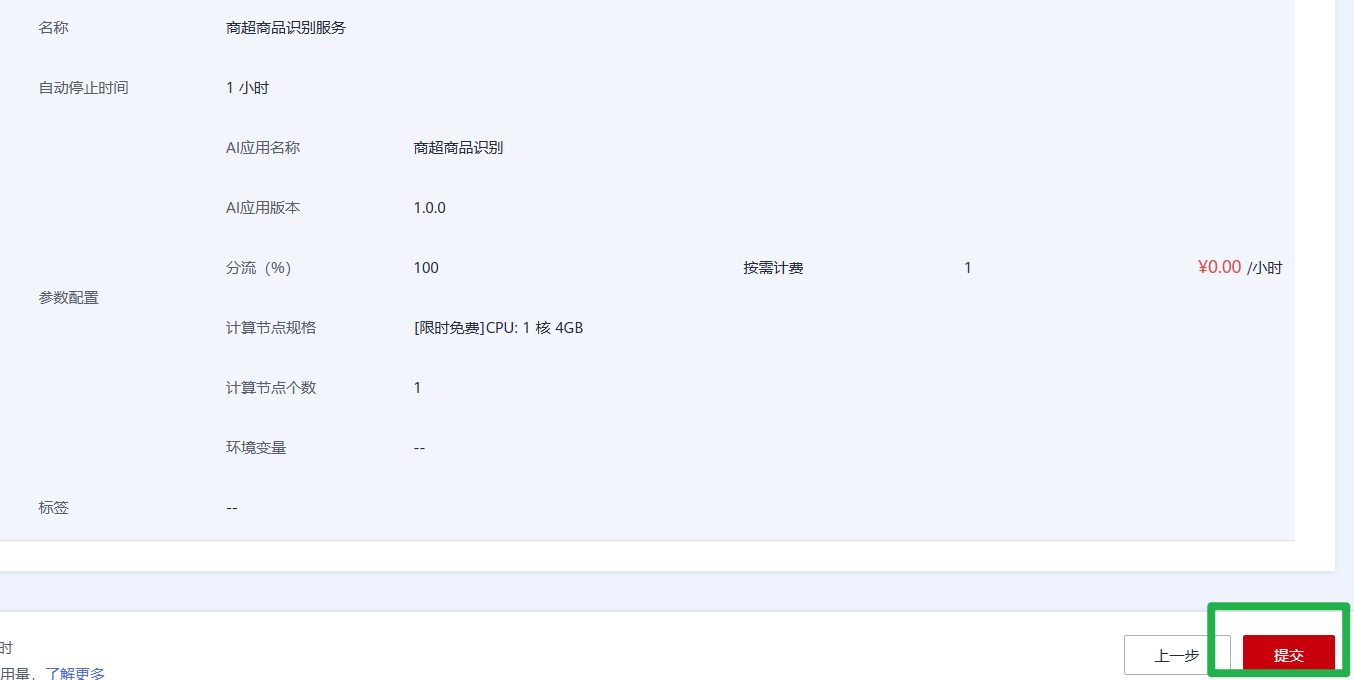
2.在部署页面,参考如下说明填写关键参数。
- “名称”:自定义一个在线服务的名称,也可以使用默认值,此处以“商超商品识别服务”为例。
- “资源池”:选择“公共资源池”。
- “AI应用来源”和“选择AI应用及版本”:会自动选择订阅模型。
- “计算节点规格”:在下拉框中选择“限时免费”资源,勾选并阅读免费规格说明。
- 其他参数可使用默认值。

3.参数配置完成后,单击“下一步”,确认规格参数后,单击“提交”启动在线服务的部署。
4.进入“部署上线 > 在线服务”页面,等待服务服务状态变为“运行中”时,表示服务部署成功。预计时长4分钟左右

四、预测结果
1.在线服务部署完成后,单击服务名称进入服务详情。
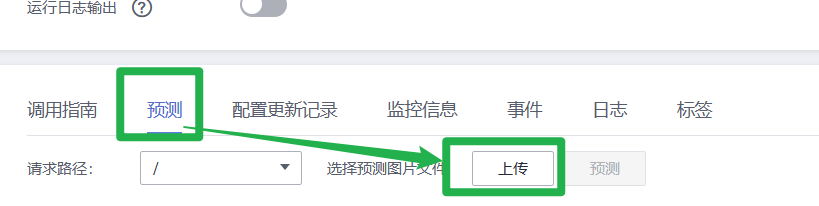
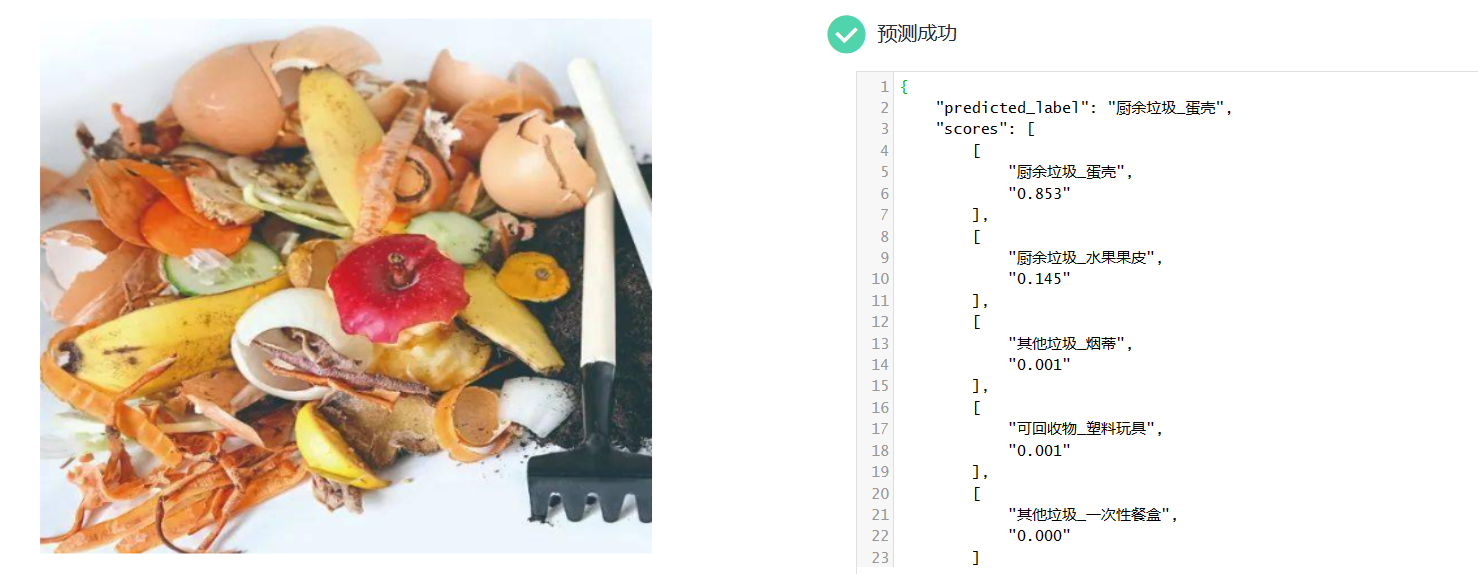
2.在“预测”页签,单击“上传”,上传一个测试图片,单击“预测”查看预测结果。此处提供一个样例图片供预测使用。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wwziUuh1-1688053129069)(…/zh-cn_image_0000001449294477.jpg)]
3.预测结果

五、清理资源
体验结束后,建议暂停或删除服务,避免占用资源,造成资源浪费。
- 停止在线服务:在在线服务列表,单击对应服务操作列的“更多 > 停止”。
- 删除在线服务:在在线服务列表,单击对应服务操作列的“更多 > 删除”。
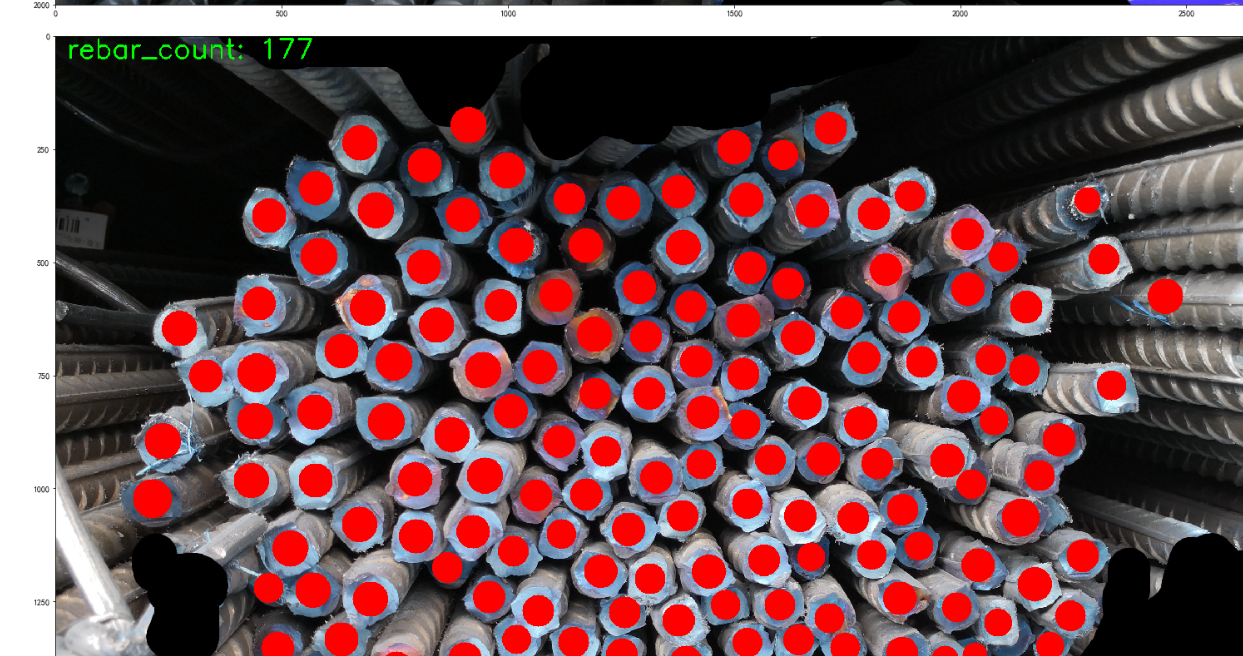
