1 准备
1.1 本地虚拟机器准备
使用本地搭建三台机器,搭建数仓,模拟实际平台数据仓库的搭建。具体的搭建框架如下
| 安装软件 | 角色 | 主机1 | 主机2 | 主机3 |
|---|---|---|---|---|
| Hadoop | NameNode | √ | ||
| SecondaryNameNode | √ | |||
| DataNode | √ | √ | √ | |
| NodeManager | √ | √ | √ | |
| ResourceManager | √ | √ | ||
| Zookeeper | zk server | √ | √ | √ |
| Flume | flume | √ | ||
| Kafka | kafka | √ | √ | √ |
| Hive | hive | √ | ||
| Mysql | mysql | √ | √ |
1.2 项目技术选型
| 类型 | 技术 |
|---|---|
| 数据采集 | Flum,Kafka,Sqoop,Logstash,DataX |
| 数据存储 | Mysql,HDFS,Hbase,Redis,MongoDB |
| 数据计算 | HIve,Tez,Spark,Flink,Storm |
| 数据查询 | Presto,Druid,Impala,Kylin |
1.3 数据来源
数据来自本地模拟创建的数据,数据格式内容如下:
{
"ap":"xxxxx",//项目数据来源 app pc
"cm": {
//公共字段
"mid": "", // (String) 设备唯一标识
"uid": "", // (String) 用户标识
"vc": "1", // (String) versionCode,程序版本号
"vn": "1.0", // (String) versionName,程序版本名
"l": "zh", // (String) language系统语言
"sr": "", // (String) 渠道号,应用从哪个渠道来的。
"os": "7.1.1", // (String) Android系统版本
"ar": "CN", // (String) area区域
"md": "BBB100-1", // (String) model手机型号
"ba": "blackberry", // (String) brand手机品牌
"sv": "V2.2.1", // (String) sdkVersion
"g": "", // (String) gmail
"hw": "1620x1080", // (String) heightXwidth,屏幕宽高
"t": "1506047606608", // (String) 客户端日志产生时的时间
"nw": "WIFI", // (String) 网络模式
"ln": 0, // (double) lng经度
"la": 0 // (double) lat 纬度
},
"et": [ //事件
{
"ett": "1506047605364", //客户端事件产生时间
"en": "display", //事件名称
"kv": {
//事件结果,以key-value形式自行定义
"goodsid": "236",
"action": "1",
"extend1": "1",
"place": "2",
"category": "75"
}
}
]
}
样例:
1540934156385|{
"ap": "gmall",
"cm": {
"uid": "1234",
"vc": "2",
"vn": "1.0",
"la": "EN",
"sr": "",
"os": "7.1.1",
"ar": "CN",
"md": "BBB100-1",
"ba": "blackberry",
"sv": "V2.2.1",
"g": "[email protected]",
"hw": "1620x1080",
"t": "1506047606608",
"nw": "WIFI",
"ln": 0
},
"et": [
{
"ett": "1506047605364", //客户端事件产生时间
"en": "display", //事件名称
"kv": {
//事件结果,以key-value形式自行定义
"goodsid": "236",
"action": "1",
"extend1": "1",
"place": "2",
"category": "75"
}
},{
"ett": "1552352626835",
"en": "active_background",
"kv": {
"active_source": "1"
}
}
]
}
}
2 软件安装
2.1 安装hadoop
2.1.1 配置支持LZO压缩
安装过程不再赘述,注意这里的hadoop需要支持LZO压缩格式。配置core-site.yml文件内容如下,支持LZO
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
2.1.2 进行HDFS读写性能测试
向HDFS集群写10个128M的文件
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
读取HDFS集群10个128M的文件
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
2.1.3 hadoop调优
① HDFS参数调优hdfs-site.xm
dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为8台时,此参数设置为60
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。
② 编辑日志存储路径dfs.namenode.edits.dir设置与镜像文件存储路径dfs.namenode.name.dir尽量分开,达到最低写入延迟
③ YARN参数调优yarn-site.xml
情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,
和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
2.2 安装zookeeper
三节点安装三个,安装的大致流程可以看这篇文章,这里具体安装流程不再赘述
2.3 安装Flume
具体安装流程可以看这篇文章
2.4 安装Kafka
安装具体可以看这篇文章
2.4.1 压测
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000
--throughput 1000 --producer-props bootstrap.servers=wavehouse-1:9092,wavehouse-2:9092
,wavehouse-3:9092
#record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。
#throughput 是每秒多少条信息。
2.4.2 kafka数量计算
Kafka机器数量(经验公式)=2*(峰值生产速度副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。 比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量=2(50*2/100)+ 1=3台
3 dwd数据明细层
3.1 安装Mysql
3.1.1 Keepalived介绍
这里使用keepalived实现Mysql的高可用,Keepalived是基于VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议)协议的一款高可用软件。Keepailived有一台主服务器(master)和多台备份服务器(backup),在主服务器和备份服务器上面部署相同的服务配置,使用一个虚拟IP地址对外提供服务,当主服务器出现故障时,虚拟IP地址会自动漂移到备份服务器。
3.1.2 配置双主模式
| wavehouse-1 | Mysql(master,slave) |
|---|---|
| wavehouse-2 | Mysql(slave,master) |
wavehouse-1节点中MySQL的/usr/my.cnf配置文件
[mysqld]
#开启binlog
log_bin = mysql-bin
#binlog日志类型
binlog_format = row
#MySQL服务器唯一id
server_id = 2
#开启slave中继日志
relay_log=mysql-relay
重启wavehouse-1的mysql服务
service mysql restart
配置wavehouse-2节点
[mysqld]
#MySQL服务器唯一id
server_id = 1
#开启binlog
log_bin = mysql-bin
#binlog日志类型
binlog_format = row
#开启slave中继日志
relay_log=mysql-relay
重启Mysql服务
service mysql restart
配置wavehouse-1节点keepalived配置文件/etc/keepalived/keepalived.conf
global_defs {
router_id MySQL-ha
}
vrrp_instance VI_1 {
state master #初始状态
interface eth0 #网卡
virtual_router_id 51 #虚拟路由id
priority 100 #优先级
advert_int 1 #Keepalived心跳间隔
nopreempt #只在高优先级配置,原master恢复之后不重新上位
authentication {
auth_type PASS #认证相关
auth_pass 1111
}
virtual_ipaddress {
192.168.1.100 #虚拟ip
}
}
#声明虚拟服务器
virtual_server 192.168.1.100 3306 {
delay_loop 6
persistence_timeout 30
