本文转载改编自:《什么是第三代通用计算?》
https://aijishu.com/a/1060000000443123
文章目录
编者按
大家一直有个误解,觉得通用和专用,是对等的两个选择。例如,牧本波动(Makimoto’s Wave),是一个与摩尔定律类似的电子行业发展规律,它认为集成电路有规律的在“通用”和“专用”之间变化,循环周期大约为10年。
我们的观点则是:相比专用,通用是更高级的能力。集成电路等各种事物发展规律的常态是通用,“通用到专用”只是达到通用状态后的一些新的探索,是临时状态,最终还是要回归到通用。专用是事物表面的、临时的、局部的特征,而通用则是事物本质的、长期的、全面的特征。
对大芯片来说,通用是成功的必由之路。CPU是通用芯片,成就了Intel的成功;GPU是通用芯片,成就了NVIDIA的成功。目前,还没有看到做专用芯片非常成功的案例。长期地看,专用是临时的,专用的芯片也是临时的,最终的结果只能是走向消亡。
今天这篇文章,我们聊聊通用和通用计算的话题。
一、相比专用,通用是更高级别的能力
1、牧本波动
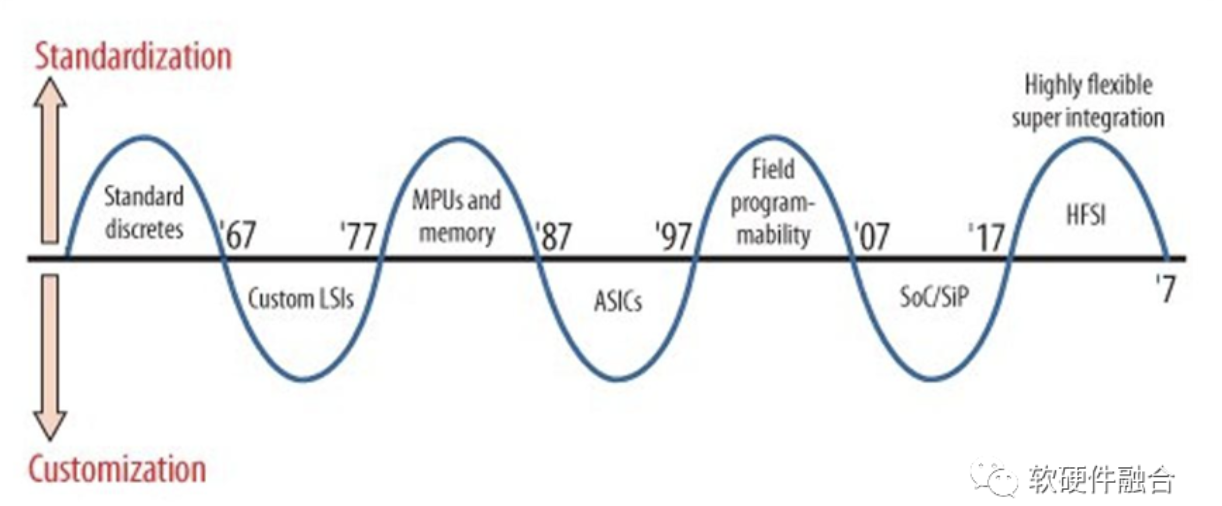
1987年,原日立公司总工程师牧本次生(Tsugio Makimoto)提出,集成电路发展过程中,芯片产品总是在“标准化”与“定制化”之间交替摆动,大概每十年波动一次。
牧本波动(Makimoto’s Wave,也称为牧本定律)背后是性能、功耗和开发效率之间的一个平衡。
也因为同样的理解,芯片行业的很多人认为,“通用”和“专用”是对等的,是一个天平的两边。
设计研发的产品,偏向通用或偏向专用,是基于客户场景需求,对产品实现的权衡。
2、专用是临时的,通用是永恒的
如果我们深入的分析牧本波动的规律,会发现:通用时代的产品都逐渐沉淀下来了,并且仍在发展壮大;
而专用时代的产品,要么消失在历史长河里了,要么是也在变得越来越通用。
以GPU为例,最开始的GPU(Graphics Processing Unit)其实是专用的图形加速芯片。
在上世纪90年代,有太多的公司做专用的GPU加速芯片 或者 其他各种专用类型的加速芯片。