一键运行Notebook实现工地钢筋盘点
一、工作准备
同上,略
二、一键运行Notebook
1.单击案例链接基于计算机视觉的钢筋条数检测,进入案例详情页。
2.单击详情页右侧的“Run in ModelArts”。
3.系统自动进入ModelArts的JupyterLab页面,如果未登录华为云,根据提示登录。
4.登录后在页面右上角会提示正在与ModelArts连接中,请等待连接完成。
5.在右侧的资源管理窗口,推荐切换为限时免费的GPU规格进行训练,可以提升训练效率。

6.资源切换完成后,即可以了解该案例的内容步骤并运行。
7.单击ipynb文件右侧的“No Kernel”,在弹出的“Select Kernel”页面选择AI框架。
8.反复单击导航栏的 ,逐步运行每个步骤;也可以一键运行该案例的所有步骤
,逐步运行每个步骤;也可以一键运行该案例的所有步骤
单步运行按钮

一键运行所有步骤
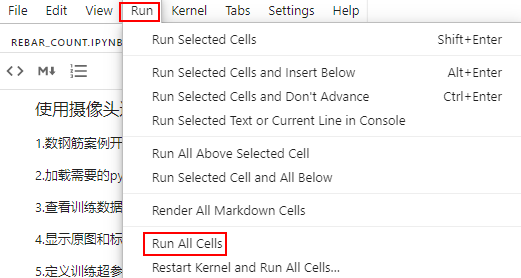
运行时,右上角圆圈的空心圆表示未开始或者运行完成,实心圆 表示代码正在运行。
表示代码正在运行。
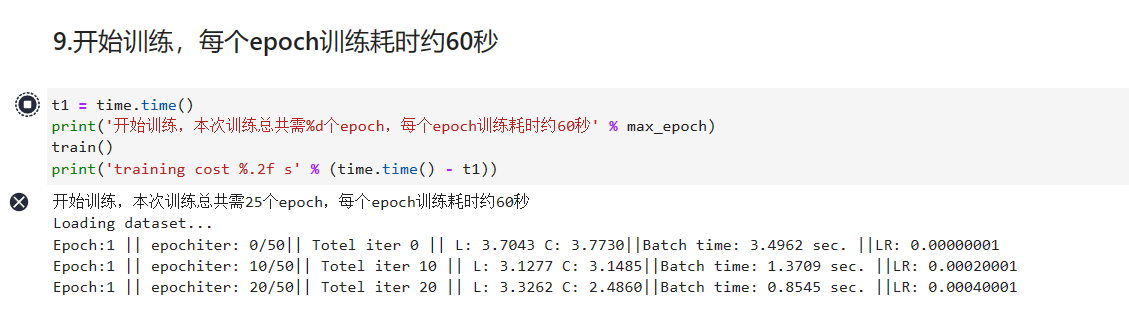
9.在第9步的训练环节,共迭代训练25次,每次耗时60秒,共25分钟,请耐心等待。
垃圾分类(使用新版自动学习实现图像分类)
一、准备工作
1.注册华为帐号并开通华为云、实名认证
2.创建OBS桶
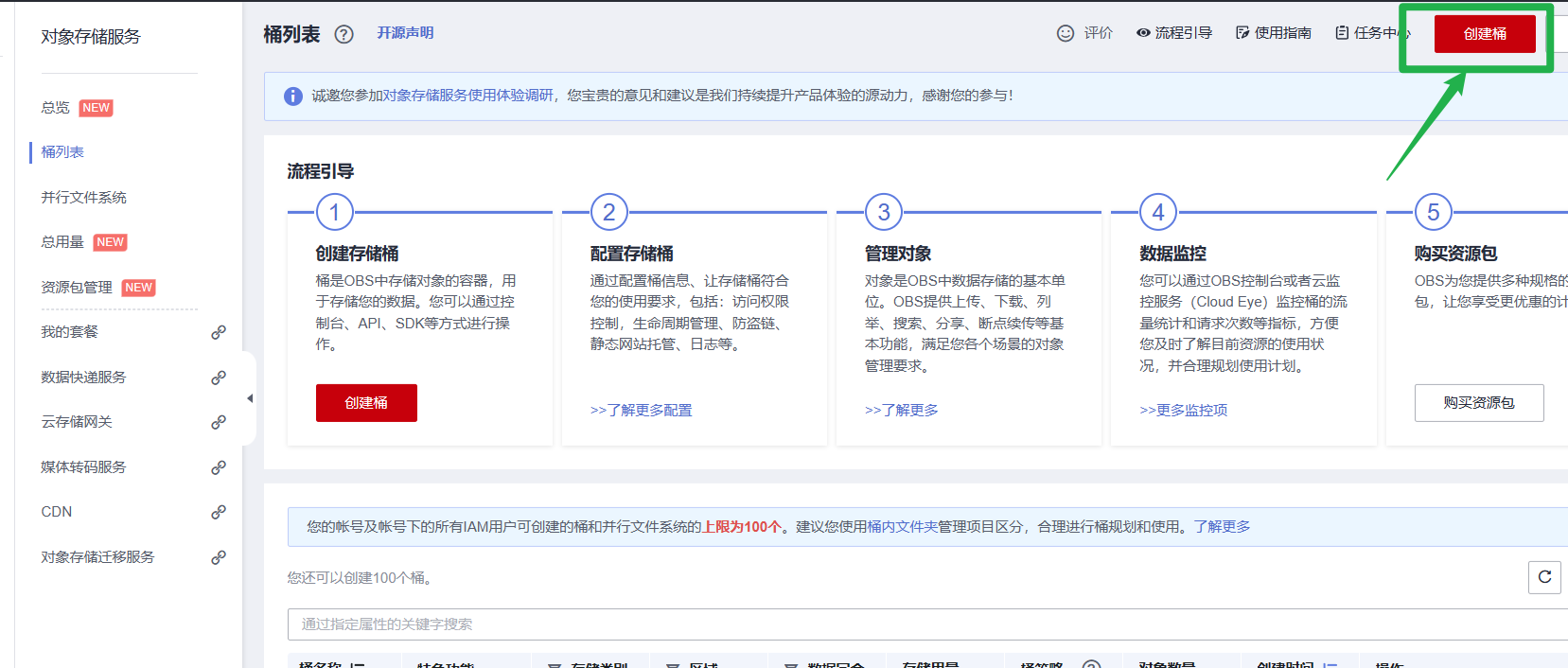
登录OBS管理控制台,在桶列表页面右上角单击“创建桶”,创建OBS桶。例如,创建名称为“c-flowers”的OBS桶。
在ModelArts中选择OBS路径时,找不到已创建的OBS桶?