protocol TCP
#声明真实服务器
real_server 192.168.1.103 3306 {
notify_down /var/lib/mysql/killkeepalived.sh #真实服务故障后调用脚本
TCP_CHECK {
connect_timeout 3 #超时时间
nb_get_retry 1 #重试次数
delay_before_retry 1 #重试时间间隔
}
}
}
编辑脚本文件/var/lib/mysql/killkeepalived.sh
#! /bin/bash
service keepalived stop
启动keepalived服务
service keepalived start
配置wavehouse-2节点/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id MySQL-ha
}
vrrp_instance VI_1 {
state master #初始状态
interface eth0 #网卡
virtual_router_id 51 #虚拟路由id
priority 100 #优先级
advert_int 1 #Keepalived心跳间隔
authentication {
auth_type PASS #认证相关
auth_pass 1111
}
virtual_ipaddress {
192.168.1.100 #虚拟ip
}
}
#声明虚拟服务器
virtual_server 192.168.1.100 3306 {
delay_loop 6
persistence_timeout 30
protocol TCP
#声明真实服务器
real_server 192.168.1.104 3306 {
notify_down /var/lib/mysql/killkeepalived.sh #真实服务故障后调用脚本
TCP_CHECK {
connect_timeout 3 #超时时间
nb_get_retry 1 #重试次数
delay_before_retry 1 #重试时间间隔
}
}
}
其他修改内容同wavehouse-1节点
3.2 安装Hive
3.2.1 准备条件
① 保证环境已安装jdk,且JAVA_HOME变量存在
② hadoop已完成安装,HADOOP_HOME已配置
③ 配置HIVE_HOME
④ 拷贝Mysql驱动jar包到Hive的lib目录下
3.2.2 配置文件修改
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.2.100:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
注意这里jdbc的链接Ip要配置为虚拟ip,这里的链接密码根据前面mysql设置的密码填写。
3.2.3 在mysql中创建metastore表
metastore表,并指定字符集为latin1
以上配置完成后,启动hive成功后会在mysql的metastore数据库生成很多hive的原始数据表
3.3 安装Tez
Tez是一个Hive的运行引擎,性能优于MR。为什么优于MR呢?看下图。
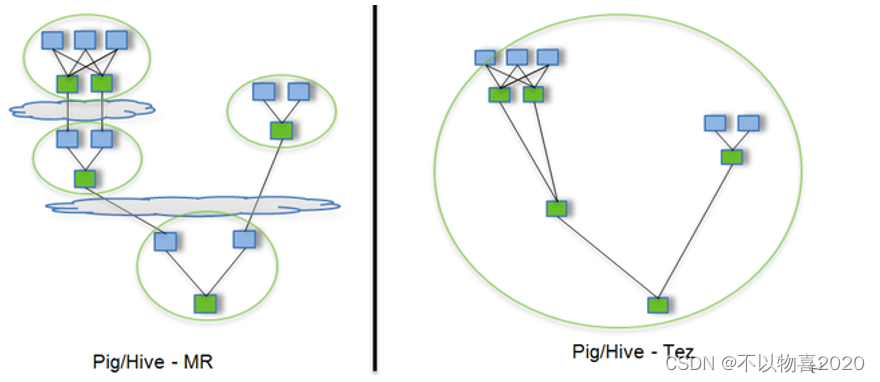
用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
3.3.1 解压Tez包并上传到hdfs
由于Hive只安装在wavehouse-1节点,当执行任务时,需要到其他集群执行任务时,其他节点没有tez的包,因此上传到hdfs当需要使用时,从hdfs去获取。
hadoop fs -mkdir /tez
hadoop fs -put /root/soft/apache-tez-0.9.1-bin.tar.gz /tez
3.3.2 配置hive中的tez
在hive的conf目录下新建tez-site.xml文件,并加入如下内容。这里配置tez在hdfs中的路径
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/apache-tez-0.9.1-bin.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>
3.3.3 修改hive-env.sh
添加如下内容,让hive启动时加载Tez引擎的jar包
export TEZ_HOME=/opt/module/tez-0.9.1 #是你的tez的解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS
3.3.4 hive-site.xml修改为tez引擎
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
3.3.5 修改hive-site.xml元数据校验
0.9版本的Tez有对应的hive版本,为了不触发校验,设置配置
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
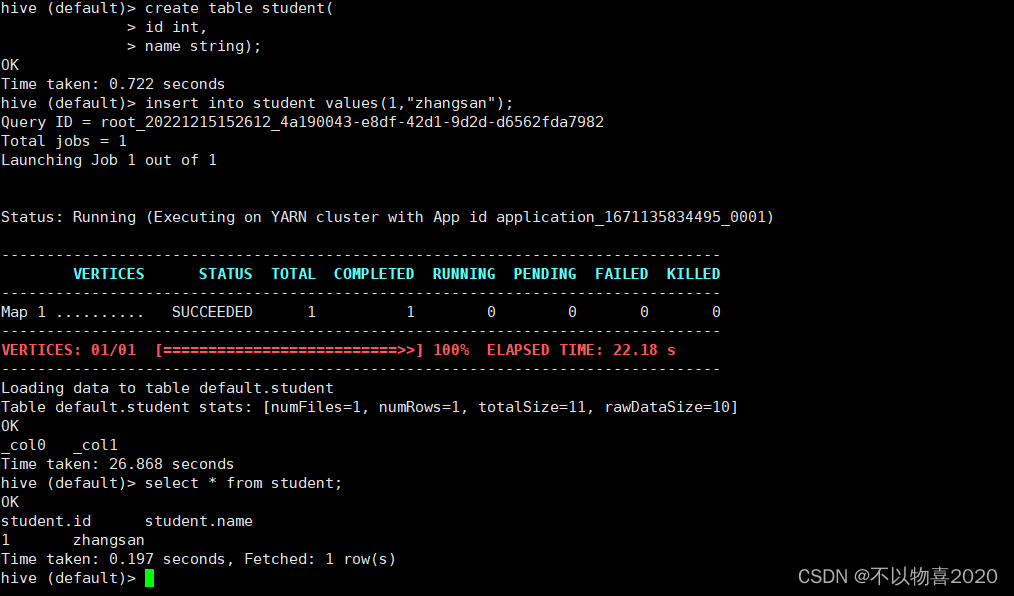
3.3.6 测试
启动hive,并执行建表语句
create table student(
id int,
name string);
插入数据
insert into student values(1,"zhangsan");
看到如下页面则说明,Tez已部署好
3.3.7 可能遇到的问题
以Tez为引擎执行时报错:
Caused by: org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1546781144082_0005 failed 2 times due to AM Container for appattempt_1546781144082_0005_000002 exited with exitCode: -103
For more detailed output, check application tracking page:http://wavehouse-1:8088/cluster/app/application_1546781144082_0005Then, click on links to logs of each attempt.
Diagnostics: Container [pid=11116,containerID=container_1546781144082_0005_02_000001] is running beyond virtual memory limits. Current usage: 216.3 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.
解决方案:
这种问题是从机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
关掉虚拟内存检查,修改yarn-site.xml,修改后一定要分发,并重新启动hadoop集群。
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
3 ods原始数据层导入数据
3.1 创建数据库
create database gmall;
use gmall;
3.2 创建启动日志表
CREATE EXTERNAL TABLE ods_start_log (`line` string) PARTITIONED BY (`dt` string)
stored as INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/wavehouse/gmall/ods/ods_start_log'
3.3 加载数据
load data inpath '/origin_data/gmall/log/topic_start/2022-12-05' into table gmall.ods_start_log partition(dt='2022-12-05');
查看是否加载成功
select * from ods_start_log limit 2;
3.4 创建索引
为lzo压缩文件创建索引,lzo压缩文件的可切片特性依赖于其索引,故我们需要手动为lzo压缩文件创建索引。若无索引,则lzo文件的切片只有一个。
hadoop jar /root/soft/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar
com.hadoop.compression.lzo.DistributedLzoIndexer
/user/hive/warehouse/gmall.db/ods_start_log/dt=2022-12-05
4 DWD数据明细层
4.1 创建启动表和事件表
根据ods层中json格式数据字段,在dwd层创建表。
drop table if exists dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`open_ad_type` string,
`action` string,
`loading_time` string,
`detail` string,
`extend1` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_start_log/'
TBLPROPERTIES('parquet.compression'='lzo');
创建事件表
drop table if exists ods_event_log;
CREATE EXTERNAL TABLE ods_event_log(`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/wavehouse/gmall/ods/ods_event_log';
4.2 导入数据
导入数据到原始层启动表
load data inpath '/origin_data/gmall/log/topic_start/2022-12-15' into table gmall.ods_start_log partition(dt='2022-12-15');
