1. 问题介绍
(1)问题描述本文主要研究的问题是人脸识别系统,人脸识别技术是要用计算机分析人脸图像,从中提取有效的识别信息并通过分类器自动鉴别的一种技术。人脸识别技术是基于生理特征进行识别,作为最主要的生物特征身份认证技术之一。人脸识别更为直接、友好而自然。
(2)数学模型:PCA全称Principal Component Analysis,即主成分分析,是一种常用的数据降维方法。它可以通过线性变换将原始数据变换为一组各维度线性无关的表示,以此来提取数据的主要线性分量。
\begin{equation}
Z=w^{T}x
\end{equation}
其中,z为低维矩阵,x为高维矩阵,w为两者之间的映射关系。假如我们有二维数据(原始数据有两个特征轴——特征1和特征2)如下图所示,样本点分布为斜45°的蓝色椭圆区域。PCA算法认为斜45°为主要线性分量,与之正交的虚线是次要线性分量(应当舍去以达到降维的目的)。

在统计学上,协方差用来刻画两个随机变量之间的相关性,反映的是变量之间的二阶统计特性。考虑两个随机变量Xi和Xj和它们的协方差定义为:
要达到PCA降维目的,等价于将协方差矩阵对角化:即除对角线外的其他元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
优化目标变成了寻找一个矩阵P,满足是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
(3)原理方法:
本文利用机器学习领域经典的主成分分析法(PCA法),在所建图像数据库的基础上完成人脸识别功能。本文按照完整的流程来实现基于PCA的人脸识别:首先是将准备好的图像库导入(如使用的数据库中的光照不均匀且特征点不统一时要进行归一化操作);接下来是人脸图像预处理;(每列减去均值)接着使用PCA提取人脸特性,计算协方差矩阵的特征值和特征向量;选择主成分,对训练集进行降维;最后使用最近邻法分类器来进行人脸判别。
(4)距离函数的选取和分类判别 将人脸图像投影到特征子空间,得到相应的人脸特征向量之后,余下的任务就是如何判别测试图像所属的类别,即归类问题或判别决策问题。首先,需要对图像之间的相似性进行度量。常见的度量方式有:
1)欧氏距离欧式( (Euclidean)距离也称欧几里德距离,向量X与Y之间的欧氏距离定义为:
2)Covariance 距离(余弦夹角距离)
向量X与Y之间的角度相似性定义为它们之间夹角的余弦,即:
马氏距离引入特征值,给特征值小的特征向量更大的权值,使每个基坐标的重要性平等,从而排除了不同特征之间相关性的影响。
计算出图像之间的相似度以后,我们需要对所得到的信息进行分类判别决策,常用的分类方法有最近邻分类器、K-近邻分类器、贝叶斯分类器等。在本实验的PCA人脸识别方法中,使用的是基于欧氏距离的最近邻分类器。
2.实验数据
(1)ORL人脸数据库由英国剑桥Olivetti实验室从1992年4月到1994年4月期间拍摄的一系列人脸图像组成共包含有40个不同年龄、不同性别和不同种族的对象。ORL数据库共有400幅人脸图像(40人, 每人10幅, 大小为112像素x92像素),这个数据库比较规范,大多数图像的光照方向和强度都相差较小,图像背景均为黑色,表情和人脸姿态略微有变化,但仍然是较为理想人脸数据库。