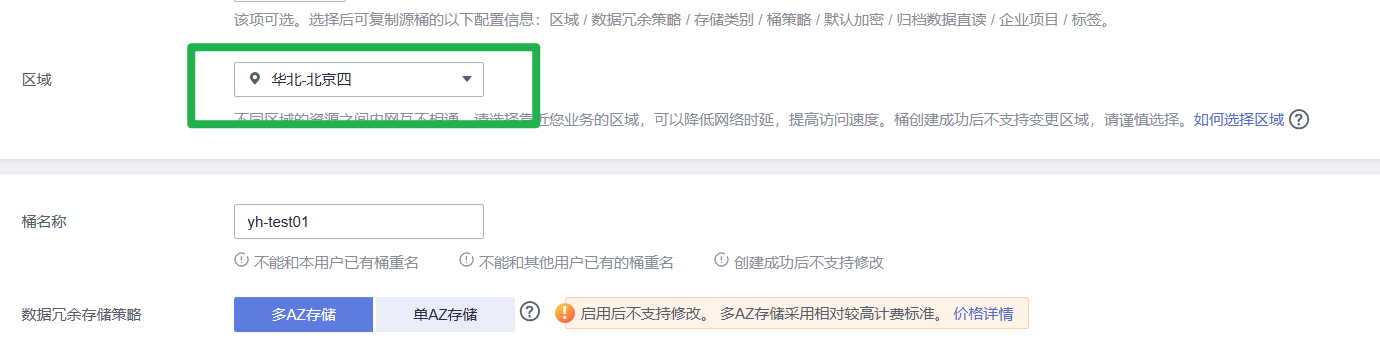
原因是已创建的OBS桶和使用的ModelArts服务不在同一个区域。
注意下图中的区域要和ModelArts一致
二、准备训练数据集
1.进入AI Gallery,在“资产集市”>“数据”中的“数据集”页面找到8类常见生活垃圾图片数据集,单击右侧“下载”。
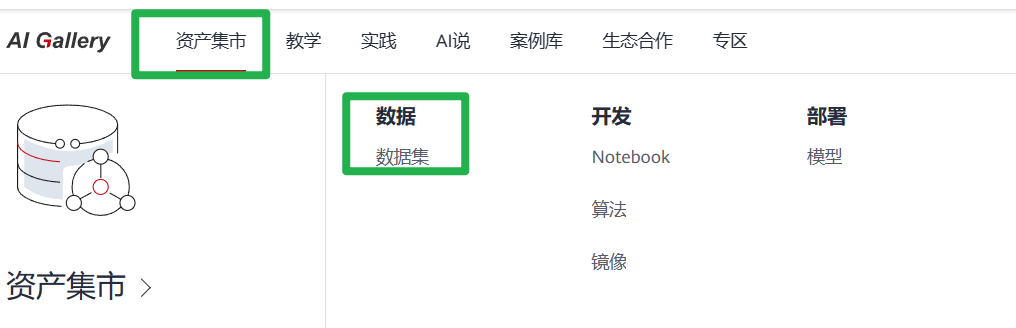

2.选择对应的云服务区域例如:华北-北京四,需要确保您选择的区域与您的管理控制台所在的区域一致。
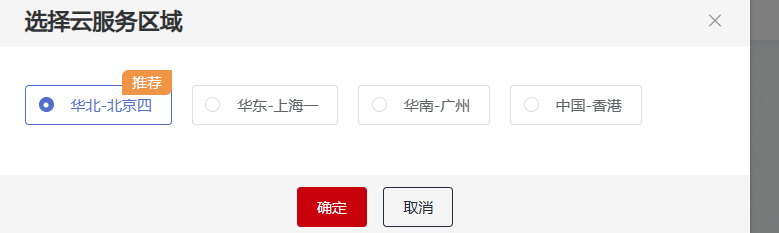
3.进入“下载详情”页面,填写下述参数。
- 下载方式:ModelArts数据集。
- 目标区域:华北-北京四。
- 数据类型:图片。
- 数据集输出位置:选择您的OBS路径的空目录
- 数据集输入位置:选择您的OBS路径
- 名称:自定义
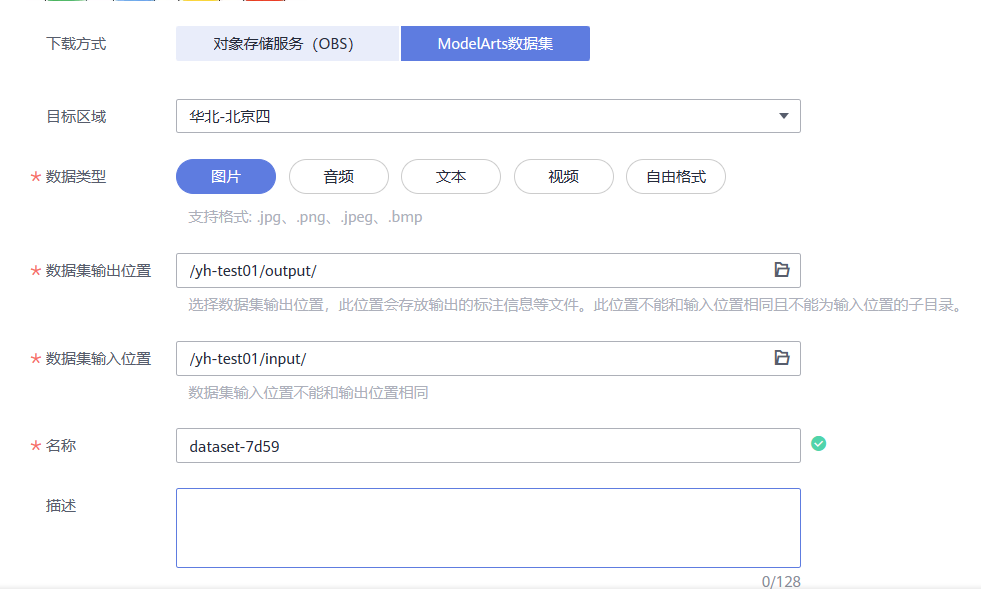
4.完成参数填写,单击“确定”,自动跳转至AI Gallery个人中心“我的下载”页签,等待5分钟左右下载完成,进入“目标位置”可以在对象存储服务(OBS)中查看数据集储存位置。

三、配置委托访问授权
ModelArts使用过程中涉及到OBS、SWR、IEF等服务交互,首次使用ModelArts需要用户配置委托授权,允许访问这些依赖服务。
这个之前已经配置过了,所以只需要将已有委托加入即可
四、创建新版自动学习图像分类项目
1.进入ModelArts管理控制台,在左侧导航栏选择“自动学习”
2.进入新版自动学习页面后,单击选择“图像分类”创建项目。完成参数填写:
- 计费模式:按需计费。
- 名称:自定义您的项目名称。
- 描述:自定义描述您的项目详情。
- 数据集:单击下拉框选择从AI Gallery下载好的数据集(下拉框展示的数据集为您名下按照时间顺序创建的的所有数据集,此处选择您最近创建的数据集即为从AI Gallery下载好的数据集)。
- 输出路径:选择您的OBS文件夹下的路径。
- 训练规格:单击下拉框选择训练规格。
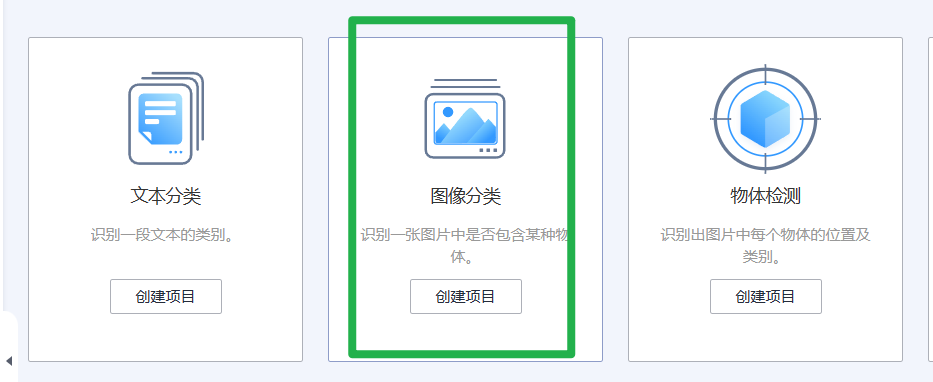
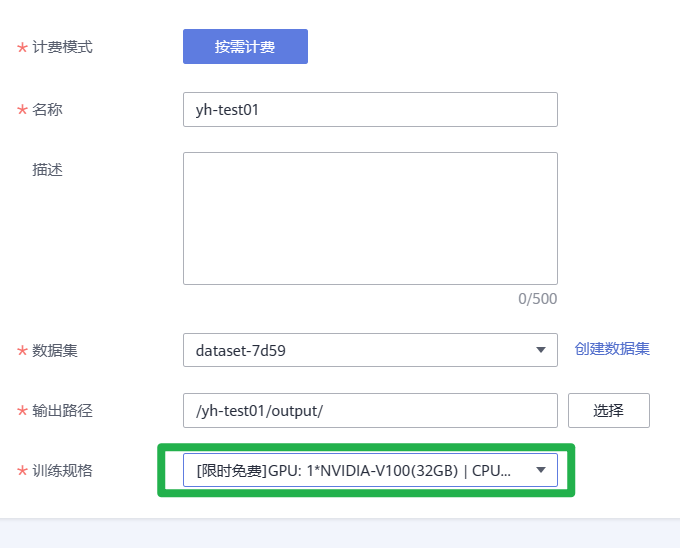
3.参数填写完成,单击“创建项目”,即可跳转到新版自动学习的运行总览页面。
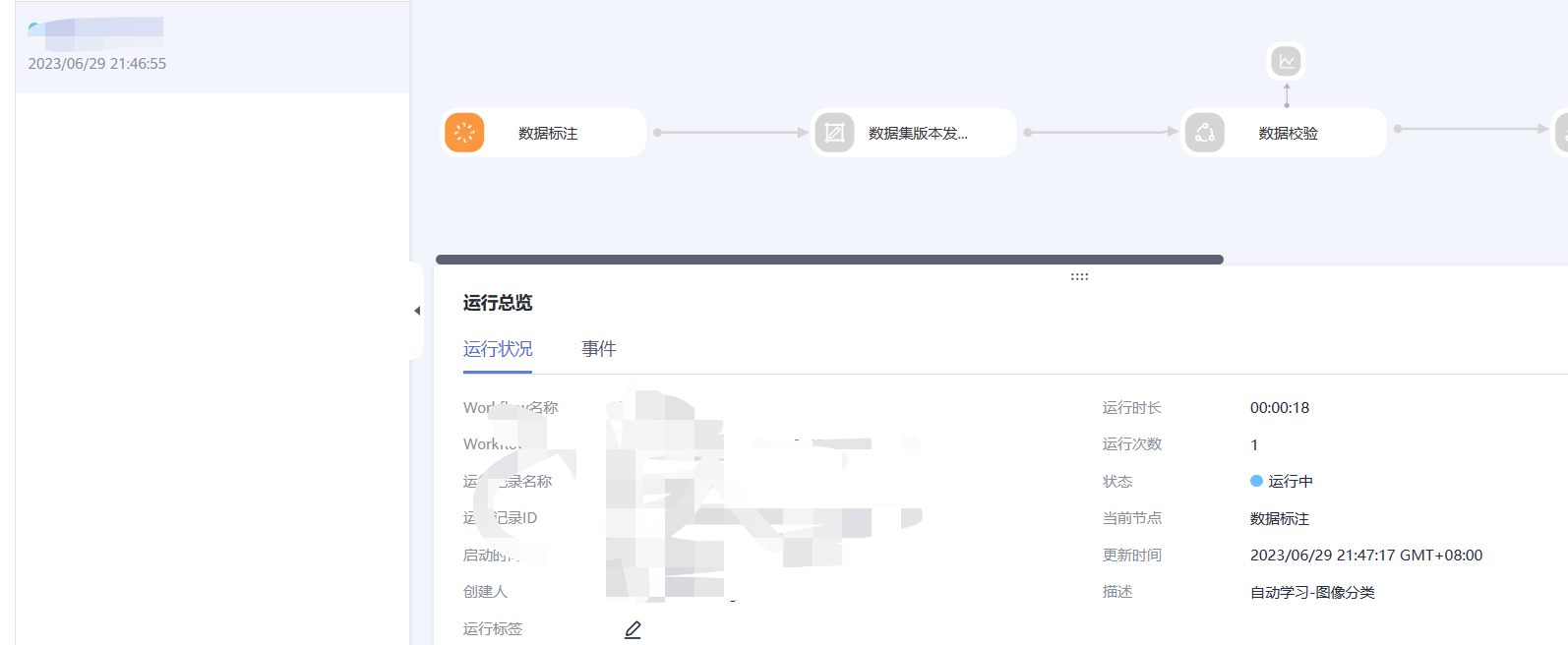
五、运行工作流
项目完成创建之后,会自动跳转到新版自动学习的运行总览页面。同时您的工作流会自动从数据标注节点开始运行。
1.在数据标注节点,待数据标注节点变为橘色即为“等待操作”状态。
2.单击“继续运行”工作流会自动从数据标注节点依次运行到服务部署节点。该段时间不需要用户做任何操作。
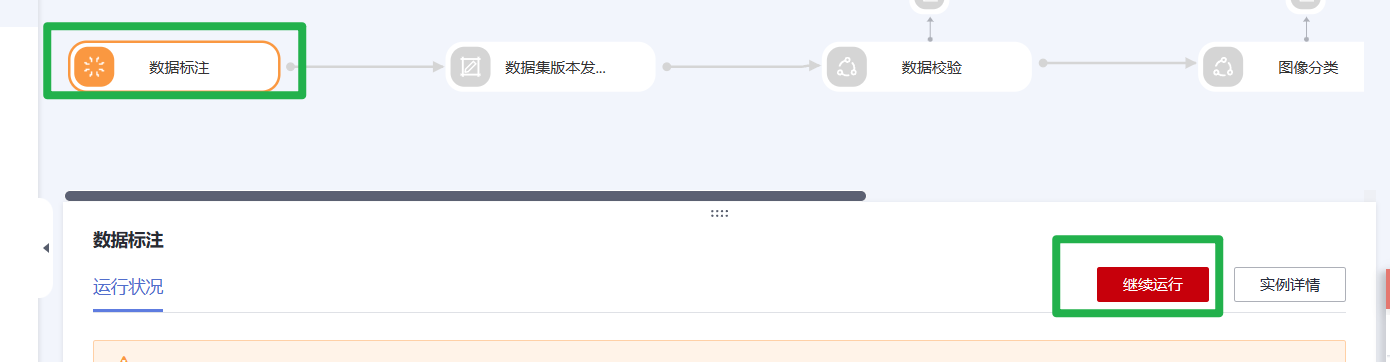
3.当工作流运行到“服务部署”节点,状态会变为“等待输入”,您需要填写您的输入参数:
- AI应用:默认为您的自动学习项目名称。
- 选择AI应用版本:系统默认,无需再选择。
- 资源池:默认选择“公共资源池”,您也可以根据您的需求选择相应的专属资源池。
- 计算节点规格:根据您的实际需求选择相应的规格,不同规格的配置费用不同,本案例使用的规格为[限时免费]CPU:1核4GB。
- 分流(100%):默认为100。
- 节点个数:默认为1。
- 是否自动停止:为了避免资源浪费,建议您打开该开关,根据您的需求,选择自动停止时间。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f2q27d3q-1688053129075)(https://s2.loli.net/2023/06/29/D62UOMWctQoLymK.png)]
4.参数填写完毕之后,单击运行状况右边的“继续运行”,单击确认弹窗中的“确定”即可继续完成工作流的运行。
六、预测分析
运行完成的工作流会自动部署相应的在线服务,您只需要在相应的服务详情页面进行预测即可。
1.在服务部署节点单击“实例详情”或者在管理控制台,选择“部署上线>在线服务”即可进入在线服务详情页。
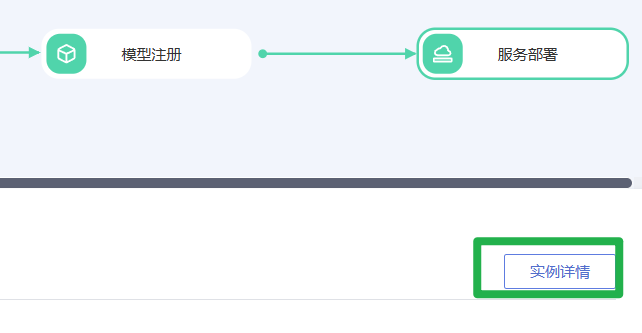
2.在服务详情页,单击选择“预测”页签。

3.上传一张需要预测的图片,单击预测,即可在右边的预测结果显示区查看您的预测结果。
七、清除相应资源
在完成预测之后,建议关闭服务,以免产生不必要的计费。
1.停止运行服务
返回在线服务,在对应的服务名称,单击选择操作列的“更多>停止”,停止该服务
2.清除OBS中的数据
- 在控制台左侧导航栏的服务列表
 ,选择“对象存储服务OBS”,进入OBS服务详情页面。
,选择“对象存储服务OBS”,进入OBS服务详情页面。 - 在左侧导航栏选择“桶列表”,在列表详情,找到自己创建的OBS桶,进入OBS桶详情。
- 在桶的详情页,左侧导航栏选择“对象”,在右侧“名称”列选中不需要的存储对象,单击上方的“删除”或者在操作列单击“更多”,选择“删除”,即可删除相应的存储对象。

使用自定义算法构建模型(手写数字识别)
一、前提条件
已注册华为帐号并开通华为云,且在使用ModelArts前检查帐号状态,帐号不能处于欠费或冻结状态。
二、准备训练数据