load data inpath '/origin_data/gmall/log/topic_start/2022-12-16' into table gmall.ods_start_log partition(dt='2022-12-16');
导入数据到数据原始层事件表
load data inpath '/origin_data/gmall/log/topic_event/2022-12-16' into table gmall.ods_event_log partition(dt='2022-12-16');
load data inpath '/origin_data/gmall/log/topic_event/2022-12-15' into table gmall.ods_event_log partition(dt='2022-12-15');
4.3 创建索引
hadoop jar /root/soft/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /wavehouse/gmall/ods/ods_start_log/dt=2022-12-15
hadoop jar /root/soft/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /wavehouse/gmall/ods/ods_start_log/dt=2022-12-16
hadoop jar /root/soft/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /wavehouse/gmall/ods/ods_event_log/dt=2022-12-15
hadoop jar /root/soft/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /wavehouse/gmall/ods/ods_event_log/dt=2022-12-16
添加完索引,可以在HDFS浏览中查看到相关索引
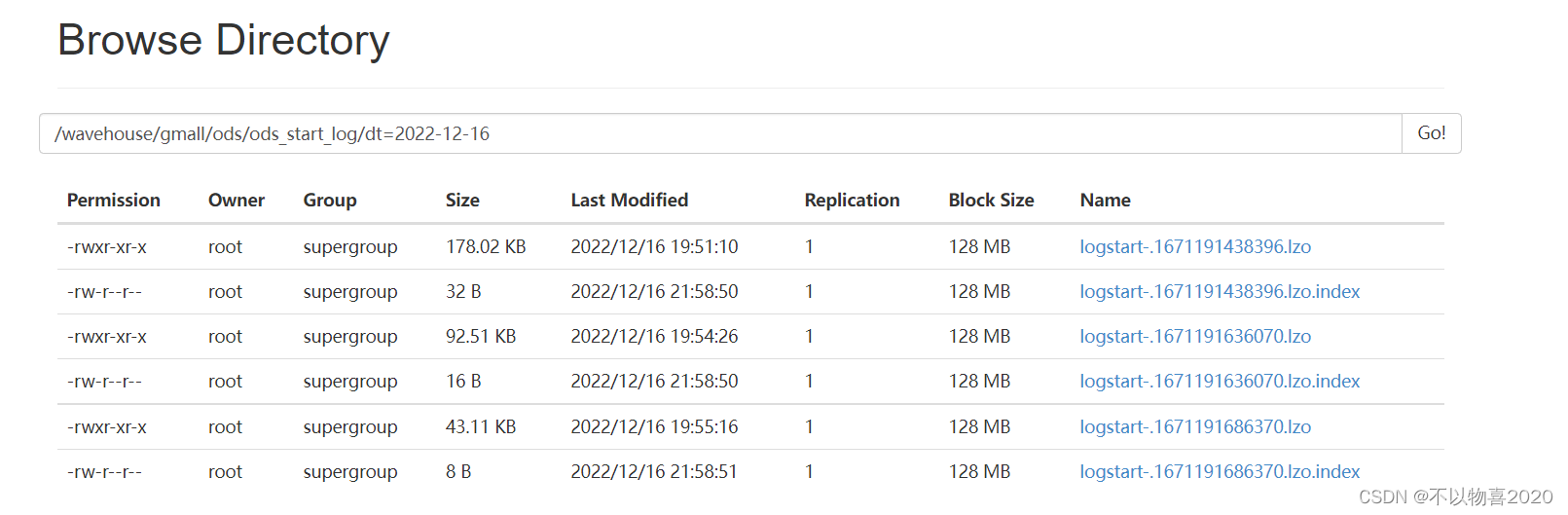
注: 此时原始数据层,数据格式如下:
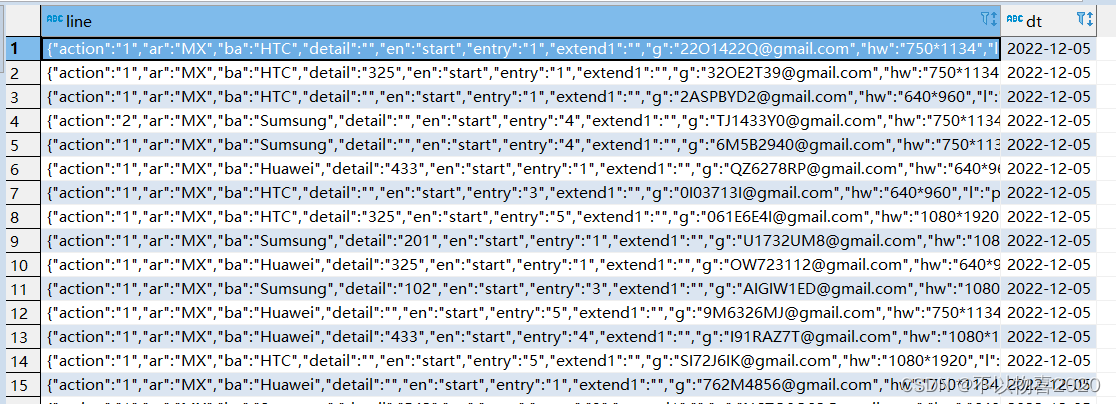
接下来将会在数据明细层DWD进行处理
5 数据明细层DWD
5.1 预备知识
5.1.1 get_json_object函数
A limited version of JSONPath supported: $ : Root object
代表整个JSON对象 . : Child operator 代表获取JSON对象中子元素(属性)的操作符 [] :
Subscript operator for array 获取JSONArray中的某个元素
如下json字符串:
{"name":"jack","age":18,"parents":[{"name":"oldjack","age":48},{"name":"jackmom","age":49}]}
获取18
select get_json_object('{"name":"jack","age":18,"parents":
[{"name":"oldjack","age":48},{"name":"jackmom","age":48}]}','$.age')
获取49
select get_json_object('{"name":"jack","age":18,"parents":
[{"name":"oldjack","age":48},{"name":"jackmom","age":49}]}','$.parents[1].age')
5.2 创建dwd明细表
这里创建表的字段按照ods层中的json数据格式进行,先创建启动明细表
drop table if exists dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`open_ad_type` string,
`action` string,
`loading_time` string,
`detail` string,
`extend1` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_start_log/'
TBLPROPERTIES('parquet.compression'='lzo');
创建事件明细表
drop table if exists dwd_base_event_log;
CREATE EXTERNAL TABLE dwd_base_event_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`event_name` string,
`event_json` string,
`server_time` string)
PARTITIONED BY (`dt` string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_base_event_log/'
TBLPROPERTIES('parquet.compression'='lzo');
5.3 导入数据
按照不同的分区进行导入,其他日期的数据修改相应的分区和查询条件即可。
insert overwrite table dwd_start_log
PARTITION (dt='2022-12-16')
select
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
from ods_start_log
where dt='2022-12-16';
在导入事件数据时需要使用自定义的UDF和UDTF函数,具体实现逻辑如下:
package com.chen.hive.function;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.json.JSONException;
import org.json.JSONObject;
/**
* @author:cc
* @create: 2022-12-16 15:47
* @Description: Never pleased by external gains, and never saddened by personal losses.
* 1671184702500|{"cm":{"ln":"-89.8","sv":"V2.4.7","os":"8.0.6","g":"[email protected]","mid":"1","nw":"4G","l":"en",
* "vc":"11","hw":"640*1136","ar":"MX","uid":"1","t":"1671119837180","la":"-32.4","md":"HTC -6","vn":"1.2.2",
* "ba":"HTC","sr":"E"},"ap":"app","et":[{"ett":"1671126951625","en":"newsdetail","kv":{"entry":"2","goodsid":"0",
* "news_staytime":"0","loading_time":"12","action":"4","showtype":"3","catego ry":"73","type1":""}},
* {"ett":"1671093609828","en":"ad","kv":{"entry":"3","show_style":"3","action":"5","detail":"","source":"3",
* "behavior":"1","content":"1","newstype":"0"}},{"ett":"1671172497391","en":" active_foreground",
* "kv":{"access":"","push_id":"3"}},{"ett":"1671139666780","en":"active_background","kv":{"active_source":"1"}}]}
*/
public class BaseFeildUDF extends UDF {
public String evaluate(String line,String param) throws JSONException {
//1 切割line数据
String[] strings = line.split("\\|");
//2 校验strings
if(strings.length != 2||strings[1] == null){
return "";
}
//3 根据传入参数返回相应的值
String result = "";
JSONObject jsonObject = new JSONObject(strings[1]);
if(param.equalsIgnoreCase("et")){
if(jsonObject.has("et")){
result = jsonObject.getString("et");
}
}else if(param.equalsIgnoreCase("st")){
result = strings[0].trim();
}else {
JSONObject cm = jsonObject.getJSONObject("cm");
if(cm.has(param)){
result = cm.getString(param);
}
}
return result;
}
}
package com.chen.hive.function;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Semaphore;
/**
* @author:cc
* @create: 2022-12-16 16:12
* @Description: Never pleased by external gains, and never saddened by personal losses.
