HRNetV2+OCR
前言
本篇文章仅是个人经过阅读原文和相关博客后的简单总结,其中的理解可能有误,望各位大佬批评指导。
本文分为两个部分分别是HRNetV2(High-resolution Represents net)和OCR(Object-Contextual Represent)部分。
参考资料如下:
论文:
High-Resolution Representations for Labeling Pixels and Regions
作者:Ke Sun
中国科学技术大学,亚洲微软研究院 2019
论文:
Object-Contextual Representations for Semantic Segmentation
作者:Yuhui Yuan
中国科学院计算所,亚洲微软研究院 2020
博客:HRNet网络简介
作者:太阳花的小绿豆
博客:HRNet详解
作者:gdtop818
博客:HRNet-OCR笔记
作者:vincent
我总结的模型代码:https://github.com/heavenle/custom_segmentation_Network_base_mmcv
1. 创新点
1.HRNetv2创新点(其实也是HRNetV1的创新点。相对于V1而言,V2是最后输出使用了全部的多尺度特征,而V1只使用高分辨率特征)
1.1 多尺度并行组卷积( multi-resolution group convolution):多尺度并行组卷积可以始终维持高分辨率表示,而不是串行卷积那样从高分辨率到低分辨率的方式进行卷积,这样做可以减少尺度特征的损失。
1.2 多尺度卷积(multi-resolution convolution):对多个尺度的特征图进行融合,使得融合后的特征图具有更强的特征表示。扫描二维码关注公众号,回复: 15493088 查看本文章
2.OCR创新点
学习每个像素和全部类别区域的相互关系,从而强化每个像素对于所属类别区域的表达能力,其思想类似于自注意力机制。
2. HRNetV2
2.1 网络结构

可以明显看出,该网络由4个模块组成。除了第一个模块只包含多尺度组卷积外,剩下3个模块都包含多尺度组卷积和多尺度卷积,其中多尺度组卷积是并行卷积,每个尺度相互独立。多尺度卷积则是不同尺度特征图相互融合。
经过第一个模块后输出尺度为4倍下采样特征图,8倍下采样特征图;
经过第二个模块后输出尺度为4倍下采样特征图,8倍下采样特征图,16倍下采样特征图;
经过第三个模块后输出尺度为4倍下采样特征图,8倍下采样特征图,16倍下采样特征图,32倍下采样特征图;
经过第四个模块后输出尺度为4倍下采样特征图,8倍下采样特征图,16倍下采样特征图,32倍下采样特征图。
以512x512x3的特征图为例,整体网络的数据流程图如下图所示:

Bottleneck

Basic Block
2.2 多尺度组卷积

多尺度组卷积以并行的方式对多个不同尺度的特征图分别进行卷积,从而构成高分辨率到低分辨率的子网,而不是像大多数现有解决方案那样串行连接。因此,该方法能够保持高分辨率,而不是通过一个以低分辨率到高分辨率的方式恢复特征图分辨率,进而可以有效保持特征图在空间上的精确率。
HRNetV2除了第一个模块中的多尺度组卷积使用的是Bottleneck结构外,剩下的三个模块使用的是BasicBlock结构。
2.3 多尺度卷积

多尺度卷积是一种类似于全连接方式的多尺度融合方法。类似于图c,输入和输出都划分为多个尺度不一样的特征子集,然后输入和输出的特征子集以全连接的方式进行融合,其中每个输出的特征子集都是所有输入特征子集经过或上采样或下采样后的结果之和。相比于串行连接中的跳接方式(Unet系列的跳接方式),这样做可以在保持原有尺度的特征信息下,融合不同尺度的特征信息,从而加强该尺度下的特征表示能力。
参考下图可以很好理解:
例如,一张512x512x3的图像在经过HRNet第三个模块后进行多尺度融合时的网络内容。
其中:
① 上采样是通过bilinear (nearest neighbor) upsampling方式来将图片上采样的。
② 下采样是通过kernel=3,stride=2,padding=1的卷积实现的。
③ 融合方式为特征图相加的形式。