后来NVIDIA发现GPU中有非常多的并行计算部分,于是把GPU改造成由很多高效能的小CPU核(CUDA核)组成的通用GPU(GPGPU),最终才获得了成功。
而其他仍然坚持做专用加速芯片的公司,都已经销声匿迹。
所以呢,牧本波动只是一个现象规律,而不是本质规律。
透过现象看本质,我们会发现,集成电路等各种事物发展的常态是通用,“通用到专用”只是达到通用状态后,持续向前发展的一些新的探索,是临时状态,最终还是要回归到新的通用阶段、新的通用状态。
专用是事物表面的、临时的、局部的特征,而通用则是事物本质的、长期的、全面的特征。
一言以蔽之:相比专用,通用是更高级的能力。
3、通用案例:智能手机
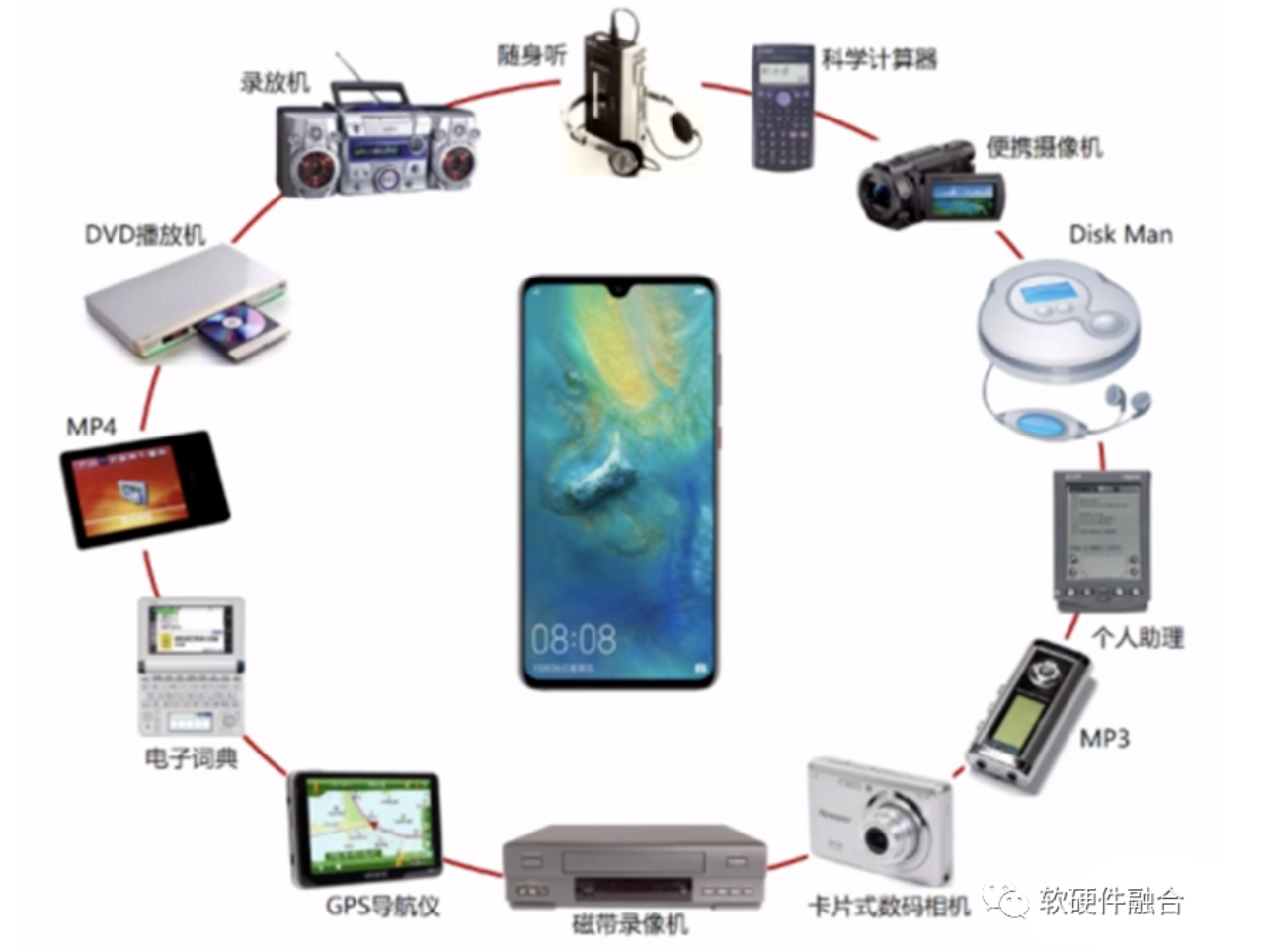
几乎我们每个人都拥有智能手机,但可能年轻一些的朋友没有见过这么多“古老”的电子设备。
它们每个设备都有自己特定的功能,导航仪用于导航,电子词典用于查词和学习,MP3用于播放音乐等等。
后来,随着智能手机的出现,这些专用的电子设备就都消失在了历史长河中。
智能手机,是通用的个人移动智能终端,在通用的硬件之上,通过各种不同的软件应用,实现各种各样丰富多彩的功能。
4 通用案例:AGI大模型
AGI通用人工智能,指的是具备与人类同等甚至超越人类的智能,能表现出正常人类所具有的所有智能行为。
传统的基于中小模型的人工智能,是专用AI,聚焦某个相对具体的业务方面。
比如专门用于人脸识别的AI,专门用于检测某种特定行为的AI等等。“场景千千万,模型千千万”。传统AI是完全碎片化的一个局面,场景之间的数据和模型等信息无法传递,无法整合。传统AI是弱人工智能。
目前火爆的GPT,则是模型参数发展量变到质变的过程,也是从专用的临时态往通用的常态发展的过程。目前,GPT4具备了一定的AGI能力,随着GPT的成功,AGI已经成为全球竞争的焦点。
GPT所在的OpenAI公司CEO奥特曼表示,AGI将于2030年之前到来。
随着GPT等具有通用能力的AI模型出现,之前的诸多专用AI模型已经在快速地萎缩,未来也必然走向消亡。
二、通用,是大芯片成功的必由之路