本案例使用的数据是MNIST数据集,您可以从MNIST官网下载数据集至本地,以下4个文件均要下载。(需要翻出去)
链接:https://pan.baidu.com/s/1jhfLx3PRU1c9zqZX74tJmQ?pwd=o261
提取码:o261

“train-images-idx3-ubyte.gz”:训练集的压缩包文件。训练集,共包含60000个样本。
“train-labels-idx1-ubyte.gz”:训练集标签的压缩包文件。训练集标签,共包含60000个样本的类别标签。
“t10k-images-idx3-ubyte.gz”:验证集的压缩包文件。验证集,共包含10000个样本。
“t10k-labels-idx1-ubyte.gz”:验证集标签的压缩包文件。验证集标签,共包含10000个样本的类别标签。
三、准备训练文件和推理文件
三个文件:train.py、customize_service.py、config.json
文件类型改为UTF-8
train.py
# base on https://github.com/pytorch/examples/blob/main/mnist/main.py
from __future__ import print_function
import os
import gzip
import codecs
import argparse
from typing import IO, Union
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import shutil
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# 模型训练,设置模型为训练模式,加载训练数据,计算损失函数,执行梯度下降
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
# 模型验证,设置模型为验证模式,加载验证数据,计算损失函数和准确率
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
# pytorch mnist
# https://github.com/pytorch/vision/blob/v0.9.0/torchvision/datasets/mnist.py
def get_int(b: bytes) -> int:
return int(codecs.encode(b, 'hex'), 16)
def open_maybe_compressed_file(path: Union[str, IO]) -> Union[IO, gzip.GzipFile]:
"""Return a file object that possibly decompresses 'path' on the fly.
Decompression occurs when argument `path` is a string and ends with '.gz' or '.xz'.
"""
if not isinstance(path, torch._six.string_classes):
return path
if path.endswith('.gz'):
return gzip.open(path, 'rb')
if path.endswith('.xz'):
return lzma.open(path, 'rb')
return open(path, 'rb')
SN3_PASCALVINCENT_TYPEMAP = {
8: (torch.uint8, np.uint8, np.uint8),
9: (torch.int8, np.int8, np.int8),
11: (torch.int16, np.dtype('>i2'), 'i2'),
12: (torch.int32, np.dtype('>i4'), 'i4'),
13: (torch.float32, np.dtype('>f4'), 'f4'),
14: (torch.float64, np.dtype('>f8'), 'f8')
}
def read_sn3_pascalvincent_tensor(path: Union[str, IO], strict: bool = True) -> torch.Tensor:
"""Read a SN3 file in "Pascal Vincent" format (Lush file 'libidx/idx-io.lsh').
Argument may be a filename, compressed filename, or file object.
"""
# read
with open_maybe_compressed_file(path) as f:
data = f.read()
# parse
magic = get_int(data[0:4])
nd = magic % 256
ty = magic // 256
assert 1 <= nd <= 3
assert 8 <= ty <= 14
m = SN3_PASCALVINCENT_TYPEMAP[ty]
s = [get_int(data[4 * (i + 1): 4 * (i + 2)]) for i in range(nd)]
