
笔记整理:乔硕斐,浙江大学硕士,研究方向为自然语言处理
链接:https://arxiv.org/abs/2303.11366
动机
本文探究了让大规模语言模型具备自我反思能力的方法,让大模型模拟人类的思考方式,自己发现推理过程中的错误并实现自我反思和纠正。
最近,决策型大语言模型(LLM)代理在各种基准测试中展现出了令人印象深刻的性能。然而,这些最先进的方法通常需要对内部模型进行微调、对外部模型进行微调或对定义的状态空间进行策略优化。由于高质量训练数据的稀缺性或状态空间的缺乏定义,实现这些方法可能会带来挑战。此外,这些代理不具备人类决策过程固有的某些品质,特别是从错误中学习的能力。自我反思使人类能够通过试错的过程有效地解决新问题。本文提出Reflexio,这是一种赋予代理动态记忆和自我反思能力的方法,以增强其现有的推理轨迹和任务特定的行动选择能力。为了实现完全自动化,本文引入了一种简单而有效的启发式方法,使代理能够确定halluciation实例、避免行动序列的重复,并在某些环境中构建给定环境的内部记忆映射。
方法架构
本文面向的任务是语言模型做descision-making,主要架构如下图所示:
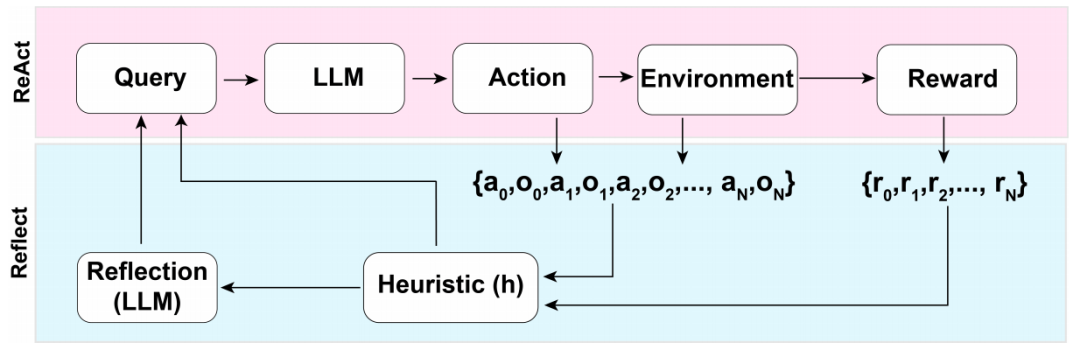
本文使用ReAct作为反思模型,但任何decision-making方法在这个架构中都是适用的。
基本设定
在典型的强化学习(RL)场景中,代理通过在环境中执行操作来从观察中学习解决问题。在时间步骤t中,代理处于状态st,并从环境中接收观察值ot,并根据其当前策略π(at|ct)执行一个操作at。在基于文本的环境中,ct是根据当前状态和轨迹历史记录给代理的上下文,包括过去的观察和行动。由于大模型参数调节几乎是不可能的,因此reflexion不需要学习一个状态空间上的策略π。此外,reflexion限制了给代理的特定奖励信息,以(1)证明Reflexion与其他工作的一致性和(2)保持将该方法推广到广泛的问题范围的能力。此外,reflexion为代理配备启发式函数来检测常见的失败模式。
启发函数
这里定义了启发式函数h(st, at, Ω, ε, [a0, o0, . . . , at−1, ot−1]),告诉代理何时进行自我反思,其中t是时间步骤,st是当前状态,Ω和ε是用于允许最大重复动作循环数和允许的总动作数的超参数,而[a0, o0, . . . , at−1, ot−1]则是轨迹历史记录。
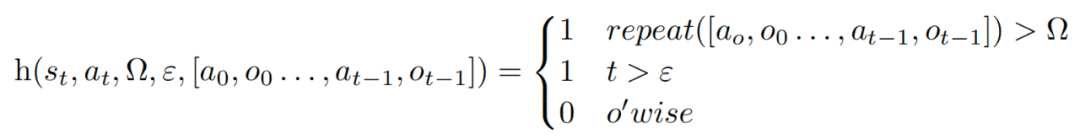
repeat是一个简单的函数,确定产生相同观察值的重复动作循环的数量。Ω是最大的相同循环次数,用于检测连续动作的幻觉。ε通过限制每次试验中在环境中允许的最大动作数,强制执行高效的规划。启发函数h的设计是为了替换human-in-the-loop的角色,以检测halluciation或inefficient planning的迹象。