1、越来越复杂的系统需要通用
随着业务场景越来越复杂,场景的变化也就越来越快。即使同一领域同一场景,不同客户的业务之间仍然存在巨大差异,甚至在大客户内部,不同团队的业务之间也存在差异。此外,业务仍在快速地迭代。
作为芯片,无法做到为每一个场景定制开发专用芯片,一方面是专用芯片覆盖场景太少,此外专用芯片的生命周期较短。通用芯片,是唯一解决之道。
并且,越来越复杂的场景及场景的差异化,对芯片的通用性设计也提出了更高的要求。芯片的通用性设计,难度越来越高,需要更多的创新思路和更多的投入。
2、大芯片的高门槛需要通用
大芯片系统越来越庞大,设计规模越来越大,研发成本越来越成天文数字,门槛越来越高。
芯片只有更大规模地落地,才能有效摊薄研发成本。
更大的落地规模,意味着需要更多的场景和领域覆盖,意味着更高的通用性能力。
3、云边端融合需要通用
云边端融合,需要架构生态的整合,而不是碎片化:
- 最开始,当我们的设备是孤岛的时候,设备间相互约束较少,设备可以是任意架构,任意开发和运行环境,相互之间影响较小。
- 随着互联网和物联网的发展,万物互联,设备和设备之间开始有了通信。这个时候,我们需要双方按照既定的规范进行通信。
- 更进一步,更多的设备连接到一块了,我们的计算可以跳脱单机的约束,分布式计算逐渐流行。
分布式计算,需要考虑不同设备工作之间的工作划分和协同。因为工作的划分和协同,于是有了云边端。 - 随着发展,仅考虑协同也会有问题。哪些工作应该在终端做,哪些工作应该在云端做,哪些工作应该在边缘做,都是提前规划好的,此刻的协同是静态的。
但随着协同的工作越来越多、越来越复杂,我们发现实际上很难在早期就做好准确而仔细的任务划分,这样就需要在运行阶段动态地调整云边端的工作划分和协同。于是,融合产生了。
在融合阶段,云边端的架构和环境是一致的,某种程度上,从协同阶段的数以万计的设备单系统,升级成了融合阶段的数以万计设备组成的宏观的单个超级大系统。这个阶段,软件可以动态地、自由地在不同的平台上调度和运行。
要想实现云边端融合,具有高可扩展性的,架构和生态一致的通用计算芯片,是必选项。
三、既通用又高性能的计算存在吗?