parsed = np.frombuffer(data, dtype=m[1], offset=(4 * (nd + 1)))
assert parsed.shape[0] == np.prod(s) or not strict
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
def read_label_file(path: str) -> torch.Tensor:
with open(path, 'rb') as f:
x = read_sn3_pascalvincent_tensor(f, strict=False)
assert(x.dtype == torch.uint8)
assert(x.ndimension() == 1)
return x.long()
def read_image_file(path: str) -> torch.Tensor:
with open(path, 'rb') as f:
x = read_sn3_pascalvincent_tensor(f, strict=False)
assert(x.dtype == torch.uint8)
assert(x.ndimension() == 3)
return x
def extract_archive(from_path, to_path):
to_path = os.path.join(to_path, os.path.splitext(os.path.basename(from_path))[0])
with open(to_path, "wb") as out_f, gzip.GzipFile(from_path) as zip_f:
out_f.write(zip_f.read())
# --- pytorch mnist
# --- end
# raw mnist 数据处理
def convert_raw_mnist_dataset_to_pytorch_mnist_dataset(data_url):
"""
raw
{data_url}/
train-images-idx3-ubyte.gz
train-labels-idx1-ubyte.gz
t10k-images-idx3-ubyte.gz
t10k-labels-idx1-ubyte.gz
processed
{data_url}/
train-images-idx3-ubyte.gz
train-labels-idx1-ubyte.gz
t10k-images-idx3-ubyte.gz
t10k-labels-idx1-ubyte.gz
MNIST/raw
train-images-idx3-ubyte
train-labels-idx1-ubyte
t10k-images-idx3-ubyte
t10k-labels-idx1-ubyte
MNIST/processed
training.pt
test.pt
"""
resources = [
"train-images-idx3-ubyte.gz",
"train-labels-idx1-ubyte.gz",
"t10k-images-idx3-ubyte.gz",
"t10k-labels-idx1-ubyte.gz"
]
pytorch_mnist_dataset = os.path.join(data_url, 'MNIST')
raw_folder = os.path.join(pytorch_mnist_dataset, 'raw')
processed_folder = os.path.join(pytorch_mnist_dataset, 'processed')
os.makedirs(raw_folder, exist_ok=True)
os.makedirs(processed_folder, exist_ok=True)
print('Processing...')
for f in resources:
extract_archive(os.path.join(data_url, f), raw_folder)
training_set = (
read_image_file(os.path.join(raw_folder, 'train-images-idx3-ubyte')),
read_label_file(os.path.join(raw_folder, 'train-labels-idx1-ubyte'))
)
test_set = (
read_image_file(os.path.join(raw_folder, 't10k-images-idx3-ubyte')),
read_label_file(os.path.join(raw_folder, 't10k-labels-idx1-ubyte'))
)
with open(os.path.join(processed_folder, 'training.pt'), 'wb') as f:
torch.save(training_set, f)
with open(os.path.join(processed_folder, 'test.pt'), 'wb') as f:
torch.save(test_set, f)
print('Done!')
