相关文章
数字IC前端学习笔记:格雷码(含Verilog实现的二进制格雷码转换器)
4.公平轮询
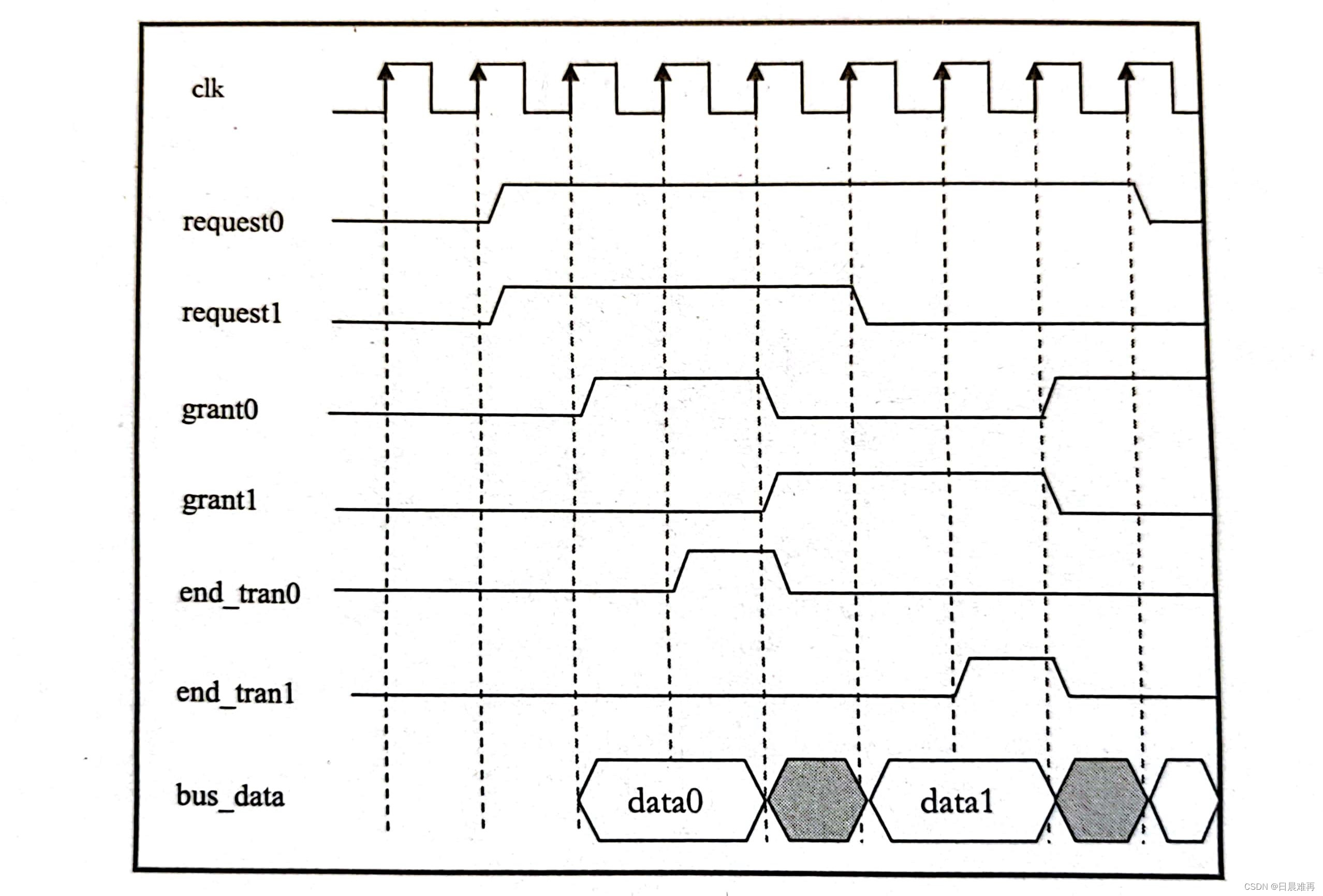
在公平轮询方案中,所有用户的优先级相等,每个用户依次获得授权。一开始,选择用户的顺序可以是任意的,但在一个轮询周期内,所有发出请求的用户都有公平得到授权的机会。以具有四个用户的总线为例,当它们全部将请求信号置为有效(高电平)时,request0将首先被授权,紧跟着是request1、request2,最后是request3。当循环完成后,request才会被重新授权。仲裁器每次仲裁时,依次查看每个用户的请求信号是否有效,如果一个用户的请求无效,那么将按序查看下一个用户。仲裁器会记住上一次被授权的用户,当该用户的操作完成后,仲裁器会按序轮询其他用户是否有请求。
一旦某个用户得到了授权,它可以长时间使用总线或占用资源,直到当前数据包传送结束或一个访问过程结束后,仲裁器才会授权其他用户进行操作。这种方案的一个特点是仲裁器没有对用户获得授权后使用总线或访问资源的时间进行约束。该方案适用于基于数据包的协议,例如,以太网交换或PCIe交换机,当多个入口的包希望从一个端口输出时,可以采用这种机制。此外还有一种机制,每个用户获得授权后,可以占用资源的时间片长度是受约束的,每个用户可以占用资源的时间不能超过规定的长度。如果一个用户在所分配的时间结束之前完成了操作,仲裁器将轮询后续的用户。如果在所分配的时间内用户没有完成操作,则仲裁器收回授权并轮询后续的用户。此方案适用于突发操作,每次处理一个突发(一个数据块),此时没有数据包的概念。传统的PCI总线或AMBA、AHB总线采用的就是这种方案。在PCI中,仲裁器会给当前获得授权的主机留出一个或多个时钟周期的时间供主机保存当前操作信息,下一次再获得授权时,该主机可以接着传输数据。
下图为公平轮询的波形图。
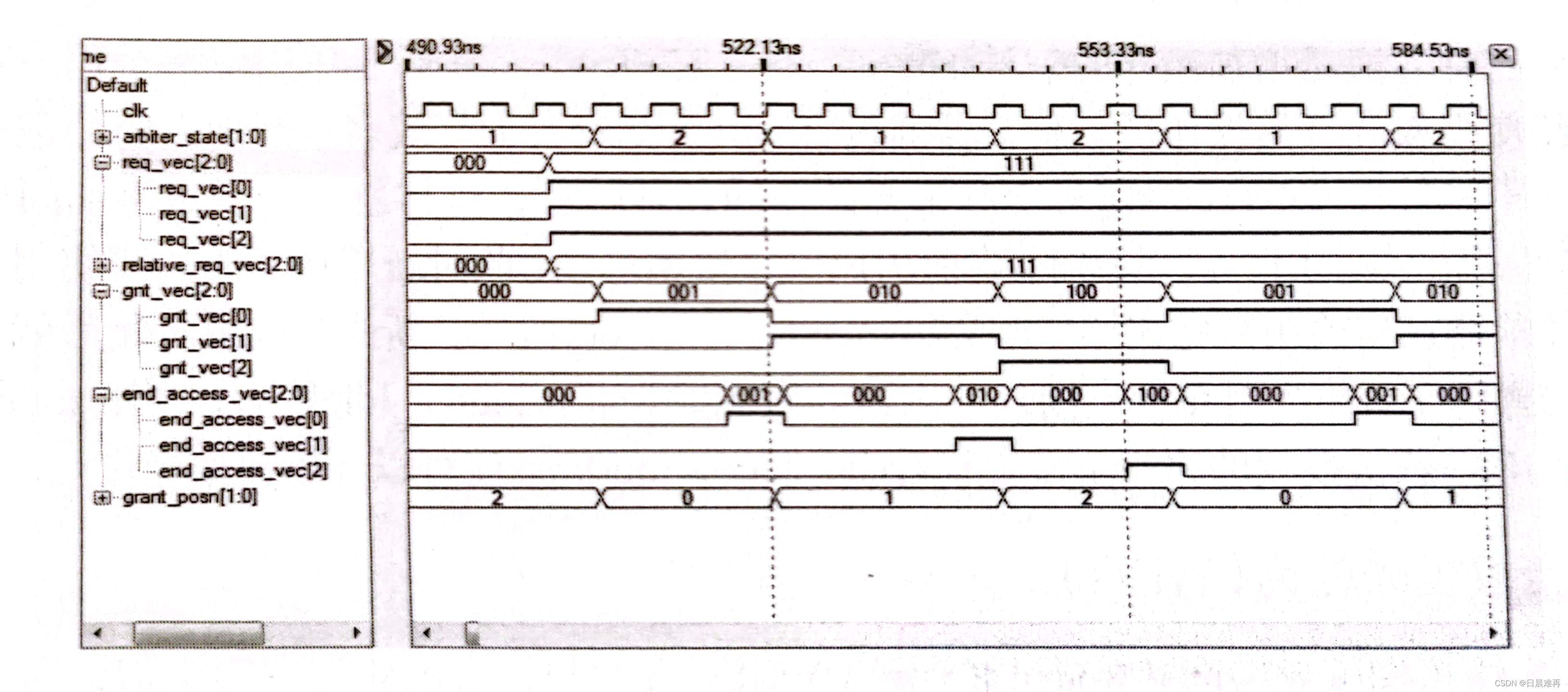
公平轮询的代码及仿真结果如下。
module arbiter_roundrobin(
clk,resetb,
req_vec,
end_access_vec,
gnt_vec);
input clk,resetb;
input [2:0] req_vec,end_access_vec;
output [2:0] gnt_vec;
reg [1:0] arbiter_state,arbiter_state_nxt;
reg [2:0] gnt_vec,gnt_vec_nxt;
reg [2:0] relative_req_vec;
wire any_req_asserted;
reg [1:0] grant_posn,grant_posn_nxt;
parameter IDLE = 2'b00;
parameter END_ACCESS = 2'b01;
assign any_req_asserted = (req_vec != 0);
always@(*) begin
relative_req_vec = req_vec;
