本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在学习摘录和笔记专栏:
学习摘录和笔记(8)---《迈向第三代人工智能》
迈向第三代人工智能
原文/论文出处:
题目:《迈向第三代人工智能》
作者:张钹, 朱军, 苏航
时间:2020–09–22
来源:中国科学 : 信息科学
文章摘要:
人工智能 (artifificial intelligence,AI) 自1956 年诞生以来,在 60 多年的发展历史中,一直存在 两个相互竞争的范式, 即符号主义与连接主义 (或称亚符号主义)。二者虽然同时起步, 但符号主义到 20 世纪 80 年代之前一直主导着 AI 的发展,而连接主义从 20 世纪 90 年代才逐步发展起来,到21世纪初进入高潮,大有替代符号主义之势。
这两种范式只是从不同的侧面模拟人类的心智(或大脑),具有各自的片面性,依靠单个范式不可能触及人类真正的智能. 需要建立新的可解释和鲁棒的 AI 理论与方法,发展安全、可信、可靠和可扩展的 AI 技术。
为实现这个目标,需要将这两种范式结合起来,这是发展 AI 的必经之路。 本文将阐述这一思想,为叙述方便,称符号主义为第一代 AI,称连接主义为第二代 AI,将要发展的AI称为第三代 AI。
1 第一代人工智能
符号AI与人类理性智能一样具有可解释性和容易理解.。符号 AI 也存在明显的局限性, 目前 已有的方法只能解决完全信息和结构化环境下的确定性问题。
其中最具代表性的成果是 IBM “深蓝” 国际象棋程序。
2 第二代人工智能
对于感官信息:
符号主义主张:以某种编码的方式表示在 (记忆) 神经网络中,符号 AI 属于这一学派。
连接主义主张: 感官的刺激并不存储在记忆中,而是在神经网络中建立起 “刺激 – 响应” 的连接 (通道), 通 过这个 “连接” 保证智能行为的产生。
1958 年罗森布拉特 (Rosenblatt) 按照连接主义的思路, 建立一个人工神经网络 (artifificial neural network, ANN) 的雏形 —— 感知机 (perceptron)。
如果拥有一定质量的大数据, 由于深度神经网络的通用性 (universality),它可以逼近任意的函数, 因此利用深度学习找到数据背后的函数具有理论的保证。
2016年3月谷歌围棋程序 AlphaGo 打败世界冠军李世石,是第二代 AI 巅峰之作,因为在 2015 年之前计算机围棋程序最高只达到业余五段。
3 第三代人工智能
第一代知识驱动的 AI,利用知识、算法和算力3个要素构造 AI,第二代数据驱动的 AI,用数据、算法与算力 3 个要素构造 AI。
第三代 AI其发展的思路:
把第一代的知识驱动和第二代的数据驱动结合起来,通过同时利用知识、数据、算法和算力等4个要素,构造更强大的AI.。目前存在双空间模型与单一空间模型两个方案。
3.1 双空间模型
双空间模型如图 2 所示,它是一种类脑模型,符号空间模拟大脑的认知行为,亚符号 (向量) 空间模拟大脑的感知行为。