def main():
# 定义可以接收的训练作业运行参数
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--data_url', type=str, default=False,
help='mnist dataset path')
parser.add_argument('--train_url', type=str, default=False,
help='mnist model path')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
# 设置使用 GPU 还是 CPU 来运行算法
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {
'batch_size': args.batch_size}
test_kwargs = {
'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {
'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
# 定义数据预处理方法
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 将 raw mnist 数据集转换为 pytorch mnist 数据集
convert_raw_mnist_dataset_to_pytorch_mnist_dataset(args.data_url)
# 分别创建训练和验证数据集
dataset1 = datasets.MNIST(args.data_url, train=True, download=False,
transform=transform)
dataset2 = datasets.MNIST(args.data_url, train=False, download=False,
transform=transform)
# 分别构建训练和验证数据迭代器
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
# 初始化神经网络模型并拷贝模型到计算设备上
model = Net().to(device)
# 定义训练优化器和学习率策略,用于梯度下降计算
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
# 训练神经网络,每一轮进行一次验证
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
# 保存模型与适配 ModelArts 推理模型包规范
if args.save_model:
# 在 train_url 训练参数对应的路径内创建 model 目录
model_path = os.path.join(args.train_url, 'model')
os.makedirs(model_path, exist_ok = True)
# 按 ModelArts 推理模型包规范,保存模型到 model 目录内
torch.save(model.state_dict(), os.path.join(model_path, 'mnist_cnn.pt'))
# 拷贝推理代码与配置文件到 model 目录内
the_path_of_current_file = os.path.dirname(__file__)
shutil.copyfile(os.path.join(the_path_of_current_file, 'infer/customize_service.py'), os.path.join(model_path, 'customize_service.py'))
shutil.copyfile(os.path.join(the_path_of_current_file, 'infer/config.json'), os.path.join(model_path, 'config.json'))
if __name__ == '__main__':
main()
customize_service.py
import os
import log
import json
import torch.nn.functional as F
import torch.nn as nn
import torch
import torchvision.transforms as transforms
import numpy as np
from PIL import Image
from model_service.pytorch_model_service import PTServingBaseService
logger = log.getLogger(__name__)