case(grant_posn)
2'd0: relative_req_vec = {req_vec[0], req_vec[2:1]};
2'd1: relative_req_vec = {req_vec[1:0], req_vec[2]};
2'd2: relative_req_vec = {req_vec[2:0]};
endcase
end
always@(*) begin
arbiter_state_nxt = arbiter_state;
grant_posn_nxt = grant_posn;
gnt_vec_nxt = gnt_vec;
case(arbiter_state)
IDLE:begin
if((gnt_vec == 0) || (end_access_vec[0] & gnt_vec[0]) ||
(end_access_vec[1] & gnt_vec[1]) || (end_access_vec[2] & gnt_vec[2]))
begin
if(any_req_asserted)
arbiter_state_nxt = END_ACCESS;
if(relative_req_vec[0])
case(grant_posn)
2'd0: begin gnt_vec_nxt = 3'b010; grant_posn_nxt = 3'd1; end
2'd1: begin gnt_vec_nxt = 3'b100; grant_posn_nxt = 3'd2; end
2'd2: begin gnt_vec_nxt = 3'b001; grant_posn_nxt = 3'd0; end
endcase
else if(relative_req_vec[1])
case(grant_posn)
2'd0: begin gnt_vec_nxt = 3'b100; grant_posn_nxt = 3'd2; end
2'd1: begin gnt_vec_nxt = 3'b001; grant_posn_nxt = 3'd0; end
2'd2: begin gnt_vec_nxt = 3'b010; grant_posn_nxt = 3'd1; end
endcase
else if(relative_req_vec[2])
case(grant_posn)
2'd0: begin gnt_vec_nxt = 3'b001; grant_posn_nxt = 3'd0; end
2'd1: begin gnt_vec_nxt = 3'b010; grant_posn_nxt = 3'd1; end
2'd2: begin gnt_vec_nxt = 3'b100; grant_posn_nxt = 3'd2; end
endcase
else
gnt_vec_nxt = 3'b000;
end
end
END_ACCESS:begin
if((end_access_vec[0] & gnt_vec[0]) || (end_access_vec[1] & gnt_vec[1])
