背景
flinkcdc 2.0版本上线了一个新功能–支持动态加表这个是很有用的feature,本文介绍在开发中如何使用。
设想下假如你一个 CDC pipeline 监控了 4 张表,突然有天业务需求需要再加几张表,你肯定不想另起作业 (浪费资源),那么这个
feature 可以让你在当前作业直接增加需要监控的表。新增表都是先做全量再优雅地切换到增量,遇到新增监控表时不用新起作业,极大地节约了资源
flinkcdc 使用 flink-sql 的方式每同步一张表都需要启动一个新的作业,因此不存在同一个作业中 新增表的问题。该feature主要针对 api 的方式。flinkcdc 只能作为 source 用于采集数据,常用的使用方法如下:
private static MySqlSource<String> createMysqlSource(ParameterTool param) {
return MySqlSource.<String>builder()
.hostname(param.get(ConfigConstant.SOURCE_MYSQL_HOST)) // mysql host, 127.0.0.1
.port(param.getInt(ConfigConstant.SOURCE_MYSQL_PORT)) // mysql port, 3306
.username(param.get(ConfigConstant.SOURCE_MYSQL_USERNAME)) // username
.password(param.get(ConfigConstant.SOURCE_MYSQL_PASS)) // pass
.databaseList("aa") //库名
.tableList("aa.stu_1") // 表名
.deserializer(new MysqlBinlogSerialize())
.build();
}
这段代码使用flinkcdc 创建了一个 采集mysql 的数据源,采集表名为"aa.stu_1"。
假设我的作业已经上线,这时候我期望在这个作业中新增采集表:“aa.stu_2” 我该如何做呢?
解决方案
1、第一步:修改代码,创建cdc 数据源的时候,需要指定 .scanNewlyAddedTableEnabled(true)
下面是修改后的代码:
private static MySqlSource<String> createMysqlSource(ParameterTool param) {
return MySqlSource.<String>builder()
.hostname(param.get(ConfigConstant.SOURCE_MYSQL_HOST)) // mysql host, 127.0.0.1
.port(param.getInt(ConfigConstant.SOURCE_MYSQL_PORT)) // mysql port, 3306
.username(param.get(ConfigConstant.SOURCE_MYSQL_USERNAME)) // username
.password(param.get(ConfigConstant.SOURCE_MYSQL_PASS)) // pass
.databaseList("aa") //库名
.tableList("aa.stu_1", "aa.stu_2") // 表名
.deserializer(new MysqlBinlogSerialize())
.scanNewlyAddedTableEnabled(true)
.build();
}
注意:.startupOptions() 需要配置成 StartupOptions.initial(),因为默认就是 init,可以不写。
2、第二步:cancel job 取消作业,并记录checkpoint 路径