* 数据格式[{},{},{}]
*/
public class EventJsonUDTF extends GenericUDTF {
//在函数运行之前被调用一次,作用是告诉MapTask,当前函数返回的结果类型和个数,以便MapTask在运行时,函数的返回值进行检查
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//当前返回的两列的字段别名
List<String> fieldNames = new ArrayList<String>();
fieldNames.add("event_name");
fieldNames.add("event_json");
// 当前返回的两列的类型检查器
List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
//执行函数的功能,处理数据后调用forward()返回结果,args是传参传过来的参数
// 返回的应该是2列N行的数据,
@Override
public void process(Object[] args) throws HiveException {
//校验传参是否合理
if (args.length == 0 || args[0] == null) return;
//构建json对象
try {
JSONArray jsonArray = new JSONArray(args[0].toString());
if (jsonArray == null || jsonArray.length() == 0) return;
//遍历json数组
for (int i = 0; i < jsonArray.length(); i++) {
try {
//每遍历一次,需要写出去一行两列的数据,构建一个数组,存储一行两列的数据
String [] result = new String[2];
JSONObject jsonObject = jsonArray.getJSONObject(i);
//取事件类型
result[0] = jsonObject.getString("en");
result[1] = jsonObject.toString();
//将result写出
forward(result);
}catch (Exception e){
//过滤有问题的数据,并继续开始遍历下一个{}
continue;
}
}
} catch (JSONException e) {
e.printStackTrace();
}
}
@Override
public void close() throws HiveException {
}
}
打成jar包上传到hive目录下的auxlib目录,如果该目录不存在则新建该目录。注:这里打jar包的时候,如果hive版本比较老可能会遇到不能成功编译的问题,具体可看这篇文章。
5.4 重启hive
测试数据,并保存为/root/hivetest文件
1670356265677|{
"cm":{
"ln":"-66.0","sv":"V2.4.5","os":"8.1.8","g":"[email protected]","mid":"994","nw":"4G","l":"pt","vc":"1","hw":"640*1136","ar":"MX","uid":"994","t":"1670342099717","la":"15.3","md":"HTC-0","vn":"1.3.8","ba":"HTC","sr":"Y"},"ap":"app","et":[{
"ett":"1670335111586","en":"loading","kv":{
"extend2":"","loading_time":"54","action":"1","extend1":"","type":"2","type1":"","loading_way":"2"}},{
"ett":"1670337626239","en":"comment","kv":{
"p_comment_id":1,"addtime":"1670276780061","praise_count":891,"other_id":0,"comment_id":6,"reply_count":103,"userid":3,"content":"瞅非衅鸯垂棠应"}},{
"ett":"1670278354353","en":"praise","kv":{
"target_id":9,"id":1,"type":3,"add_time":"1670320899047","userid":0}}]}
启动hive时将样例指定为特殊变量chen,方便调用。
hive -d chen=$(cat /root/hivetest)
5.5 创建函数
create function base_analizer as 'com.chen.hive.function.BaseFeildUDF'
create function flat_analizer as 'com.chen.hive.function.EventJsonUDTF'

测试:

5.6 利用自定义函数插入dwd层数据
利用自定义的函数,将数据经过处理之后插入dwd_base_event_log表
insert overwrite TABLE gmall.dwd_base_event_log PARTITION(dt='2022-12-16')
SELECT
base_analizer(line,'mid') as mid_id,
base_analizer(line,'uid') as user_id,
base_analizer(line,'vc') as version_code,
base_analizer(line,'vn') as version_name,
base_analizer(line,'l') as lang,
base_analizer(line,'sr') as source,
base_analizer(line,'os') as os,
base_analizer(line,'ar') as area,
base_analizer(line,'md') as model,
base_analizer(line,'ba') as brand,
base_analizer(line,'sv') as sdk_version,
base_analizer(line,'g') as gmail,
base_analizer(line,'hw') as height_width,
base_analizer(line,'t') as app_time,
base_analizer(line,'nw') as network,
base_analizer(line,'ln') as lng,
base_analizer(line,'la') as lat,
en event_name,
ej event_json,
base_analizer(line,'st') as server_time
FROM
gmall.ods_event_log LATERAL VIEW flat_analizer(base_analizer(line,'et')) tmp as en,ej
WHERE dt='2022-12-16';
这里的flat_analizer函数需要配合lateral view使用,该功能是一个侧写视图,根据返回的视图插入新表中。其他日期的数据修改分区时间和ods_event_log表查询时间即可插入。
5.7 创建明细表
根据dwd_base_event_log中不同的even_name创建不同类型的表。
5.7.1 商品点击表
drop table if exists dwd_display_log;
CREATE EXTERNAL TABLE dwd_display_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`action` string,
`goodsid` string,
`place` string,
`extend1` string,
`category` string,
`server_time` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_display_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_display_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.goodsid') goodsid,
get_json_object(event_json,'$.kv.place') place,
get_json_object(event_json,'$.kv.extend1') extend1,
get_json_object(event_json,'$.kv.category') category,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='display';

5.7.2 商品详情页表
drop table if exists dwd_newsdetail_log;
CREATE EXTERNAL TABLE dwd_newsdetail_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`action` string,
`goodsid` string,
`showtype` string,
`news_staytime` string,
`loading_time` string,
`type1` string,
`category` string,
`server_time` string)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_newsdetail_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_newsdetail_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.entry') entry,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.goodsid') goodsid,
get_json_object(event_json,'$.kv.showtype') showtype,
get_json_object(event_json,'$.kv.news_staytime') news_staytime,
get_json_object(event_json,'$.kv.loading_time') loading_time,
get_json_object(event_json,'$.kv.type1') type1,
get_json_object(event_json,'$.kv.category') category,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='newsdetail';
5.7.3 商品列表页表
drop table if exists dwd_loading_log;
CREATE EXTERNAL TABLE dwd_loading_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`action` string,
`loading_time` string,
`loading_way` string,
`extend1` string,
`extend2` string,
`type` string,
`type1` string,
`server_time` string)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_loading_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_loading_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.loading_time') loading_time,
get_json_object(event_json,'$.kv.loading_way') loading_way,
get_json_object(event_json,'$.kv.extend1') extend1,
get_json_object(event_json,'$.kv.extend2') extend2,
get_json_object(event_json,'$.kv.type') type,