反思机制
如果启发式函数h建议在t处进行自我反思,代理会在其当前状态st,上一个奖励rt-1,先前的动作和观察[a0,o0,...,at,ot],以及代理现有的工作记忆mem上启动自我反思过程。反思循环旨在通过试错帮助代理纠正幻觉和低效的常见情况。用于自我反思的模型是一个LLM,通过two-shot prompting的方法触发它的反思能力。为了防止代理记忆正确答案,这里不允许它访问给定问题的特定领域解决方案。自我反思机制可以定义为如下函数:
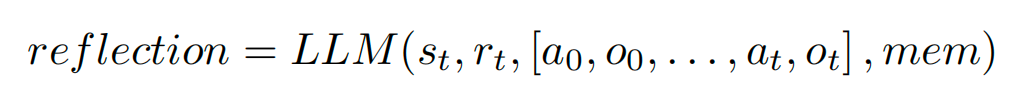
最后,我们将反思添加到代理的mem中,重置环境并开始下一轮试验。
奖励模型
通常,设计或训练一个既有效又广泛适用的奖励模型可能是具有挑战性的,本文将代理限制为二元奖励模型。二元奖励模型是一种将值0或1分配给代理在当前状态下采取的行动的奖励函数。1表示成功的结果,0表示失败的结果。选择二元奖励函数是为了紧密限制代理的知识范围,使其仅能基于来自世界的观察和环境中的成功或失败状态来评估其当前性能,而不是使用更描述性的奖励模型的多值或连续输出来评估其当前性能。通过将代理的知识限制为环境中的二元成功状态,迫使代理在没有外部输入的情况下进行有意义的性能推断,以有效地改进其未来的决策。最后,二元奖励模型在许多语言问题上都具有广泛的适用性,如代码生成和代码调试。本文在两个数据集上进行实验,分别是AlfWorld和HotPotQA。在AlfWorld环境中,在每个时间步骤查询AlfWorld引擎,以检查当前状态是否为成功状态。在HotPotQA基准测试中,在回答后使用精确匹配(EM)对代理的响应进行评分。
评估与讨论
reflexion在AlfWorld和HotPotQA上的实验结果分别如下两图所示:
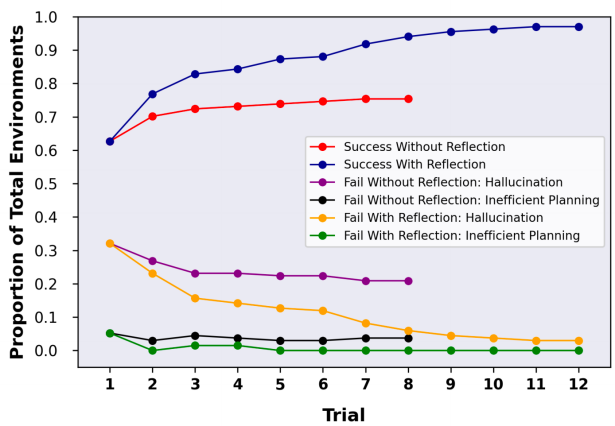
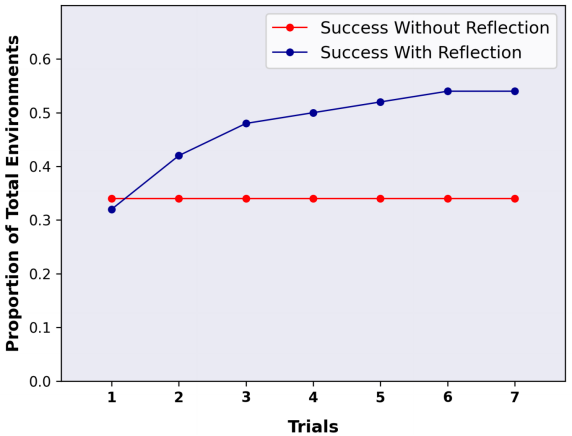
可以发现随着反思轮数的增加,模型效果得到了有效的提高,比without reflexion的baseline效果有明显的增强,这验证了大模型具有一定自我反思的能力。
另外观察左图可以发现,halluciation导致的错误比inefficient planning更加常见,而随着实验轮数的增加,reflexion对于halluciation错误的修正效果显著。
下面分别是用于AlfWorld和HotPotQA反思的two-shot prompt:
AlfWorld


HotPotQA


OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。