很多朋友会提出疑问,性能和通用灵活性是矛盾,鱼和熊掌不可兼得。
我们的答案是:有办法做到鱼和熊掌兼得。
接下来是我们对这个问题的解答。
1、系统存在“二八定律”
二八定律是一个非常有意思的存在:
- RISC和CISC之争,是因为二八定律。人们发现,80%时间里,运行的常见指令只占指令数量的20%,而另外80%的指令较少使用。
- 存储分层,Cache 的存在,也是因为二八定律。程序局部性原理,用二八定律来解释,就是在某个时间段内,80%的大部分时间里,只是在访问20%的区域。
- 云计算,也是二八定律的一个典型的案例。我们从自建数据中心,到云计算IaaS、PaaS和SaaS,其实就是整个计算系统逐渐由供应商接管的过程。
系统是符合二八定律的:就是系统中存在80%相对确定且共性的工作,而20%的工作是相对多变且个性的工作。
这80%的工作供应商可以接管,而另外20%的工作则由用户自己把握较好。
并且,二八定律还存在嵌套的情况。基于此,我们可以对系统做如下三个层次的划分:
- 从系统中,分离出来80%共性的工作,这部分划分到系统的基础设施层。
- 系统中另外20%的个性的工作,可以再细分,也就是16%(20% * 80%)的工作相对共性,而另外4%(20% * 20%)的工作是极度个性的:
- 16%相对共性的工作,归属于系统的弹性加速层。
- 4%极度个性的工作,归属于系统的应用层。
2、团队分工协同,既通用又高效
DSA是专家,做专业的事情非常高效,但劣势在于过于专用;CPU是通才,啥都能干,但干啥都不够高效;而GPU的能力介于两者之间。
作为单兵,DSA、GPU、GPU都是有长有短。
但作为团队,发挥各自的优势,可以形成各自能力的高效整合:
- 80% 共性的基础设施层,因为工作任务相对确定,因此可以采用相对确定且高效的DSA处理器。
- 16% 相对共性的弹性加速层,因为工作任务具有一定的灵活弹性,但也不是无章可循,因此采用相对弹性的GPU处理器比较合适。
- 4% 极度个性的应用层。则采用最通用灵活的CPU处理器。
或者我们换个思路分析。系统中的各项工作,让各类DSA先挑,DSA挑剩下的工作GPU再挑,DSA和GPU都挑剩下的工作,最后由CPU来兜底完成。
这样就可以达到通用:通过CPU+GPU+DSAs的异构融合系统可以处理所有系统的工作。
可能,会有朋友挑战,DSA会有很多,万一不存在一个合适的DSA去处理特定的某个性能敏感的任务,这岂不是只能GPU或CPU来做,这是不是就不是极致的性能效率了?
如果从单机计算来看,这个问题是存在的。
但从宏观的云边端融合计算来看,这个问题根本就不是问题。
可以通过宏观调度的方式,找到最合适某个或某些DSAs最高效的计算平台,实现这个小系统的最极致性能的并且通用的运行环境。
四、第三代通用计算
1、基于异构协同视角的计算架构划分

基于多种异构处理器协作的视角,计算架构可以分为六个阶段:
- 第一代,CPU 单核串行阶段。