get_json_object(event_json,'$.kv.type1') type1,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='loading';
5.7.4 广告表
drop table if exists dwd_ad_log;
CREATE EXTERNAL TABLE dwd_ad_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`action` string,
`content` string,
`detail` string,
`ad_source` string,
`behavior` string,
`newstype` string,
`show_style` string,
`server_time` string)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_ad_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_ad_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.entry') entry,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.content') content,
get_json_object(event_json,'$.kv.detail') detail,
get_json_object(event_json,'$.kv.source') ad_source,
get_json_object(event_json,'$.kv.behavior') behavior,
get_json_object(event_json,'$.kv.newstype') newstype,
get_json_object(event_json,'$.kv.show_style') show_style,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='ad';
5.7.5 消息通知表
drop table if exists dwd_notification_log;
CREATE EXTERNAL TABLE dwd_notification_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`action` string,
`noti_type` string,
`ap_time` string,
`content` string,
`server_time` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_notification_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_notification_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.noti_type') noti_type,
get_json_object(event_json,'$.kv.ap_time') ap_time,
get_json_object(event_json,'$.kv.content') content,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='notification';
5.7.6 用户前台活跃表
drop table if exists dwd_active_foreground_log;
CREATE EXTERNAL TABLE dwd_active_foreground_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`push_id` string,
`access` string,
`server_time` string)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_foreground_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_active_foreground_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.push_id') push_id,
get_json_object(event_json,'$.kv.access') access,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='active_foreground';
5.7.7 用户后台活跃表
drop table if exists dwd_active_background_log;
CREATE EXTERNAL TABLE dwd_active_background_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`active_source` string,
`server_time` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_background_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_active_background_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.active_source') active_source,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='active_background';
5.7.8 评论表
drop table if exists dwd_comment_log;
CREATE EXTERNAL TABLE dwd_comment_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`comment_id` int,
`userid` int,
`p_comment_id` int,
`content` string,
`addtime` string,
`other_id` int,
`praise_count` int,
`reply_count` int,
`server_time` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_comment_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_comment_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.comment_id') comment_id,
get_json_object(event_json,'$.kv.userid') userid,
get_json_object(event_json,'$.kv.p_comment_id') p_comment_id,
get_json_object(event_json,'$.kv.content') content,
get_json_object(event_json,'$.kv.addtime') addtime,
get_json_object(event_json,'$.kv.other_id') other_id,
get_json_object(event_json,'$.kv.praise_count') praise_count,
get_json_object(event_json,'$.kv.reply_count') reply_count,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='comment';
5.7.9 收藏表
drop table if exists dwd_favorites_log;
CREATE EXTERNAL TABLE dwd_favorites_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`id` int,
`course_id` int,
`userid` int,
`add_time` string,
`server_time` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_favorites_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_favorites_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.id') id,
get_json_object(event_json,'$.kv.course_id') course_id,
get_json_object(event_json,'$.kv.userid') userid,
get_json_object(event_json,'$.kv.add_time') add_time,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='favorites';
5.7.10 点赞表
drop table if exists dwd_praise_log;
CREATE EXTERNAL TABLE dwd_praise_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`id` string,
`userid` string,
`target_id` string,
`type` string,
`add_time` string,
`server_time` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_praise_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_praise_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.id') id,
get_json_object(event_json,'$.kv.userid') userid,
get_json_object(event_json,'$.kv.target_id') target_id,
get_json_object(event_json,'$.kv.type') type,
get_json_object(event_json,'$.kv.add_time') add_time,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='praise';
5.7.11 错误日志表
drop table if exists dwd_error_log;
CREATE EXTERNAL TABLE dwd_error_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`errorBrief` string,
`errorDetail` string,
`server_time` string)
PARTITIONED BY (dt string)
stored as parquet
location '/wavehouse/gmall/dwd/dwd_error_log/'
TBLPROPERTIES('parquet.compression'='lzo');
插入数据
insert overwrite table dwd_error_log
PARTITION (dt='2022-12-17')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.errorBrief') errorBrief,
get_json_object(event_json,'$.kv.errorDetail') errorDetail,
server_time
from dwd_base_event_log
where dt='2022-12-17' and event_name='error';
至此DWD层的数据已经全部导入
6 DWS层
6.1 需求1
求每日、每周、每月活跃设备明细。
6.1.1 每日设备活跃明细
建表
drop table if exists dws_uv_detail_day;
create external table dws_uv_detail_day
(
`mid_id` string COMMENT '设备唯一标识',
`user_id` string COMMENT '用户标识',