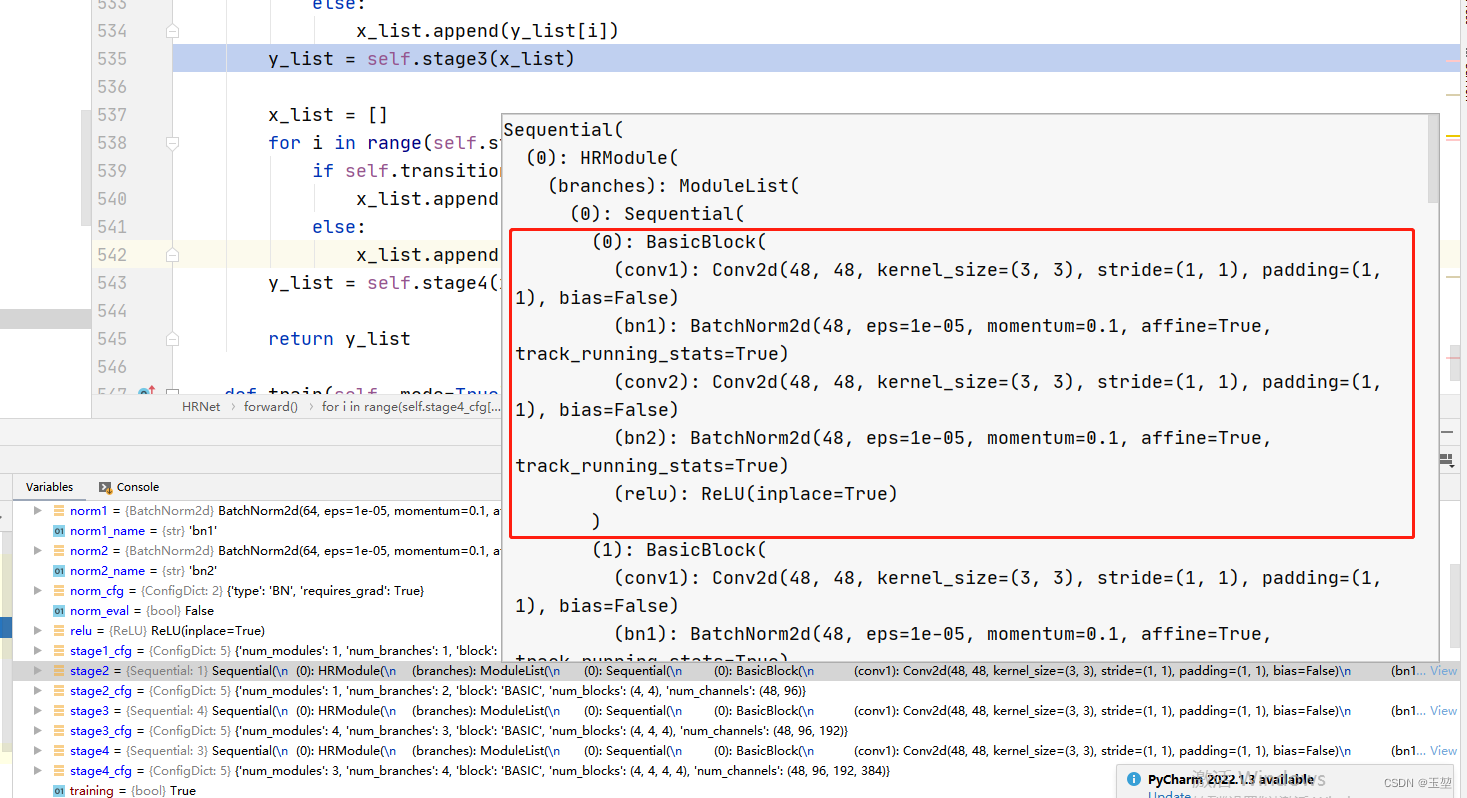
源码中的上采样和下采样的方式,以stage2为例。

上图表示的就是下图红框的内容。
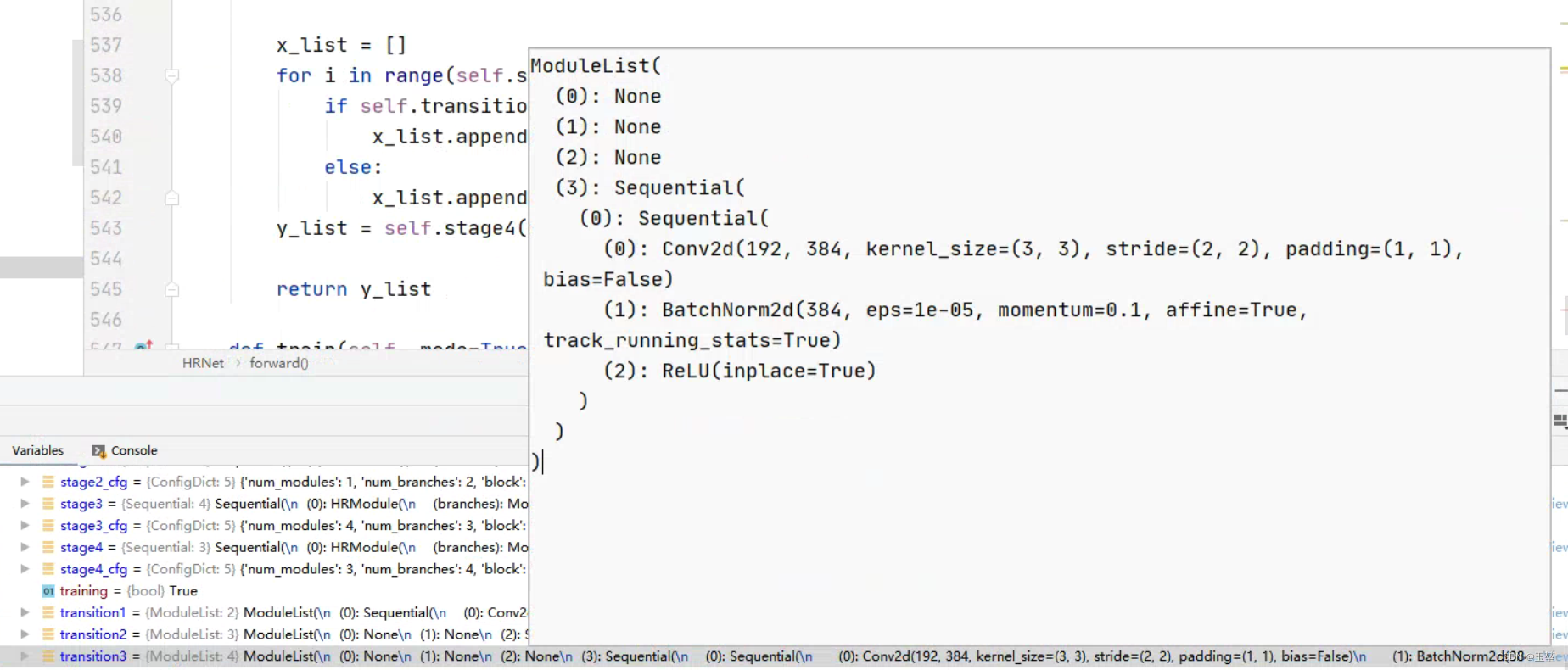
值得注意的是16x16x384的特征图在代码中其实就是32x32x192的2倍下采样,并没有融合其他尺度的信息。 源码debug可以看出(源码来自于MMSegmentation框架下的HRNet网络代码):

2.4 HRNet的输出层

从上图可以看出,HRNetV1仅仅只是利用了高分辨率的特征图,而其他低分辨率的特征图没有很好的利用。因此,作者提出两种融合其他尺度特征图的方式。
①针对语义分割和人脸识别任务而言,作者在HRNetV1的基础上将其他尺度的特征图进行上采样(依然是双线性插值),并拼接到一起,之后通过1x1的卷积来生成语义分割图或者热点图。该模型简记为HRNetV2。
②针对目标检测任务,作者在HRNetV1的基础上将其他尺度的特征图进行上采样(依然是双线性插值),并拼接到一起,之后通过average pooling来生成多尺度表示。该模型简记为HRNetV2p。
作者在后续的实验中也论证了经过简单的聚合多尺度特征图后,HRNetV2得到很大的提升。

3 OCR(目标上下文表示)
一个位置的上下文通常都指围绕该位置的一组位置的集合。例如,一个像素周边的像素集合。而早期的研究就是针对语义空间范围的上下文信息。例如,ASPP中的空洞卷积就是通过设置不同的膨胀率来获取不同空间范围的上下文信息。
OCR的特点其实就是通过计算像素和多个目标区域之间的相互关系,来强化该像素的特征表示,
此想法的启发是分配给一个像素的类标签是该像素所属对象的类别,那么只要学习该像素和所有类别区域的关系,就可以提高像素对所属类别区域的表达能力。该方法的思想类似于自注意力机制,如果对自注意力机制无法理解的,可以参考我的另一篇博客Transformer:注意力机制(attention)和自注意力机制(self-attention)的学习总结。
下面就是OCR和ASPP的区别,可以看出空洞卷积学习的是周边像素的关系,而OCR学习的是像素和类别区域之间的关系。