- 第二代,CPU 同构多核并行阶段。
- 第三代,CPU+GPU通用异构并行阶段。
- 第四代,CPU+DSA专用异构并行阶段。
- 第五代,CPU+GPU+DSAs 的多异构或超异构阶段。
- 第六代,CPU+GPU+DSAs 的异构融合阶段。
需要说明的是,新的阶段开始,并不意味着上一阶段的完全消亡,只是说它的场景会越来越少,逐渐走向凋零。

在2023年9月份,工信部电子五所发布的《异构融合计算技术白皮书》中,详细介绍了 “异构融合计算”技术的发展背景、技术细节,以及未来发展展望,欢迎下载阅读。
2、增加“通用”约束,形成通用计算架构
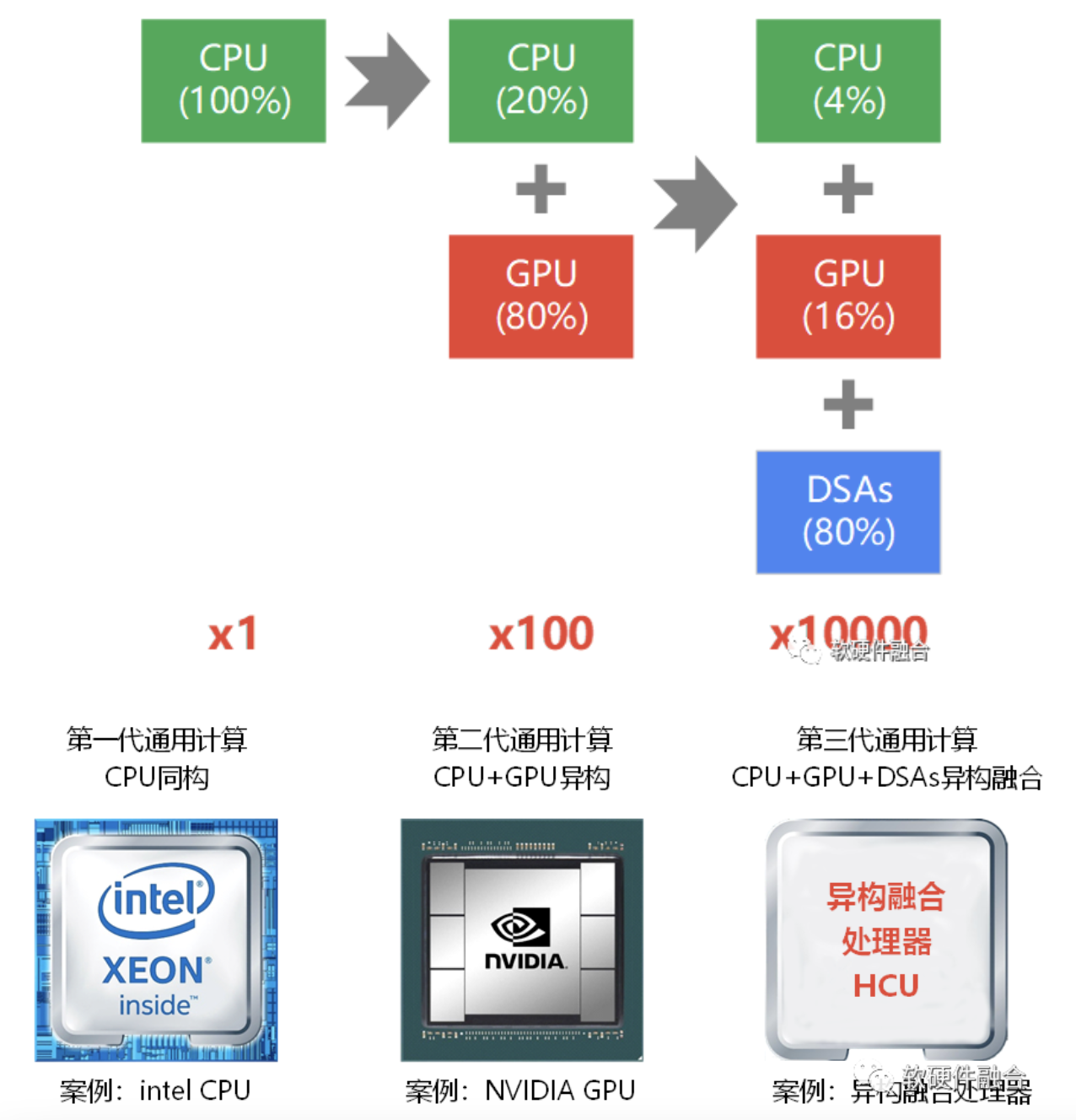
通用,是大芯片成功的必由之路。那么,我们有必要为计算架构增加“通用”的约束,这样计算架构的六个发展阶段可以缩减为三个阶段:
- 第一代通用计算,CPU同构通用计算。
依据“二八定律”,这一时期,所有(100%)的工作都是CPU来做。 - 第二代通用计算,CPU+GPU异构通用计算。
这一时期,GPU完成绝大部分(80%)的工作,CPU完成较少部分(20%)的工作。 - 第三代通用计算,CPU+GPU+DSAs异构融合通用计算。
这一时期,DSAs完成绝大部分(80%)的工作,GPU完成剩余较少部分中的绝大部分(16%)工作,剩下的(4%)工作,由CPU完成。
第一代通用计算,成就了Intel的成功;第二代通用计算,成就了NVIDIA的成功;第三代通用计算,才刚刚开始萌芽。
“弯道超车”的重要机会,希望国内有厂家能够脱颖而出,成就伟大的事业。
3、最终的形态,为什么是异构融合而不是DSA?
有些朋友可能会问,既然第二代是GPU,那么第三代为什么不是 AI-DSA或者 DPU这种形态的计算芯片?
在第二代通用计算时代,为了更好的通用性,独立的加速卡方式是比较好的选择。
所以最终成功的是独立形态的GPU,而不是CPU+GPU集成形态的APU。
在第三代通用计算时代,我们没法简单复制第二阶段的做法。因为第三阶段存在如下一些问题:
- 问题一,专用芯片无法承载通用计算。
AI芯片是一种DSA,DPU可以当作多种DSA的集合体。
DSA是一种专用芯片,无法实现通用计算,也无法主导 计算架构的走向。 - 问题二,架构和生态碎片化。
独立的DSA,面向的领域五花八门,实现的架构五花八门。
如果不考虑DSA的整合,会使得计算架构和生态碎片化。 - 问题三,协同问题。
第二代通用计算仅有两类处理器CPU和GPU,协同相对简单。
但第三阶段,处理器芯片的类型通常在5个以上,这一时期,核心问题在协同和融合。
来自不同厂商的各自独立的处理器芯片,几乎无法高效协同。
目前阶段,整合成单芯片的做法是可行的路径。
END
作者:Chaobowx
来源:软硬件融合
相关文章推荐
更多软硬件技术干货请关注软硬件融合专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。