`version_code` string COMMENT '程序版本号',
`version_name` string COMMENT '程序版本名',
`lang` string COMMENT '系统语言',
`source` string COMMENT '渠道号',
`os` string COMMENT '安卓系统版本',
`area` string COMMENT '区域',
`model` string COMMENT '手机型号',
`brand` string COMMENT '手机品牌',
`sdk_version` string COMMENT 'sdkVersion',
`gmail` string COMMENT 'gmail',
`height_width` string COMMENT '屏幕宽高',
`app_time` string COMMENT '客户端日志产生时的时间',
`network` string COMMENT '网络模式',
`lng` string COMMENT '经度',
`lat` string COMMENT '纬度'
)
partitioned by(dt string)
stored as parquet
location '/wavehouse/gmall/dws/dws_uv_detail_day';
插入数据
insert overwrite TABLE gmall.dws_uv_detail_day PARTITION(dt='2022-12-17')
SELECT
mid_id,
concat_ws('|',collect_set(user_id)) user_id,
concat_ws('|',collect_set(version_code)) version_code,
concat_ws('|',collect_set(version_name)) version_name,
concat_ws('|',collect_set(lang)) lang,
concat_ws('|',collect_set(source)) source,
concat_ws('|',collect_set(user_id)) os,
concat_ws('|',collect_set(area)) area,
concat_ws('|',collect_set(model)) model,
concat_ws('|',collect_set(brand)) brand,
concat_ws('|',collect_set(sdk_version)) sdk_version,
concat_ws('|',collect_set(gmail)) gmail,
concat_ws('|',collect_set(height_width)) height_width,
concat_ws('|',collect_set(app_time)) app_time,
concat_ws('|',collect_set(network)) network,
concat_ws('|',collect_set(lng)) lng,
concat_ws('|',collect_set(lat)) lat
FROM
gmall.dwd_start_log
WHERE dt='2022-12-17'
GROUP BY mid_id;
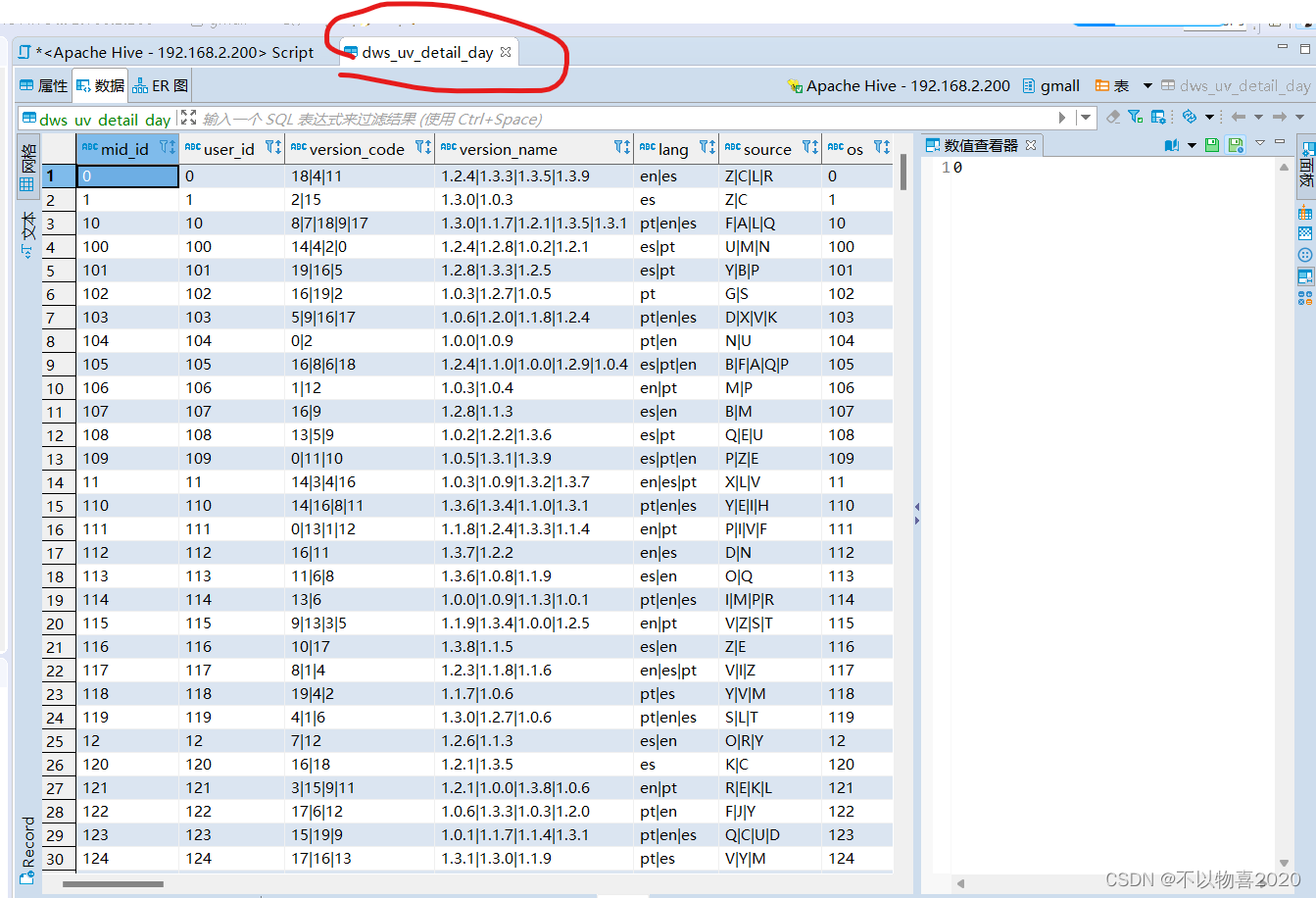
6.1.2 每周设备活跃明细
drop table if exists dws_uv_detail_wk;
create external table dws_uv_detail_wk(
`mid_id` string COMMENT '设备唯一标识',
`user_id` string COMMENT '用户标识',
`version_code` string COMMENT '程序版本号',
`version_name` string COMMENT '程序版本名',
`lang` string COMMENT '系统语言',
`source` string COMMENT '渠道号',
`os` string COMMENT '安卓系统版本',
`area` string COMMENT '区域',
`model` string COMMENT '手机型号',
`brand` string COMMENT '手机品牌',
`sdk_version` string COMMENT 'sdkVersion',
`gmail` string COMMENT 'gmail',
`height_width` string COMMENT '屏幕宽高',
`app_time` string COMMENT '客户端日志产生时的时间',
`network` string COMMENT '网络模式',
`lng` string COMMENT '经度',
`lat` string COMMENT '纬度',
`monday_date` string COMMENT '周一日期',
`sunday_date` string COMMENT '周日日期'
) COMMENT '活跃用户按周明细'
PARTITIONED BY (`wk_dt` string)
stored as parquet
location '/wavehouse/gmall/dws/dws_uv_detail_wk/';
插入数据
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite TABLE gmall.dws_uv_detail_wk PARTITION(wk_dt)
SELECT
mid_id,
concat_ws('|',collect_set(user_id)) user_id,
concat_ws('|',collect_set(version_code)) version_code,
concat_ws('|',collect_set(version_name)) version_name,
concat_ws('|',collect_set(lang)) lang,
concat_ws('|',collect_set(source)) source,
concat_ws('|',collect_set(user_id)) os,
concat_ws('|',collect_set(area)) area,
concat_ws('|',collect_set(model)) model,
concat_ws('|',collect_set(brand)) brand,
concat_ws('|',collect_set(sdk_version)) sdk_version,
concat_ws('|',collect_set(gmail)) gmail,
concat_ws('|',collect_set(height_width)) height_width,
concat_ws('|',collect_set(app_time)) app_time,
concat_ws('|',collect_set(network)) network,
concat_ws('|',collect_set(lng)) lng,
concat_ws('|',collect_set(lat)) lat,
date_add(next_day('2022-12-17','mo'),-7) monday_date,
date_add(next_day('2022-12-17','mo'),-1) sunday_date,
concat(date_add(next_day('2022-12-17','mo'),-7),'-',date_add(next_day('2022-12-17','mo'),-1)) wk_dt
FROM
gmall.dwd_start_log
WHERE dt BETWEEN date_add(next_day('2022-12-17','mo'),-7) AND date_add(next_day('2022-12-17','mo'),-1)
GROUP BY mid_id;
6.1.3 每月设备活跃明细
建表
drop table if exists dws_uv_detail_mn;
create external table dws_uv_detail_mn(
`mid_id` string COMMENT '设备唯一标识',
`user_id` string COMMENT '用户标识',
`version_code` string COMMENT '程序版本号',
`version_name` string COMMENT '程序版本名',
`lang` string COMMENT '系统语言',
`source` string COMMENT '渠道号',
`os` string COMMENT '安卓系统版本',
`area` string COMMENT '区域',
`model` string COMMENT '手机型号',
`brand` string COMMENT '手机品牌',
`sdk_version` string COMMENT 'sdkVersion',
`gmail` string COMMENT 'gmail',
`height_width` string COMMENT '屏幕宽高',
`app_time` string COMMENT '客户端日志产生时的时间',
`network` string COMMENT '网络模式',
`lng` string COMMENT '经度',
`lat` string COMMENT '纬度'
) COMMENT '活跃用户按月明细'
PARTITIONED BY (`mn` string)
stored as parquet
location '/wavehouse/gmall/dws/dws_uv_detail_mn/';
插入数据
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite TABLE gmall.dws_uv_detail_mn PARTITION(mn)
SELECT
mid_id,
concat_ws('|',collect_set(user_id)) user_id,
concat_ws('|',collect_set(version_code)) version_code,
concat_ws('|',collect_set(version_name)) version_name,
concat_ws('|',collect_set(lang)) lang,
concat_ws('|',collect_set(source)) source,
concat_ws('|',collect_set(user_id)) os,
concat_ws('|',collect_set(area)) area,
concat_ws('|',collect_set(model)) model,
concat_ws('|',collect_set(brand)) brand,
concat_ws('|',collect_set(sdk_version)) sdk_version,
concat_ws('|',collect_set(gmail)) gmail,
concat_ws('|',collect_set(height_width)) height_width,
concat_ws('|',collect_set(app_time)) app_time,
concat_ws('|',collect_set(network)) network,
concat_ws('|',collect_set(lng)) lng,
concat_ws('|',collect_set(lat)) lat,
date_format('2022-12-17','yyyy-MM') mn
FROM
gmall.dwd_start_log
WHERE date_format(dt,'yyyy-MM') = date_format('2022-12-17','yyyy-MM')
GROUP BY mid_id;
注意:周活/月活需要使用动态分区,因此需要开启非严格模式。动态分区会根据sql函数字段进行动态分区,由于日活是的日期是可以指定且固定的某一天,因此对于日活统计不需要动态分区。
set hive.exec.dynamic.partition.mode=nonstrict;
6.2 需求2
求每日新增用户数
首次联网使用应用的用户。如果一个用户首次打开某APP,那这个用户定义为新增用户;卸载再安装的设备,不会被算作一次新增。新增用户包括日新增用户、周新增用户、月新增用户。
6.2.1 建每日新增用户表
新增注册时间字段,用于判断是否为新用户
drop table if exists dws_new_mid_day;
create external table dws_new_mid_day
(