这两层处理在大脑中是无缝融合的, 如果能在计算机上实现这种融合,AI 就有可能达到与人类相似的智能,从根本上解决目前 AI 存在的不可解释和鲁棒性差的问题。
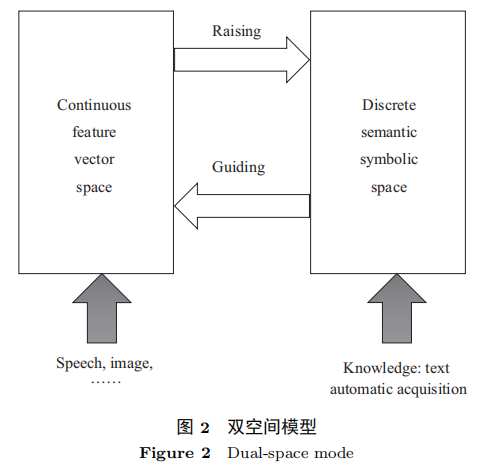
为了实现这种目标,需要解决以下 3 个问题:
(1)知识与推理:
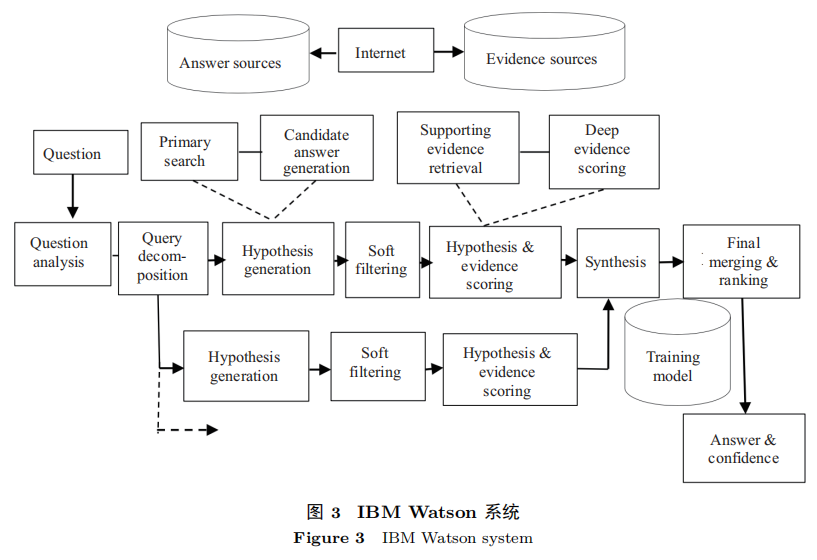
Watson 关于知识表示和推理方法的以下经验值得借鉴:
1) 从大量非结构化的文本自动生成结构化知识表示的方法,
2) 基于知识质量的评分表示知识不确定性的方法,
3) 基于多种推理的融合实现不确定性推理的方法。
(2)感知:
目前的研究只能提取部分的语义信息, 还不能做到提取不同层面上的语义信息, 如 整体”、“部件”和“子部件”等, 达到符号化的水平,因此仍有许多工作有待研究。
(3) 强化学习 :
通过感官信息有可能学到一些基本知识 (概念),不过仅仅依靠感官信息还不够,比如 “常识概念”,如 “吃饭” “睡觉” 等仅依靠感官难以获取,只有通过与环境的交互,即亲身经验之后才能获得,这是人类最基本的学习行为,也是通往真正 AI 的重要道路。
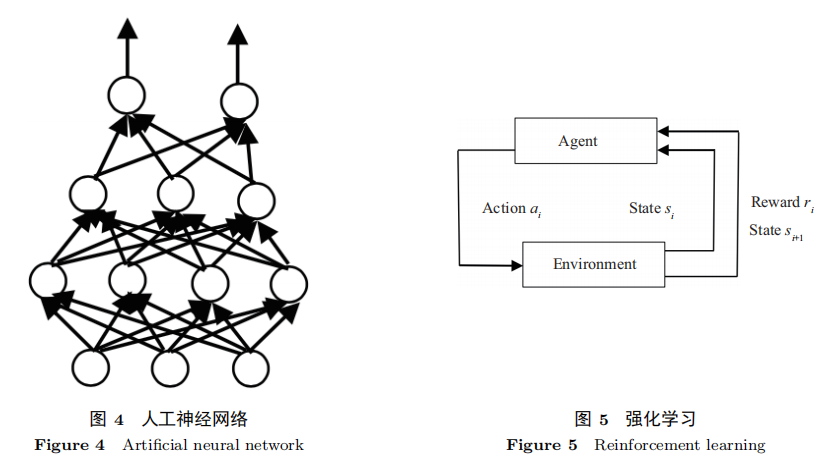
强化学习 (reinforcement learning) 就是用来模拟人类的这种学习行为,它通过 “交互 – 试错” 机制,与环境不断进行交互进而学习到有效的策略,很大程度上反映了人脑做出决定的反馈系统运行机理。
-------语义空间即语言意义的世界。一般来说,信息是意义和符号的统一体,内在的意义只有通过一定的外在形式(动作、表情、文字、音声、图画、影像等符号)才能表达出来。因此,每一种符号体系在广义上都是传达意义的语言,它们所表达的意义构成了特定的语义空间。
强化学习的核心目标就是选择最优的策略,使得预期的累计奖励最大。
但是在不确定性、不完全信息、数据或者知识匮乏的场景下, 目前强化学习算法的性能往往会出现大幅度的下降, 这也是目前强化学习所面临的重要挑战。
存在的典型问题:
(1) 部分观测马氏决策过程中强化学习
(2) 领域知识在强化学习中的融合机制
(3) 强化学习和博弈论的结合
3.2 单一空间模型
单一空间模型是以深度学习为基础,将所有的处理都放在亚符号 (向量) 空间,这显然是为了利用计算机的计算能力,提高处理速度。
关键问题:
1.符号表示的向量化
2.深度学习方法的改进
3.贝叶斯深度学习
4.单一空间中的计算
总结
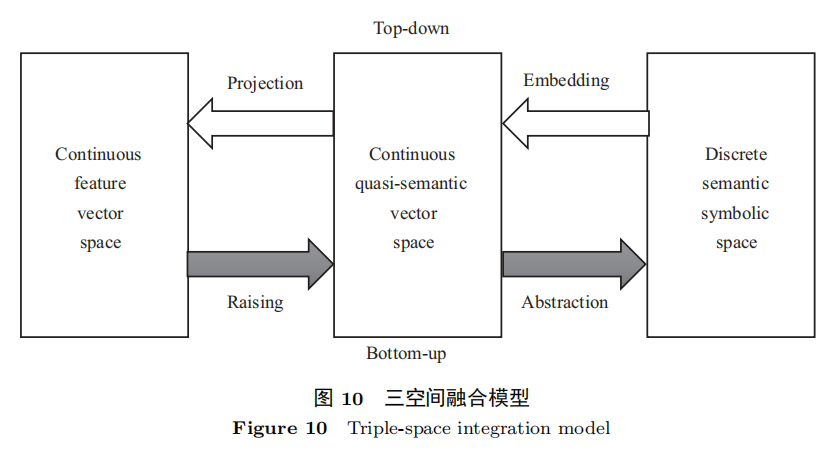
为了实现第三代 AI 的目标,最好的策略是同时沿着这两条路线前进,即三空间的融合,如图10所示。这种策略的好处是,既最大限度地借鉴大脑的工作机制,又充分利用计算机的算力,二者的结合,有望建造更加强大的 AI。
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。