# 定义模型预处理
infer_transformation = transforms.Compose([
transforms.Resize(28),
transforms.CenterCrop(28),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
class PTVisionService(PTServingBaseService):
def __init__(self, model_name, model_path):
# 调用父类构造方法
super(PTVisionService, self).__init__(model_name, model_path)
# 调用自定义函数加载模型
self.model = Mnist(model_path)
# 加载标签
self.label = [0,1,2,3,4,5,6,7,8,9]
def _preprocess(self, data):
preprocessed_data = {
}
for k, v in data.items():
input_batch = []
for file_name, file_content in v.items():
with Image.open(file_content) as image1:
# 灰度处理
image1 = image1.convert("L")
if torch.cuda.is_available():
input_batch.append(infer_transformation(image1).cuda())
else:
input_batch.append(infer_transformation(image1))
input_batch_var = torch.autograd.Variable(torch.stack(input_batch, dim=0), volatile=True)
print(input_batch_var.shape)
preprocessed_data[k] = input_batch_var
return preprocessed_data
def _postprocess(self, data):
results = []
for k, v in data.items():
result = torch.argmax(v[0])
result = {
k: self.label[result]}
results.append(result)
return results
def _inference(self, data):
result = {
}
for k, v in data.items():
result[k] = self.model(v)
return result
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def Mnist(model_path, **kwargs):
# 生成网络
model = Net()
# 加载模型
if torch.cuda.is_available():
device = torch.device('cuda')
model.load_state_dict(torch.load(model_path, map_location="cuda:0"))
else:
device = torch.device('cpu')
model.load_state_dict(torch.load(model_path, map_location=device))
# CPU 或者 GPU 映射
model.to(device)
# 声明为推理模式
model.eval()
return model
config.json
{
"model_algorithm": "image_classification",
"model_type": "PyTorch",
"runtime": "pytorch_1.8.0-cuda_10.2-py_3.7-ubuntu_18.04-x86_64"
}
四、创建OBS桶并上传文件
将训练使用的数据和代码文件、推理代码文件与推理配置文件,上传到OBS桶中。在 ModelArts 上运行训练作业时,需要从OBS桶中读取数据和代码文件。
1.登录OBS管理控制台,按照如下示例创建OBS桶和文件夹。
{
OBS桶} # OBS对象桶,用户可以自定义名称,例如:test-modelarts-xx
-{
OBS文件夹} # OBS文件夹,自定义名称,此处举例为pytorch
- mnist-data # OBS文件夹,用于存放训练数据集,可以自定义名称,此处举例为mnist-data
- mnist-code # OBS文件夹,用于存放训练脚本train.py,可以自定义名称,此处举例为mnist-code
- infer # OBS文件夹,用于存放推理脚本customize_service.py和配置文件config.json