`mid_id` string COMMENT '设备唯一标识',
`user_id` string COMMENT '用户标识',
`version_code` string COMMENT '程序版本号',
`version_name` string COMMENT '程序版本名',
`lang` string COMMENT '系统语言',
`source` string COMMENT '渠道号',
`os` string COMMENT '安卓系统版本',
`area` string COMMENT '区域',
`model` string COMMENT '手机型号',
`brand` string COMMENT '手机品牌',
`sdk_version` string COMMENT 'sdkVersion',
`gmail` string COMMENT 'gmail',
`height_width` string COMMENT '屏幕宽高',
`app_time` string COMMENT '客户端日志产生时的时间',
`network` string COMMENT '网络模式',
`lng` string COMMENT '经度',
`lat` string COMMENT '纬度',
`create_date` string comment '创建时间'
) COMMENT '每日新增设备信息'
stored as parquet
location '/wavehouse/gmall/dws/dws_new_mid_day/';
导入数据
INSERT INTO TABLE dws_new_mid_day
SELECT
ud.mid_id,
ud.user_id,
ud.version_code,
ud.version_name,
ud.lang,
ud.source,
ud.os,
ud.area,
ud.model,
ud.brand,
ud.sdk_version,
ud.gmail,
ud.height_width,
ud.app_time,
ud.network,
ud.lng,
ud.lat,
'2022-12-05'
FROM
dws_uv_detail_day ud LEFT JOIN dws_new_mid_day nm ON ud.mid_id = nm.mid_id
where ud.dt='2022-12-05' and nm.mid_id is NULL;
6.3 需求3
统计每日用户留存用户和留存率。
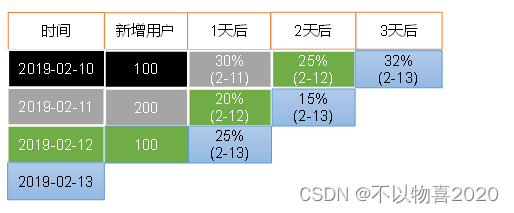
留存用户:某段时间内新增用户,经过一段时间后,又继续使用的用户。
留存率:留存用户占当时新增用户的比例
如:2月10日新增用户100人,2月11日这100人中有30人继续登录,留存率则为30%;2月12日有25人登录,则留存率25%
建表
drop table if exists dws_user_retention_day;
create external table dws_user_retention_day
(
`mid_id` string COMMENT '设备唯一标识',
`user_id` string COMMENT '用户标识',
`version_code` string COMMENT '程序版本号',
`version_name` string COMMENT '程序版本名',
`lang` string COMMENT '系统语言',
`source` string COMMENT '渠道号',
`os` string COMMENT '安卓系统版本',
`area` string COMMENT '区域',
`model` string COMMENT '手机型号',
`brand` string COMMENT '手机品牌',
`sdk_version` string COMMENT 'sdkVersion',
`gmail` string COMMENT 'gmail',
`height_width` string COMMENT '屏幕宽高',
`app_time` string COMMENT '客户端日志产生时的时间',
`network` string COMMENT '网络模式',
`lng` string COMMENT '经度',
`lat` string COMMENT '纬度',
`create_date` string comment '设备新增时间',
`retention_day` int comment '截止当前日期留存天数'
) COMMENT '每日用户留存情况'
PARTITIONED BY (`dt` string)
stored as parquet
location '/wavehouse/gmall/dws/dws_user_retention_day/';
插入数据
INSERT overwrite TABLE dws_user_retention_day PARTITION(dt='2022-12-20')
SELECT
t2.mid_id,
t2.user_id,
t2.version_code,
t2.version_name,
t2.lang,
t2.source,
t2.os,
t2.area,
t2.model,
t2.brand,
t2.sdk_version,
t2.gmail,
t2.height_width,
t2.app_time,
t2.network,
t2.lng,
t2.lat,
t2.create_date,
1 retention_day
FROM
dws_uv_detail_day t1 JOIN dws_new_mid_day t2 on t1.mid_id=t2.mid_id
WHERE t1.dt='2022-12-20' AND t2.create_date=date_add('2022-12-20',-1);
6.4 需求4
求沉默用户,沉默用户:指的是只在安装当天启动过,且启动时间是在一周前。
这里可以使用dws层的dws_uv_detail_day表进行查询沉默用户操作
6.5 本周回流用户数
本周回流=本周活跃-本周新增-上周活跃。使用日活明细表dws_uv_detail_day作为DWS层数据。
###6.6 最近连续三周活跃用户数
最近3周连续活跃的用户:通常是周一对前3周的数据做统计,该数据一周计算一次。
6.7 最近7天内连续3天活跃用户数
使用日活明细表dws_uv_detail_day作为DWS层数据
6.8 新收藏用户数
考虑到后面的多个需求会同时用到多张表中的数据, 如果每次都join操作, 则影响查询的效率. 可以先提前做一张宽表, 提高其他查询的执行效率。每个用户对每个商品的点击次数, 点赞次数, 收藏次数
建表
drop table if exists dws_user_action_wide_log;
CREATE EXTERNAL TABLE dws_user_action_wide_log(
`mid_id` string COMMENT '设备id',
`goodsid` string COMMENT '商品id',
`display_count` string COMMENT '点击次数',
`praise_count` string COMMENT '点赞次数',
`favorite_count` string COMMENT '收藏次数')
PARTITIONED BY (`dt` string)
stored as parquet
location '/wavehouse/gmall/dws/dws_user_action_wide_log/'
TBLPROPERTIES('parquet.compression'='lzo');
导入数据
INSERT overwrite TABLE dws_user_action_wide_log PARTITION(dt='2022-12-20')
SELECT
mid_id,
goodsid,
sum(display_count) display_count,
sum(praise_count) praise_count,
sum(favorite_count) favorite_count
FROM
(
SELECT
mid_id,
goodsid,
COUNT(*) display_count,
0 praise_count,
0 favorite_count
FROM
dwd_display_log
WHERE dt<='2022-12-20'
GROUP BY mid_id,goodsid
UNION ALL
SELECT
mid_id,
target_id as goodsid,
0 display_count,
COUNT(mid_id) praise_count,
0 favorite_count
FROM
dwd_praise_log
WHERE dt<='2022-12-20'
GROUP BY mid_id,target_id
UNION ALL
SELECT
mid_id,
course_id as goodsid,
0 display_count,
0 praise_count,
COUNT(mid_id) favorite_count
FROM
dwd_favorites_log
WHERE dt<='2022-12-20'
GROUP BY mid_id,course_id
) tmp
GROUP BY mid_id,goodsid
6.9 需求9 各个商品点击次数top3的用户
使用日志数据用户行为宽表作为DWS层表
7 ADS 应用数据层
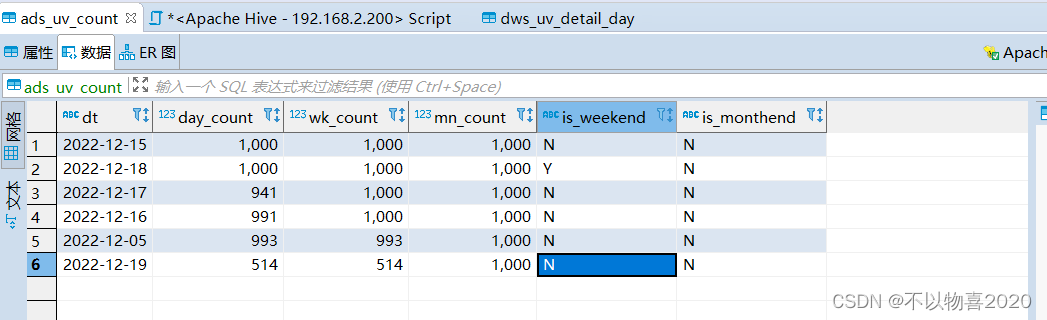
7.1 需求1
对应6.1中DWS层需求1,在ADS数据应用层创建表
drop table if exists ads_uv_count;
create external table ads_uv_count(
`dt` string COMMENT '统计日期',
`day_count` bigint COMMENT '当日用户数量',
`wk_count` bigint COMMENT '当周用户数量',
`mn_count` bigint COMMENT '当月用户数量',
`is_weekend` string COMMENT 'Y,N是否是周末,用于得到本周最终结果',
`is_monthend` string COMMENT 'Y,N是否是月末,用于得到本月最终结果'
) COMMENT '活跃设备数'
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_uv_count/';
插入数据
INSERT into TABLE ads_uv_count
SELECT
'2022-12-18' dt,
day_count,
wk_count,
mn_count,
if(date_add(next_day('2022-12-18','mo'),-1)='2022-12-18','Y','N') is_weekend,
if(last_day('2022-12-18')='2022-12-18','Y','N') is_monthend
FROM
(SELECT count(mid_id) day_count FROM dws_uv_detail_day WHERE dt='2022-12-18') t1
JOIN
(SELECT count(mid_id) wk_count FROM dws_uv_detail_wk WHERE wk_dt=concat(date_add(next_day('2022-12-18','mo'),-7),'-',date_add(next_day('2022-12-18','mo'),-1))) t2
JOIN
(SELECT COUNT(mid_id) mn_count FROM dws_uv_detail_mn WHERE mn=date_format('2022-12-18','yyyy-MM')) t3;
7.2 需求2
根据dws层dws_new_mid_day表求聚合操作可以求出每天的新增用户,创建ads层表
drop table if exists ads_new_mid_count;
create external table ads_new_mid_count
(
`create_date` string comment '创建时间' ,
`new_mid_count` BIGINT comment '新增设备数量'
) COMMENT '每日新增设备信息数量'
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_new_mid_count/';
导入数据
INSERT into TABLE ads_new_mid_count
SELECT
create_date,
count(*)
FROM
dws_new_mid_day
WHERE create_date='2022-12-05'