OCR的效果作者已经进行了实验。

3.1 OCR的网络框架

主要有三个模块,对应图中三个框:
粉色框:①将上下文像素划分为一组软目标区域,每个通道对应一个类别分割的结果。此处软目标区域是一个语义分割的输出结果,该分割结果不直接用于最终结果,而是作为一种粗分类结果用于计算后续的目标区域的特征表示。
紫色框:②通过聚合相应目标区域中像素的特征表示,来获取目标区域的特征表示。
黄色框:③最后,用目标上下文表示来增强每个像素的特征表示。
整体网络数据流程图如下:

3.2 Object region representations
获取目标区域特征表示。如下图公式所示,K是类别总数,k ∈ \in ∈K,pi指的是图片上第i个像素。xi是像素pi对应的特征表示。 m ~ \widetilde{m} m ki则是pi像素对应的第k个类别领域的正则化值。

生成目标区域表示的数据流程。
720 × \times × 128 × \times × 256是channel × \times ×height × \times ×width。其中720是HRNetV2-W48中输出的4个特征维度(48, 96, 192, 384)拼接出来的结果。fk就是最终的目标区域表示。

3.3 Object contextual representations
接下来是计算目标领域上下文的表示。
下面这副图可以明显的看到是一个softmax函数,这种形式等同于自注意力机制的softmax(Q ⋅ \cdot ⋅ KT),即第i个像素和每一个目标区域计算相似度,来寻找和该像素匹配度最高的特征表示形式。
k(x, f)的形式如下图英文描述的那样,是一个由1 × \times × 1 conv+BN+Relu的转换模块,目的是更好的学习特征之间的相关性。
计算得出目标上下文表示。
为了方便理解,这两个公式中 ϕ \phi ϕ(xi)可以看作自注意力机制的Querry, ψ \psi ψ(fk)可以看作自注意力机制的Key,可以将wik可以看作为Softmax(Query ·Key), δ \delta δ(fk)则可以看作为Value,yi可以看作自注意力机制的最终结果yi=Softmax( ( Q u e r y ⋅ K e y ) d \frac{(Query ·Key)}{\sqrt[]{d}} d(Query⋅Key))·Vaule


目标上下文表示的数据流程图如下:

3.4 Augmented representations
最后的输出结果是由两部分组成,第一部分是xi的原始像素表示,第二部分是目标上下文表示yi。
最后的输出则是将上述两个部分拼接而成并使用1 × \times × 1 conv+BN+Relu进行降维到所需的输出维度。
像素的增强表示数据流程图如下:


4 基于MMsegmentation代码
OCR部分
class OCRHead(BaseCascadeDecodeHead):
"""Object-Contextual Representations for Semantic Segmentation.
This head is the implementation of `OCRNet
<https://arxiv.org/abs/1909.11065>`_.
Args:
ocr_channels (int): The intermediate channels of OCR block.
scale (int): The scale of probability map in SpatialGatherModule in
Default: 1.
"""
def __init__(self, ocr_channels, scale=1, **kwargs):
super(OCRHead, self).__init__(**kwargs)
self.ocr_channels = ocr_channels
self.scale = scale
self.object_context_block = ObjectAttentionBlock(
self.channels,
self.ocr_channels,
self.scale,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
self.spatial_gather_module = SpatialGatherModule(self.scale)
self.bottleneck = ConvModule(
self.in_channels,
self.channels,
3,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def forward(self, inputs, prev_output):
#inputs是HRNetV2-w48的输出->list(48x128x256, 96x128x256, 192x128x256, 384x128x256), 注意w48指的是头一个特征图的维度。
#pre_outout是HRNetV2-w48经过一个FCN_Head后的结果为batch x num_class x 128 x 256
"""Forward function."""
x = self._transform_inputs(inputs) # 将4个特征图上采样并拼接在一起生成720x128x256
feats = self.bottleneck(x) # 将结果720x128x256 降维到512x128x256,这就是上面公式讲的Xi
context = self.spatial_gather_module(feats, prev_output) # 获取目标领域表示, batch x num_class X dims
object_context = self.object_context_block(feats, context)# 获得像素增强表示, 输出为batch x 512 x 128 x 256
output = self.cls_seg(object_context)# 进行语义分割,输出为batch x num_class x 128 x 256
return output
目标领域表示
class SpatialGatherModule(nn.Module):
"""Aggregate the context features according to the initial predicted
probability distribution.
Employ the soft-weighted method to aggregate the context.
"""
def __init__(self, scale):
super(SpatialGatherModule, self).__init__()
self.scale = scale
def forward(self, feats, probs):
# feat: xi,维数512 x 128 x 256
# probs:预测输出 num_classes x 128 x 256
"""Forward function."""
batch_size, num_classes, height, width = probs.size()
channels = feats.size(1)
probs = probs.view(batch_size, num_classes, -1) # probs:batch_size x num_classes x 32768
feats = feats.view(batch_size, channels, -1)# feats:batch_size x 512 x 32768
# feats = [batch_size, height*width, channels]
feats = feats.permute(0, 2, 1)
# probs =[batch_size, num_classes, height*width]
probs = F.softmax(self.scale * probs, dim=2)
# ocr_context = [batch_size, num_classes, channels]
ocr_context = torch.matmul(probs, feats) # ocr_context:batch_size x num_classes x 512
ocr_context = ocr_context.permute(0, 2, 1).contiguous().unsqueeze(3)# ocr_context:batch_size x 512 x num_classes x 1
return ocr_context
目标上下文表示和最终像素增强表示
class SelfAttentionBlock(nn.Module):
"""General self-attention block/non-local block.
Please refer to https://arxiv.org/abs/1706.03762 for details about key,
query and value.
Args:
key_in_channels (int): Input channels of key feature.
query_in_channels (int): Input channels of query feature.
channels (int): Output channels of key/query transform.
out_channels (int): Output channels.
share_key_query (bool): Whether share projection weight between key
and query projection.
query_downsample (nn.Module): Query downsample module.
key_downsample (nn.Module): Key downsample module.
key_query_num_convs (int): Number of convs for key/query projection.
value_num_convs (int): Number of convs for value projection.
matmul_norm (bool): Whether normalize attention map with sqrt of
channels
with_out (bool): Whether use out projection.
conv_cfg (dict|None): Config of conv layers.
norm_cfg (dict|None): Config of norm layers.
act_cfg (dict|None): Config of activation layers.
"""
def __init__(self, key_in_channels, query_in_channels, channels,
out_channels, share_key_query, query_downsample,
key_downsample, key_query_num_convs, value_out_num_convs,
key_query_norm, value_out_norm, matmul_norm, with_out,
conv_cfg, norm_cfg, act_cfg):
super(SelfAttentionBlock, self).__init__()
#................略.......................
def init_weights(self):
"""Initialize weight of later layer."""
#................略.......................
def build_project(self, in_channels, channels, num_convs, use_conv_module,
conv_cfg, norm_cfg, act_cfg):
"""Build projection layer for key/query/value/out."""
#................略.......................
def forward(self, query_feats, key_feats):
# query_feats:batch x 512 x 128 x 256
# key_feats: batch x 512 x num_classes x 1
"""Forward function."""
batch_size = query_feats.size(0)
query = self.query_project(query_feats)# query:batch x 256 x 128 x 256
if self.query_downsample is not None:
query = self.query_downsample(query)
query = query.reshape(*query.shape[:2], -1)# query:batch x 256 x 32768
query = query.permute(0, 2, 1).contiguous()# query:batch x 32768 x 256
key = self.key_project(key_feats)# key:batch x 256 x num_classes
value = self.value_project(key_feats)# key:batch x num_classes x 256
if self.key_downsample is not None:
key = self.key_downsample(key)
value = self.key_downsample(value)
key = key.reshape(*key.shape[:2], -1)
value = value.reshape(*value.shape[:2], -1)
value = value.permute(0, 2, 1).contiguous()
sim_map = torch.matmul(query, key)
if self.matmul_norm:
sim_map = (self.channels**-.5) * sim_map
sim_map = F.softmax(sim_map, dim=-1)
context = torch.matmul(sim_map, value)
context = context.permute(0, 2, 1).contiguous()
context = context.reshape(batch_size, -1, *query_feats.shape[2:])
if self.out_project is not None:
context = self.out_project(context)
return context
总结
- OCRmodule,本质上是针对HRNet的输出进行自注意力机制。每个像素针对不同的目标类别都做相似度匹配。这是像素和目标领域之间的,并不是像素和像素之间的。
- OCR有两个loss,在mmseg上都用的交叉熵函数。这两个loss分别是针对软目标领域【HRnet+FCN后得到的分类结果。】,该loss的目的是使用于自注意力机制的粗分类结果,应该在GT的监督下。另一个loss是总在最后的分类结果上,目的是为了优化网络。用于软分类监督的权重为0.4,用于最终分类损失的权重为1。