|| (end_access_vec[2] & gnt_vec[2]))
begin
arbiter_state_nxt = IDLE;
if(relative_req_vec[0])
case(grant_posn)
2'd0: begin gnt_vec_nxt = 3'b010; grant_posn_nxt = 3'd1; end
2'd1: begin gnt_vec_nxt = 3'b100; grant_posn_nxt = 3'd2; end
2'd2: begin gnt_vec_nxt = 3'b001; grant_posn_nxt = 3'd0; end
endcase
else if(relative_req_vec[1])
case(grant_posn)
2'd0: begin gnt_vec_nxt = 3'b100; grant_posn_nxt = 3'd2; end
2'd1: begin gnt_vec_nxt = 3'b001; grant_posn_nxt = 3'd0; end
2'd2: begin gnt_vec_nxt = 3'b010; grant_posn_nxt = 3'd1; end
endcase
else if(relative_req_vec[2])
case(grant_posn)
2'd0: begin gnt_vec_nxt = 3'b001; grant_posn_nxt = 3'd0; end
2'd1: begin gnt_vec_nxt = 3'b010; grant_posn_nxt = 3'd1; end
2'd2: begin gnt_vec_nxt = 3'b100; grant_posn_nxt = 3'd2; end
endcase
end
else
gnt_vec_nxt = 3'b000;
end
endcase
end
always@(posedge clk or negedge resetb)begin
if(!resetb) begin
arbiter_state <= IDLE;
gnt_vec <= 0;
grant_posn <= 0;
end
else begin
arbiter_state <= arbiter_state_nxt;
gnt_vec <= gnt_vec_nxt;
grant_posn <= grant_posn_nxt;
end
end
endmoduleVerilog代码中使用了组合逻辑根据grant_posn上次授权位置,来对输出的请求进行排序,优先级最高的请求放在relative_req_vec的最低位,而上次授权的请求则循环移位至最高位。在仲裁器进行轮询时,从低位至高位进行依次遍历,对优先级最高的请求进行授权并记录grant_posn。grant_posn和gnt_vec信号使用寄存器保存,所以组合逻辑中使用了grant_posn_nxt和gnt_vec_nxt信号。
以上内容来源于《Verilog高级数字系统设计技术和实例分析》