GROUP BY create_date;

7.3 需求3
求留存用户和留存率,根据dws层表数据进行计算。
建表
drop table if exists ads_user_retention_day_count;
create external table ads_user_retention_day_count
(
`create_date` string comment '设备新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数量'
) COMMENT '每日用户留存情况'
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_user_retention_day_count/';
导入数据
INSERT overwrite TABLE ads_user_retention_day_count
SELECT
create_date,
retention_day,
count(*) retention_count
FROM
dws_user_retention_day
WHERE dt='2022-12-20'
GROUP BY create_date,retention_day;
留存率计算
建表
drop table if exists ads_user_retention_day_rate;
create external table ads_user_retention_day_rate
(
`stat_date` string comment '统计日期',
`create_date` string comment '设备新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数量',
`new_mid_count` bigint comment '当日设备新增数量',
`retention_ratio` decimal(10,2) comment '留存率'
) COMMENT '每日用户留存情况'
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_user_retention_day_rate/';
插入数据
INSERT INTO TABLE ads_user_retention_day_rate
SELECT
'2022-12-20' stat_date,
nm.create_date,
ur.retention_day,
ur.retention_count,
nm.new_mid_count,
CAST(ur.retention_count / nm.new_mid_count as decimal(10,2)) retention_ratio
FROM
ads_new_mid_count nm JOIN ads_user_retention_day_count ur on nm.create_date=ur.create_date
-- 为了求出留存率大于1的情况,需要进去筛选和过率
where date_add(ur.create_date,ur.retention_day)='2022-12-20';
7.4 需求4
统计沉默用户,创建ads数据应用层表。
drop table if exists ads_silent_count;
create external table ads_silent_count(
`dt` string COMMENT '统计日期',
`silent_count` bigint COMMENT '沉默设备数'
)
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_silent_count';
插入数据
INSERT into TABLE ads_silent_count
SELECT
'2022-12-19' dt,
COUNT(*) silent_count
FROM
(SELECT
mid_id
FROM
dws_uv_detail_day
where dt <= '2022-12-19'
GROUP BY mid_id
HAVING COUNT(mid_id)=1 AND MIN(dt) < date_sub('2022-12-19',7)) tmp;
7.5 需求5
建表
drop table if exists ads_back_count;
create external table ads_back_count(
`dt` string COMMENT '统计日期',
`wk_dt` string COMMENT '统计日期所在周',
`wastage_count` bigint COMMENT '回流设备数'
)
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_back_count';
导入数据
INSERT INTO TABLE ads_back_count
SELECT
'2022-12-20' dt,
concat(date_add(next_day('2022-12-20','mo'),-7),'-',date_add(next_day('2022-12-20','mo'),-1)) wk_dt,
COUNT(*) wastage_count
FROM
(
SELECT t1.mid_id
FROM
( SELECT mid_id
FROM dws_uv_detail_wk
WHERE wk_dt=concat(date_add(next_day('2022-12-20','mo'),-7),'-',date_add(next_day('2022-12-20','mo'),-1))
) t1
LEFT JOIN
( SELECT mid_id
FROM dws_new_mid_day
WHERE create_date <=date_add('2022-12-20',-1) AND create_date >=date_add('2022-12-20',-7)
) t2
ON t1.mid_id=t2.mid_id
LEFT JOIN
( SELECT mid_id
FROM dws_uv_detail_wk
WHERE wk_dt=concat(date_add(next_day('2022-12-20','mo'),-7*2),'-',date_add(next_day('2022-12-20','mo'),-1-7))
) t3
ON t1.mid_id=t3.mid_id
WHERE t2.mid_id is null and t3.mid_id is null
) t4;
7.6 需求6
drop table if exists ads_continuity_wk_count;
create external table ads_continuity_wk_count(
`dt` string COMMENT '统计日期,一般用结束周周日日期,如果每天计算一次,可用当天日期',
`wk_dt` string COMMENT '持续时间',
`continuity_count` bigint
)
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_continuity_wk_count';
插入数据逻辑
INSERT INTO TABLE ads_continuity_wk_count
SELECT
'2022-12-20' dt,
concat(date_sub(next_day('2022-12-20','MO'),7*3),'-',date_sub(next_day('2022-12-20','MO'),1)) wk_dt,
count(*) continuity_count
FROM
dws_uv_detail_wk
WHERE wk_dt BETWEEN concat(date_sub(next_day('2022-12-20','MO'),7*3),'-',date_sub(next_day('2022-12-20','MO'),7*2+1)) AND
concat(date_sub(next_day('2022-12-20','MO'),7),'-',date_sub(next_day('2022-12-20','MO'),1))
GROUP BY mid_id
HAVING COUNT(mid_id)>=3;
7.7 需求7
建表
drop table if exists ads_continuity_uv_count;
create external table ads_continuity_uv_count(
`dt` string COMMENT '统计日期',
`wk_dt` string COMMENT '最近7天日期',
`continuity_count` bigint
) COMMENT '连续活跃设备数'
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_continuity_uv_count';
插入数据
SELECT
'2022-12-20' dt,
concat(date_sub(next_day('2022-12-20','MO'),7),'-',date_sub(next_day('2022-12-20','MO'),1)) wk_dt,
count(DISTINCT mid_id) continuity_count
FROM
( SELECT
mid_id
FROM
( SELECT
mid_id,
dt,
ROW_NUMBER() OVER(PARTITION BY mid_id ORDER BY dt asc) rn,
date_sub(dt,ROW_NUMBER() OVER(PARTITION BY mid_id ORDER BY dt asc)) diff_dt
FROM
dws_uv_detail_day
WHERE dt BETWEEN date_sub(next_day('2022-12-20','MO'),7) AND date_sub(next_day('2022-12-20','MO'),1)
) t1
GROUP BY mid_id,diff_dt
HAVING COUNT(mid_id)>=3
) t2
7.8 需求8
ads层建表
drop table if exists ads_new_favorites_mid_day;
create external table ads_new_favorites_mid_day(
`dt` string COMMENT '日期',
`favorites_users` bigint COMMENT '新收藏用户数'
)
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_new_favorites_mid_day';
插入数据
INSERT INTO TABLE ads_new_favorites_mid_day
SELECT
'2022-12-20' dt,
COUNT(*)
FROM
( SELECT
mid_id
FROM
dws_user_action_wide_log
WHERE favorite_count > 0
GROUP BY mid_id
HAVING MIN(dt)='2022-12-20'
) t1
7.9 需求9
建表
drop table if exists ads_goods_count;
create external table ads_goods_count(
`dt` string COMMENT '统计日期',
`goodsid` string COMMENT '商品',
`user_id` string COMMENT '用户',
`goodsid_user_count` bigint COMMENT '商品用户点击次数'
)
row format delimited fields terminated by '\t'
location '/wavehouse/gmall/ads/ads_goods_count';
导入数据
SELECT
'2022-12-20' dt,
goodsid,
mid_id,
total_count
FROM
(
SELECT
mid_id,
goodsid,
total_count,
RANK() OVER(PARTITION BY goodsid ORDER BY total_count DESC) rn
FROM
(
SELECT
mid_id,
goodsid,
sum(display_count) total_count
FROM
dws_user_action_wide_log
WHERE dt<='2022-12-20' AND display_count > 0
GROUP BY mid_id,goodsid
) t1) t2
WHERE rn<=3;
接下来是本地业务数仓的详细搭建流程,详见《本地数仓项目(二)——搭建系统业务数仓详细流程》