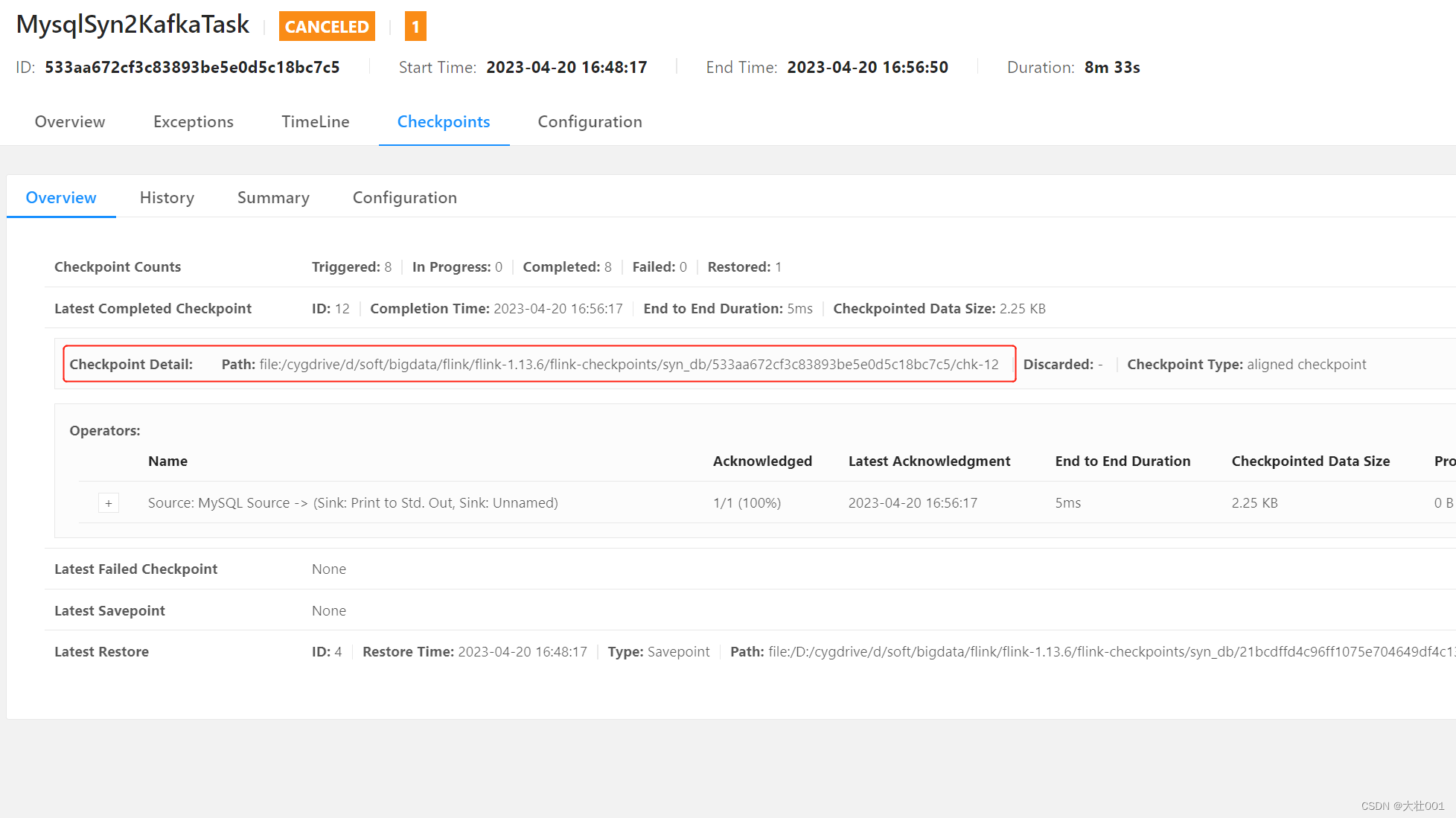
3、第三步:上传 新的 jar 包后,从刚刚记录的 checkpoint 启动。
作业启动后,会全量同步 aa.stu_2 表数据,然后增量同步 aa.stu_1、aa.stu_2。
至此,修改完成。
其他事项:
我最开始的时候重启了作业,发现新增的表 并没有同步,在日志中找到如下报错信息:
2023-04-20 16:49:01,778 ERROR io.debezium.connector.mysql.MySqlStreamingChangeEventSource [] - Encountered change event 'Event{
header=EventHeaderV4{
timestamp=1681980541000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=35, nextPosition=16589, flags=0}, data=TableMapEventData{
tableId=252, database='shou_xian', table='stu_2', columnTypes=3, 3, columnMetadata=0, 0, columnNullability={
1}, eventMetadata=null}}' at offset {
transaction_id=null, file=mysql_bin.000025, pos=16458, server_id=1, event=1} for table shou_xian.stu_2 whose schema isn't known to this connector. One possible cause is an incomplete database history topic. Take a new snapshot in this case.
Use the mysqlbinlog tool to view the problematic event: mysqlbinlog --start-position=16535 --stop-position=16589 --verbose mysql_bin.000025
2023-04-20 16:49:01,779 ERROR io.debezium.connector.mysql.MySqlStreamingChangeEventSource [] - Error during binlog processing. Last offset stored = null, binlog reader near position = mysql_bin.000025/16535
2023-04-20 16:49:01,779 WARN com.ververica.cdc.connectors.mysql.debezium.task.context.MySqlErrorHandler [] - Schema for table shou_xian.stu_2 is null
2023-04-20 16:49:01,779 INFO io.debezium.connector.mysql.MySqlStreamingChangeEventSource [] - Error processing binlog event, and propagating to Kafka Connect so it stops this connector. Future binlog events read before connector is shutdown will be ignored.
需要在创建mysql数据源的时候调用 .scanNewlyAddedTableEnabled(true) 方法即可,参考第一步