(2)FERET人脸库,该数据库是最大的人脸数据库,由英国国防部建立。它里面的人脸图像有着肤色和人脸角度的变化,而且测试者的背景图像都是统一的,因此该数据库具有较高权威性,但弊端是获取图像信息困难。
(3)Essex人脸库,英国埃塞克斯大学建立了该人脸数据库,并为研究者提供免费的下载,但是不允许发售和打印。该数据库中的背景、人脸角度、人脸比例大小都有所变化,因此识别较为困难。
本实验的图像数据采用著名的ORL人脸库,该库也是目前使用最广泛的标准人脸数据库。本库中每张图片大小为11.1k,像素为112×92,格式为.bmp格式。该数据库共包含40人,每人10张图片,实验中用每个人的前五张(共计200张)用作训练集,后五张用做测试集。
数据库来源为互联网。
3.实验过程
3.1实验设定:
(1)实验环境:matlab2015b;
(2)参数设定:在进行特征值选择时,选择累计大于85%的前K个特征值;
(3)数据预处理:图像去中心化处理;
(4)训练集:数据集一共40人,每人10幅图像,采用每人的前5幅图像作为训练集,共计200幅图像;
(5)测试集:数据集一共40人,每人10幅图像,采用每人的后5幅图像作为测试集,共计200幅图像;
(6)准确率:88.5%
3.2实验步骤:
完整的PCA人脸识别算法包括以下两个过程:
(1)训练过程,步骤如下:1)获取人脸库中的人脸图像,并进行相关的预处理,采用每个人的前5张图片建立训练集;2)对训练集中的图像进行主成份分析,(选择累计大于85%的前K个特征向量)得到特征脸,形成特征子空间;3)把训练集中的图像投影到特征子空间,保存相应的特征向量。