- mnist-output # OBS文件夹,用于存放训练输出模型,可以自定义名称,此处举例为mnist-output
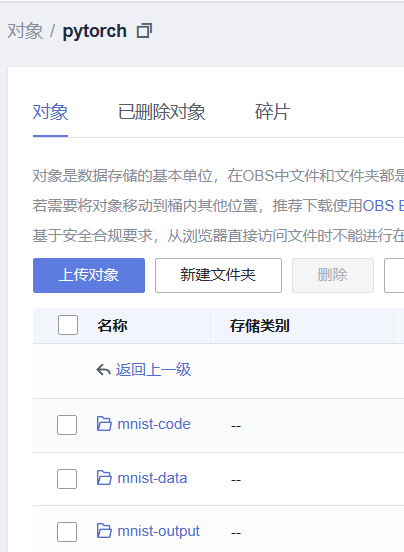
2.上传数据集到“mnist-data”文件夹中
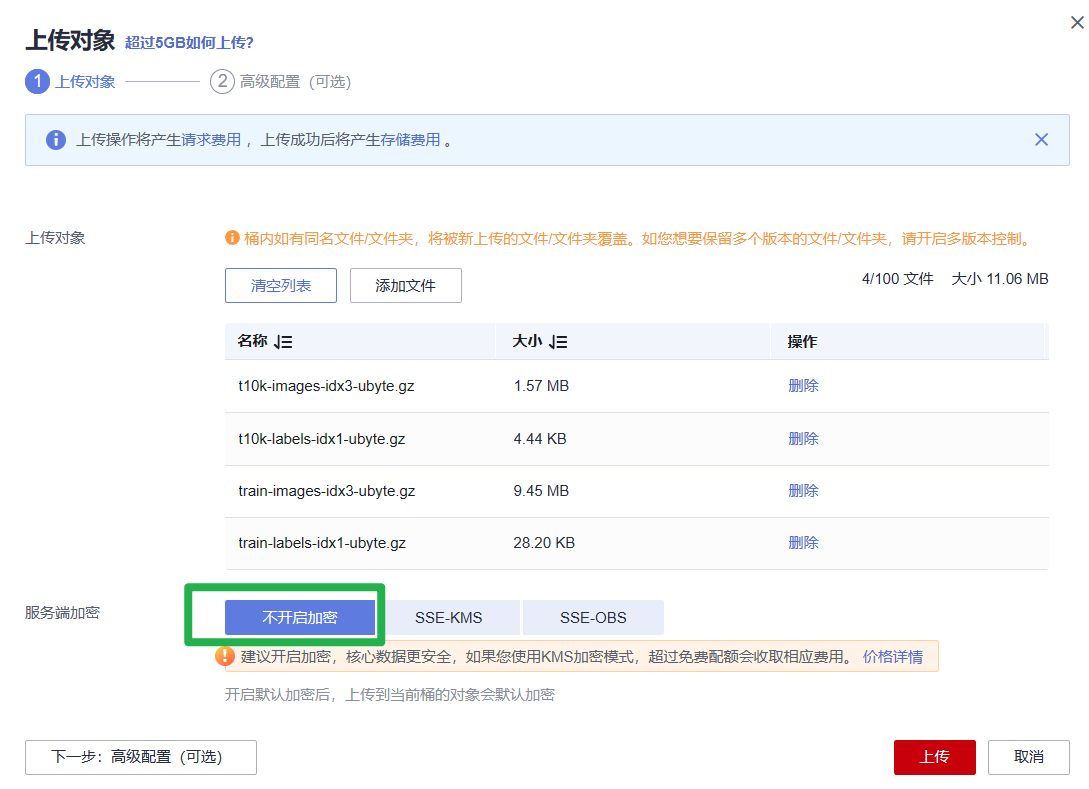
3.上传训练脚本“train.py”到“mnist-code”文件夹中。
4.上传推理脚本“customize_service.py”和推理配置文件“config.json”到“infer”文件中。
五、创建训练作业
1.登录ModelArts管理控制台,选择和OBS桶相同的区域。
2.在“全局配置”中检查当前帐号是否已完成访问授权的配置。如未完成,请参考使用委托授权**。**针对之前使用访问密钥授权的用户,建议清空授权,然后使用委托进行授权。
3.在左侧导航栏的“训练管理”-> “训练作业”中,单击“创建训练作业”。填写创建训练作业相关信息。
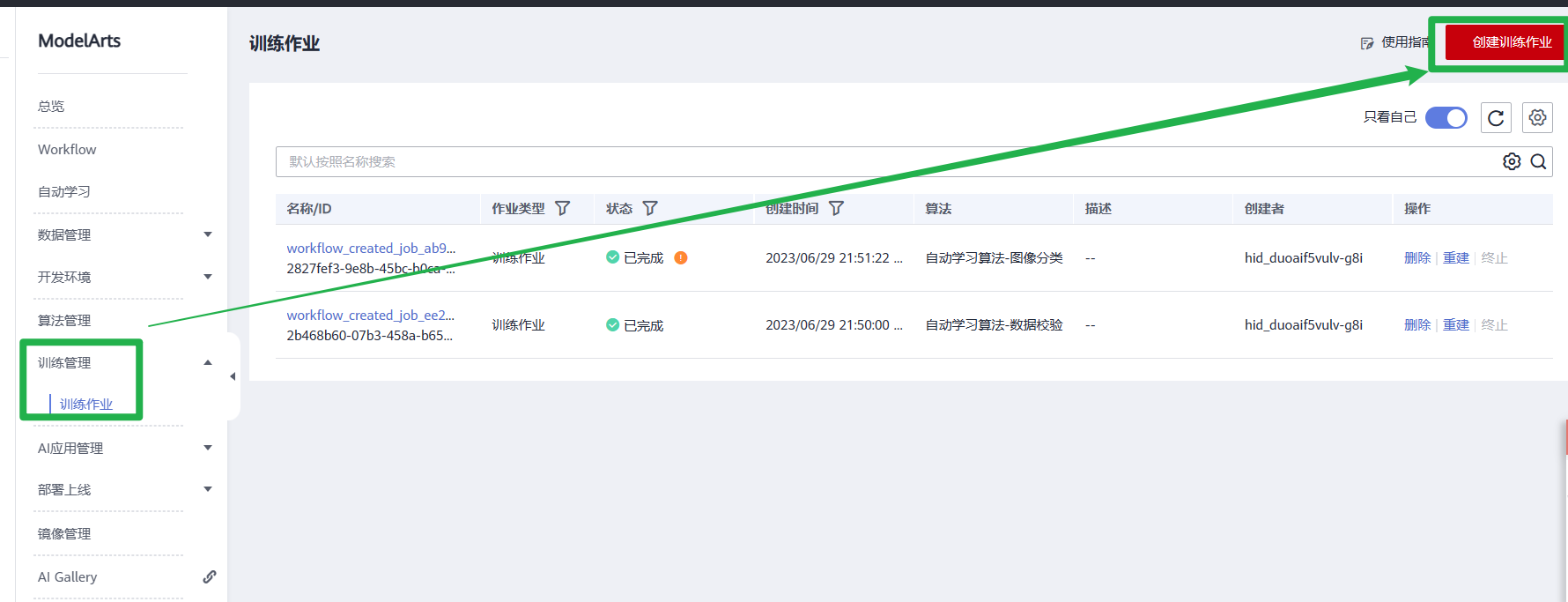
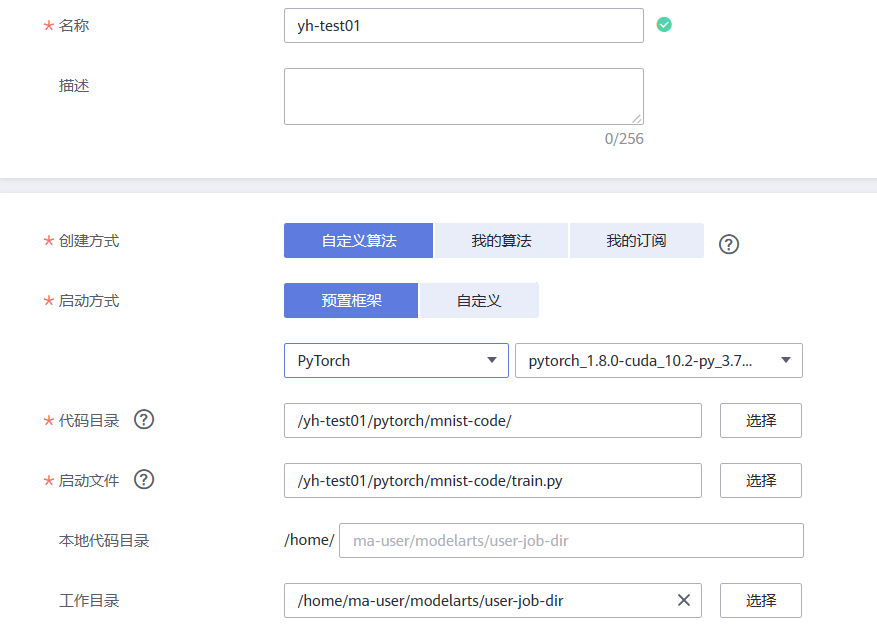
- 创建方式:选择“自定义算法”。
- 启动方式:选择“预置框架”,下拉框中选择PyTorch,pytorch_1.8.0-cuda_10.2-py_3.7-ubuntu_18.04-x86_64。
- 代码目录:选择已创建的代码目录路径“/test-modelarts-xx/pytorch/mnist-code/”。
- 启动文件:选择代码目录下上传的训练脚本“train.py”。
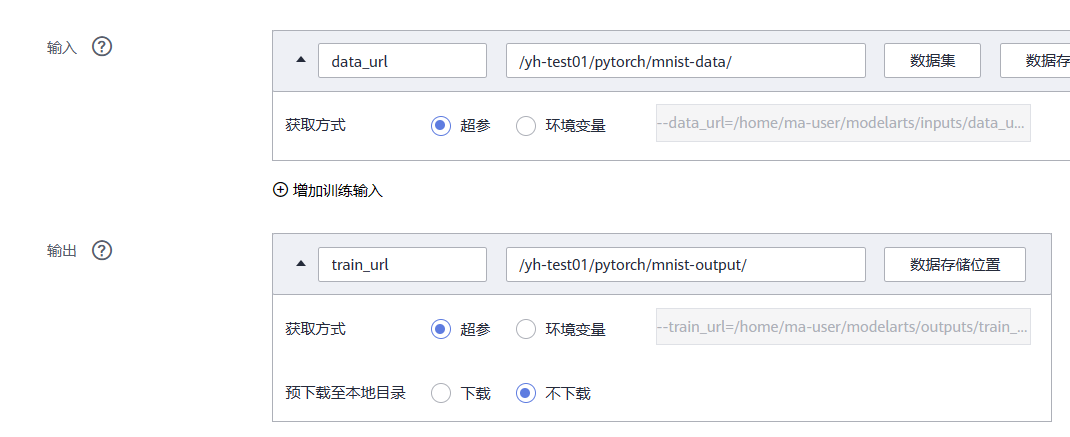
- 输入:单击“添加”,设置训练输入的**“参数名称”**为“data_url”。设置数据存储位置为 “/test-modelarts-xx/pytorch/mnist-data/”。
- 输出:单击“添加”,设置训练输出的**“参数名称”**为“train_url”。设置数据存储位置为 “/test-modelarts-xx/pytorch/mnist-output/”
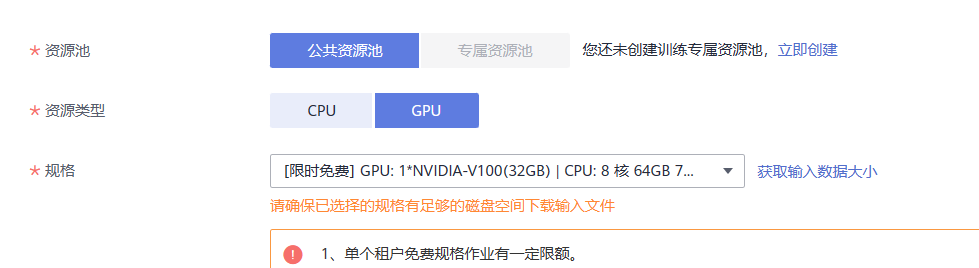
- 资源类型:选择 GPU 单卡的规格,如“GPU: 1*NVIDIA-V100(16GB) | CPU: 8 核 64GB 780GB”。
4.单击“提交”,确认训练作业的参数信息,确认无误后单击“确定”
5.页面自动返回“训练作业”列表页,当训练作业状态变为“已完成”时,即完成了模型训练过程

6.单击训练作业名称,进入作业详情界面查看训练作业日志信息,观察日志是否有明显的Error信息,如果有则表示训练失败,请根据日志提示定位原因并解决。
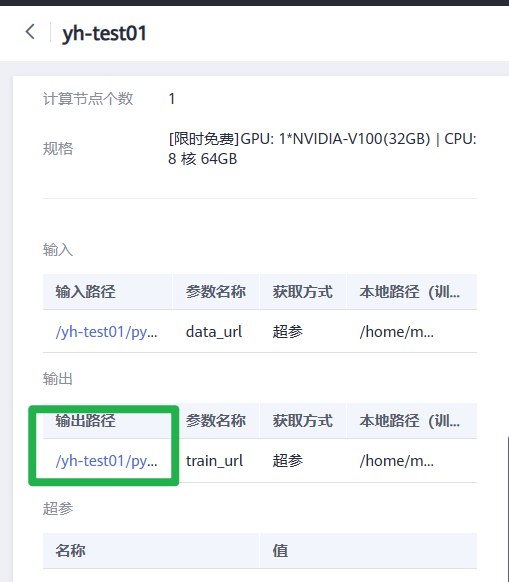
7.在训练详情页左下方单击训练输出路径,跳转到OBS目录,查看是否存在model文件夹,且model文件夹中是否有生成训练模型。如果未生成model文件夹或者训练模型,可能是训练输入数据不完整导致,请检查训练数据上传是否完整,并重新训练。
六、推理部署
模型训练完成后,可以创建AI应用,将AI应用部署为在线服务。
1.在ModelArts管理控制台,单击左侧导航栏中的“AI应用管理>AI应用”,进入“我的AI应用”页面,单击“创建”。
2.在“创建AI应用”页面,填写相关参数,然后单击“立即创建”。
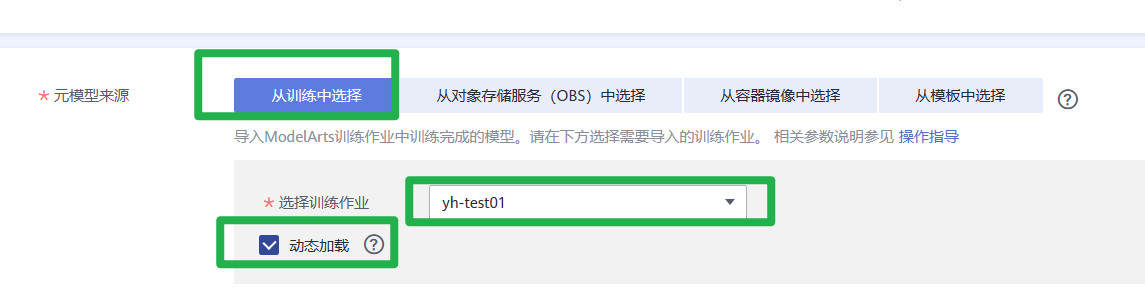
在AI应用列表页面,当AI应用状态变为“正常”时,表示AI应用创建成功。

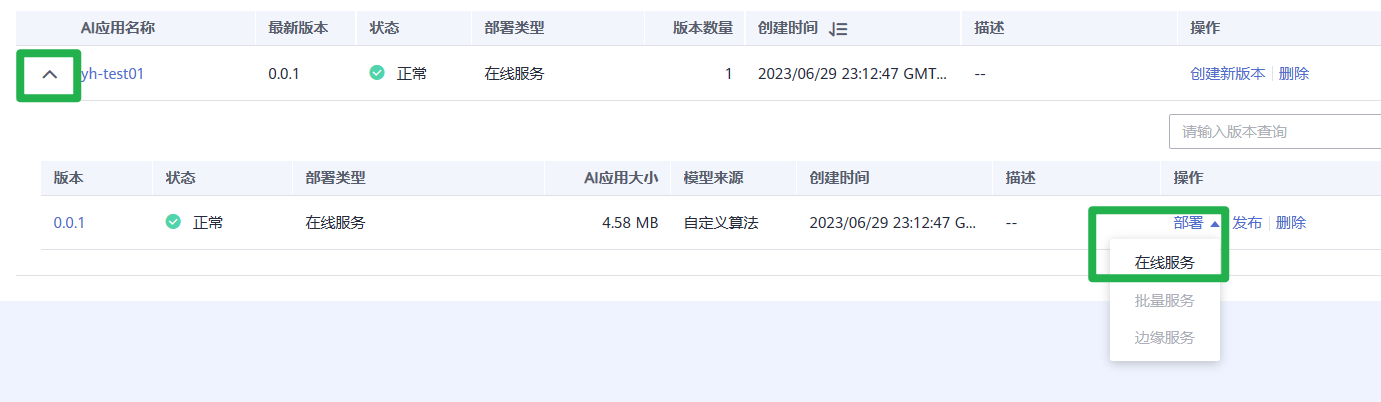
3.单击AI应用名称左侧的小三角,打开此AI应用下的所有版本。在对应版本所在行,单击操作列“部署>在线服务”,将AI应用部署为在线服务。
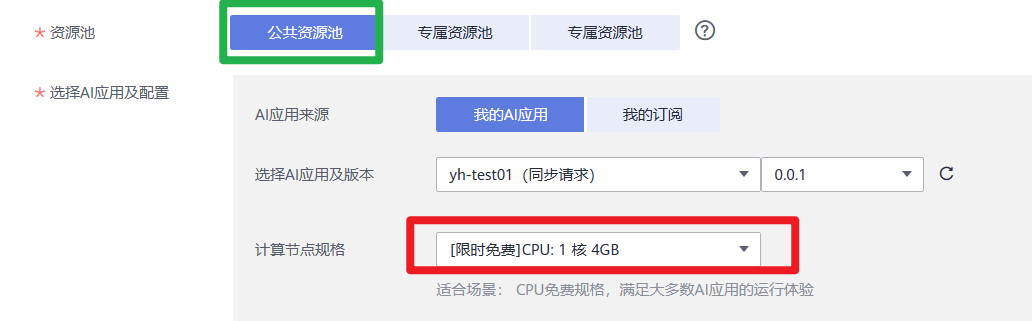
4.在“部署”页面,参考下图填写参数,然后根据界面提示完成在线服务创建。本案例适用于CPU规格,节点规格需选择CPU
5.完成服务部署后,返回在线服务页面列表页,等待服务部署完成,当服务状态显示为“运行中”,表示服务已部署成功。
七、预测结果
1.在“在线服务”页面,单击在线服务名称,进入服务详情页面。
2.单击“预测”页签,请求类型选择“multipart/form-data”,请求参数填写“image”,单击“上传”按钮上传示例图片,然后单击“预测”。

八、清除资源
如果不再需要使用此模型及在线服务,建议清除相关资源,避免产生不必要的费用。
在“在线服务”页面,“停止”或“删除”刚创建的在线服务。
在“AI应用管理”页面,“删除”刚创建的AI应用。
在“训练作业”页面,“删除”运行结束的训练作业。
进入OBS,删除本示例使用的OBS 桶及文件夹,以及文件夹的文件。
”页面,单击“创建”。