(2)准确率判定过程,步骤如下:
1)获取人脸库中的人脸图像,采用每个人的后5张图片建立测试集
;2)对训练集中的图像进行主成份分析,(选择累计大于85%的前K个特征向量)得到特征脸,形成特征子空间;
3)把训练集中的图像投影到特征子空间,保存相应的特征向量;
4)利用欧式距离公式,一一判断能否正确的在训练集中找到对应的映射的测试集图像,最终得到识别准确率。
(3)识别过程,步骤如下:1)对任意输入的测试图像进行预处理工作;2)将测试图像投影到人脸特征子空间中,得到相应的人脸特征向量;3)根据欧式距离函数,进行分类判别,进而找到识别出的人脸图像。

3.3实验分析:
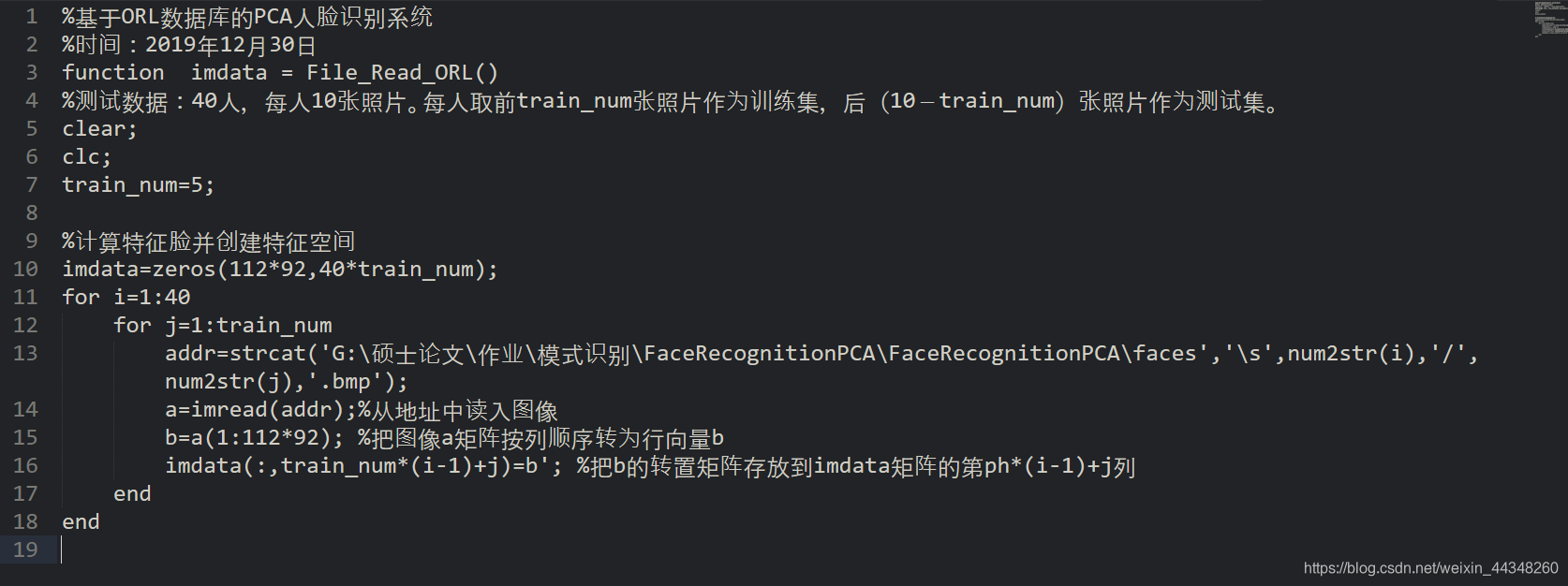
第一步,运行程序File_Read_ORL.m,即输入:imdata = File_Read_ORL();%此子程序完成训练集图像导入,生成一个10304×200的训练集矩阵imdata;
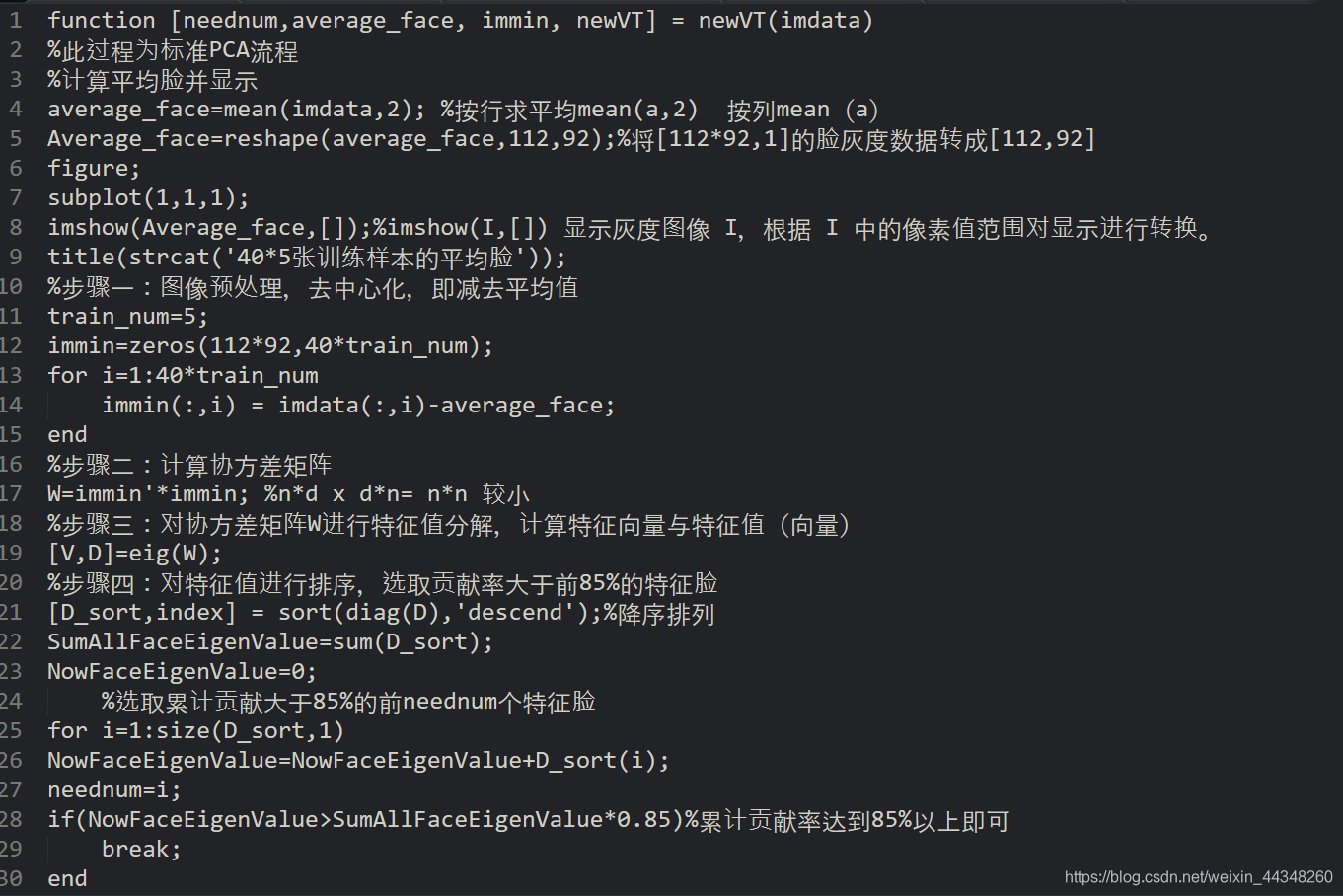
第二步,运行程序newVT.m,即输入:[neednum,average_face, immin, newVT] = newVT(imdata);%此子程序完成标准的PCA降维过程,输入为上一子程序得到的矩阵imdate,输出得到neednum(累计贡献率为85%以上的特征脸个数,为47),average_face(200张训练样本的平均脸,为10304×1), immin(训练样本去中心化后的样本矩阵),newVT(降维后的特征向量矩阵,为47×10304),同时能够得到平均脸图像如下图所示:

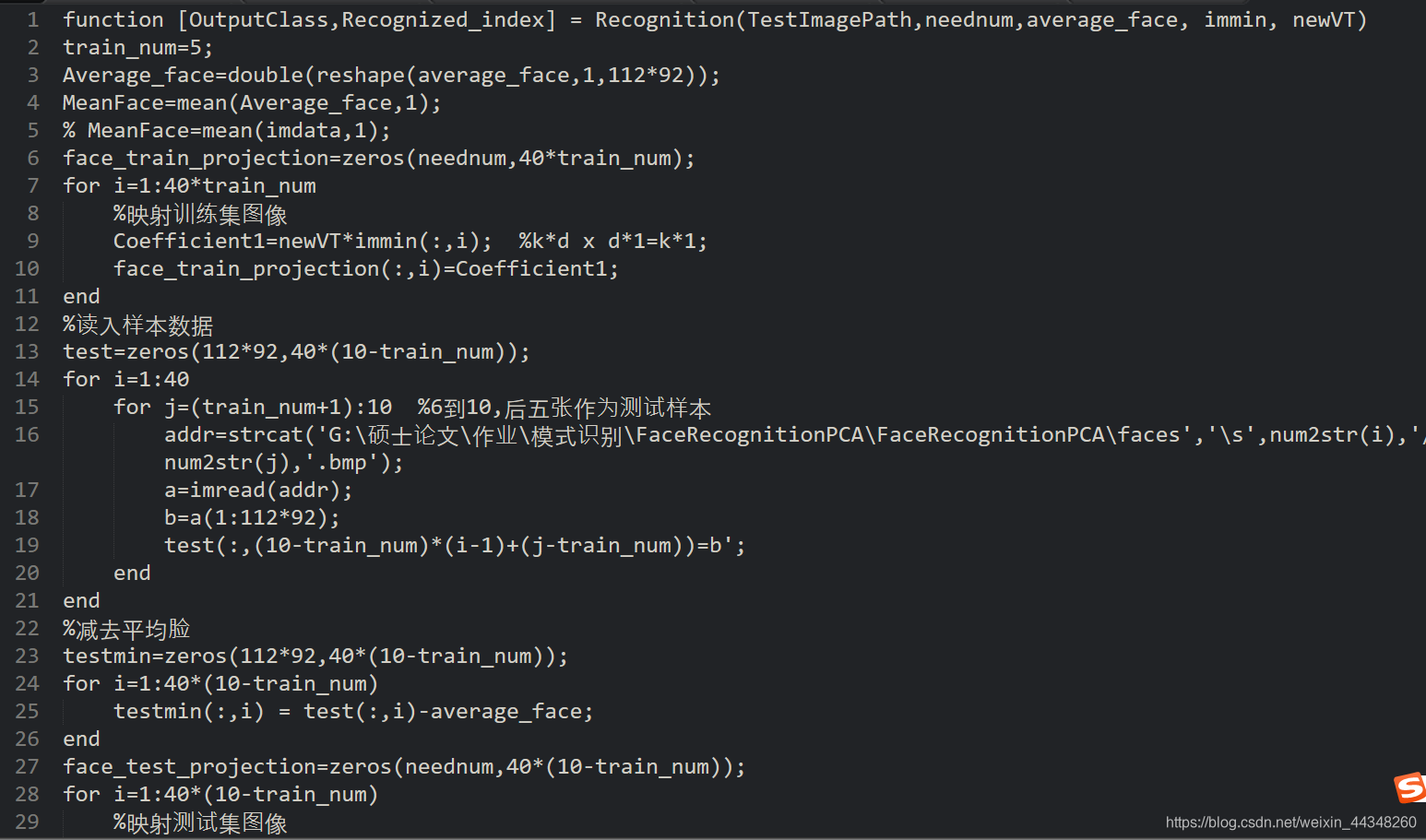
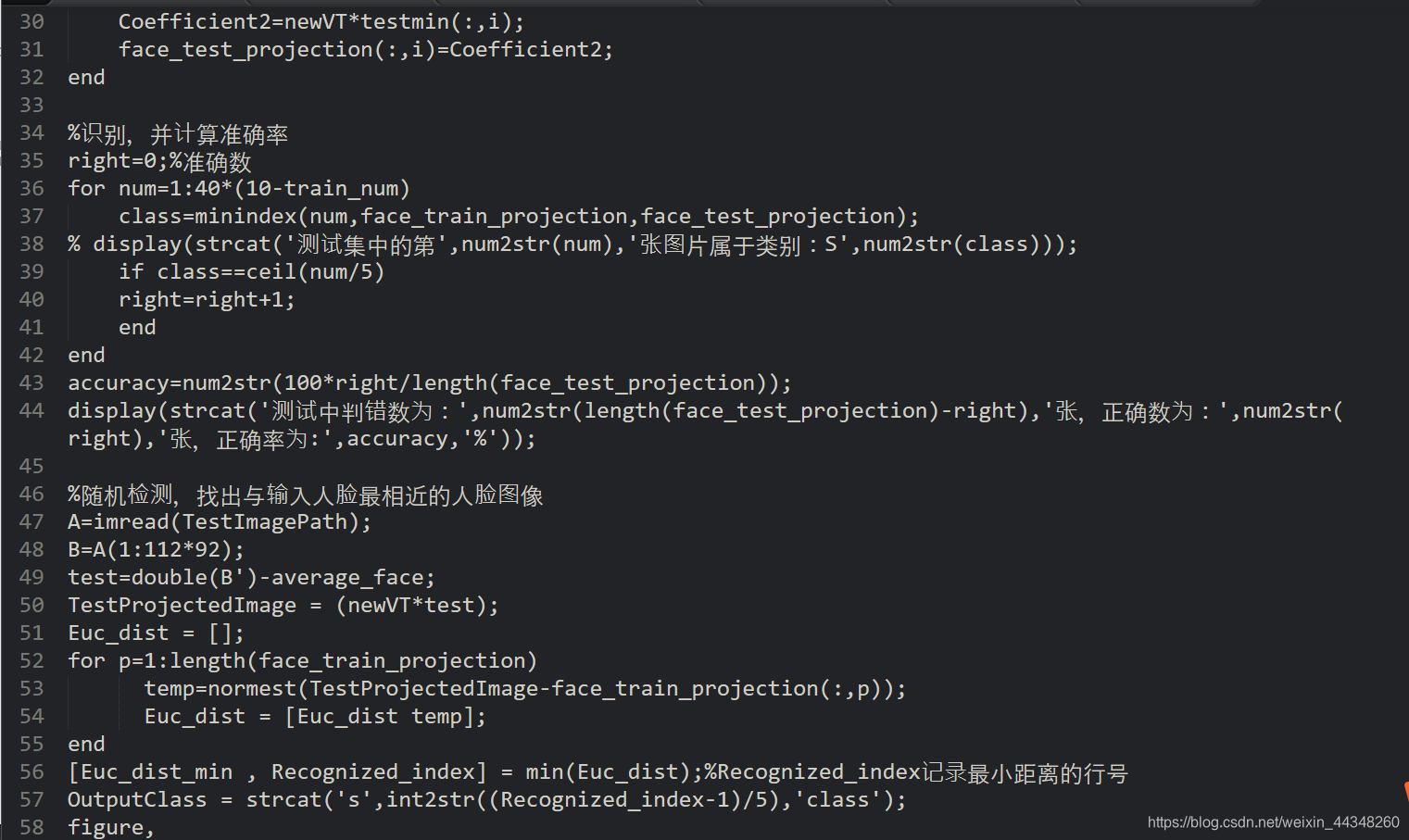
第三步,运行程序OutputClass = Recognition(‘G:\作业\FaceRecognitionPCA\faces\s29\6.bmp’,neednum,average_face, immin, newVT),%此过程为完成训练集和测试集的图像映射,并计算准确率;同时也根据任意输入的一张测试图像完成在查找相似人脸的工作。其中多次调用了欧式距离的计算,因此将此计算过程单独封装为minindex函数以方便调用。此程序的输入为测试图像路径、以及neednum、immin、average_face、newVT,输出为显示输入人脸图像和查找结果以及准确率。示例:当如输入路径为G:\作业\FaceRecognitionPCA\faces\s29\6.bmp时,即显示当前路径下该类中查找到的最相似人脸,同时输出:测试中判错数为:23张,正确数为:177张,正确率为:88.5%。

4.结论
本人脸识别系统在标准ORL人脸数据库的基础上进行实验训练得到模型,通过随机输入想要测试的图片,系统经过会自动读取后进行识别,并且显示出查找到的最相似人脸。经过测试发现,本系统能够很好地实现人脸识别,识别的准确率高达88.5%。
本系统的PDF报告和详细代码实现见本人的其他博客
//download.csdn.net/download/weixin_44348260/12115911,下附几张matlab代码实现图片