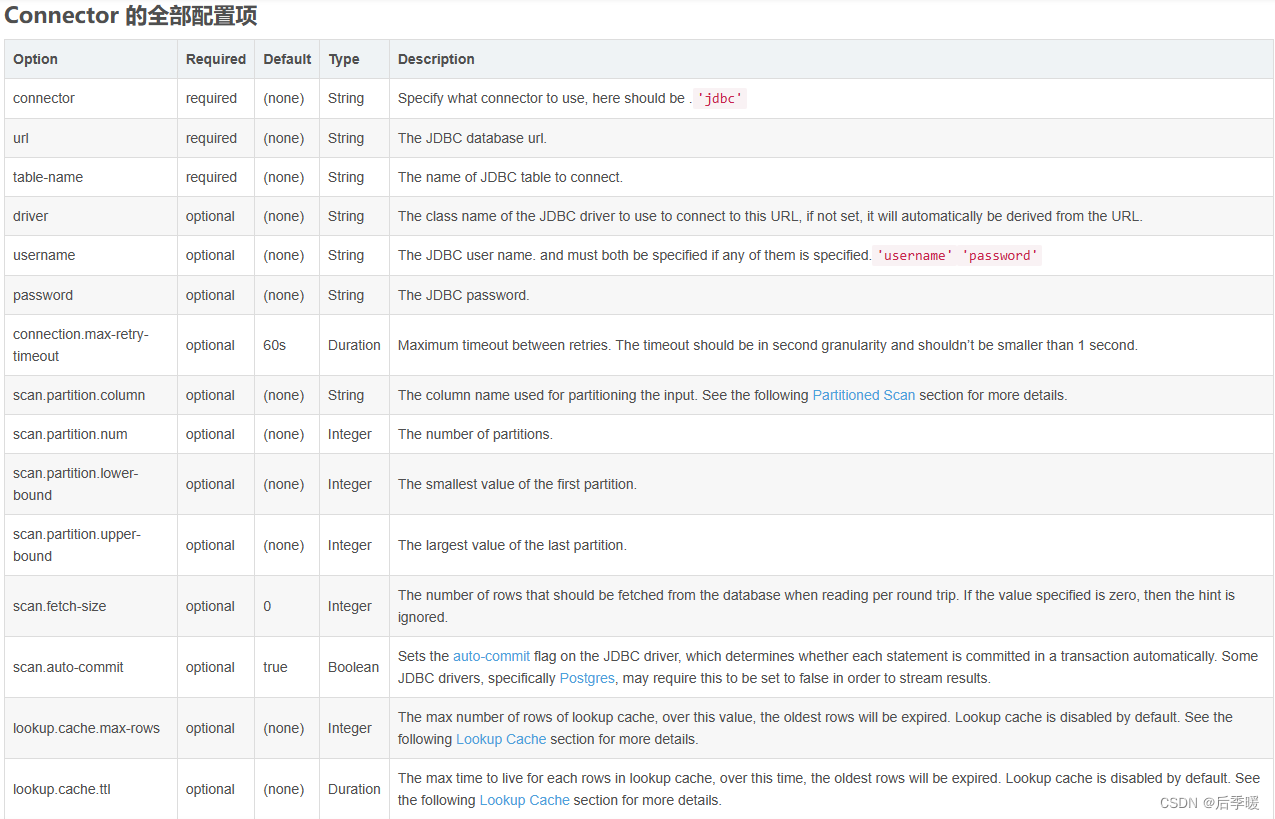
首先我们看到flinkcdc的connector对应的全部配置项
配置项来源:Flink中的JDBC SQL Connector_flink jdbc_江畔独步的博客-CSDN博客

lookup.cache.max.row参数的解释:look up维表的缓存最大行数
具体解释:
在流式计算中,维表是一个很常见的概念,一般用于sql的join中,对流式数据进行数据补全,比如我们的source stream是来自日志的订单数据,但是日志中我们只是记录了订单商品的id,并没有其他的信息,但是我们把数据存入数仓进行数据分析的时候,却需要商品名称、价格等等其他的信息,这种问题我们可以在进行流处理的时候通过查询维表的方式对数据进行数据补全。维表一般存储在外部存储中,比如mysql、hbase、redis等等,今天我们以mysql为例,讲讲flink中维表的使用。在flink中提供了一个LookupableTableSource,可以用于实现维表,也就是我们可以通过某几个key列去查询外部存储来获取相关的信息用于补全stream的数据。我们看到,LookupableTableSource有三个方法getLookupFunction:用于同步查询维表的数据,返回一个TableFunction,所以本质上还是通过用户自定义 UDTF来实现的。getAsyncLookupFunction:用于异步查询维表的数据,该方法返回一个对象,isAsyncEnabled:默认情况下是同步查询,如果要开启异步查询,这个方法需要返回true在flink里,我们看到实现了这个接口的主要有四个类,JdbcTableSource,HBaseTableSource,CsvTableSource,HiveTableSource。
今天我们主要以jdbc为例讲讲如何进行维表查询。接下来我们讲一个小例子,首先定义一下stream source,我们使用flink 1.11提供的datagen来生成数据。我们来模拟生成用户的数据,这里只生成的用户的id,范围在1-100之间。然后再创建一个mysql维表信息,最后执行sql查询,流表关联维表,我们看到对于维表中存在的数据,已经关联出来了,对于维表中没有的数据,显示为null,以jdbc为例,我们来看看flink底层是怎么做的。JdbcTableSource#isAsyncEnabled方法返回的是false,也就是不支持异步的查询,所以进入JdbcTableSource#getLookupFunction方法。最终是构造了一个JdbcLookupFunction对象,options是连接jdbc的一些参数,比如user、pass、url等。lookupOptions是一些有关维表的参数,主要是缓存的大小、超时时间等。lookupKeys也就是要去关联查询维表的字段。所以我们来看看JdbcLookupFunction类,这个JdbcLookupFunction是一个TableFunction的子类,一个TableFunction最核心的就是eval方法,在这个方法里,做的主要的工作就是通过传进来的多个keys拼接成sql去来查询数据,首先查询的是缓存,缓存有数据就直接返回,缓存没有的话再去查询数据库,然后再将查询的结果返回并放入缓存,下次查询的时候直接查询缓存。为什么要加一个缓存呢?默认情况下是不开启缓存的,每来一个查询,都会给维表发送一个请求去查询,如果数据量比较大的话,势必会给存储维表的系统造成一定的压力,所以flink提供了一个LRU缓存,查询维表的时候,先查询缓存,缓存没有再去查询外部系统,但是如果有一个数据查询频率比较高,一直被命中,就无法获取新数据了。所以缓存还要加一个超时时间,过了这个时间,把这个数据强制删除,去外部系统查询新的数据。具体的怎么开启缓存呢?我们看下JdbcLookupFunction#open方法也就是说cacheMaxSize和cacheExpireMs需要同时设置,就会构造一个缓存对象cache来缓存数据.这两个参数对应的DDL的属性就是lookup.cache.max-rows和lookup.cache.ttl对于具体的缓存的大小和超时时间的设置,用户需要根据自身的情况来自己定义,在数据的准确性和系统的吞吐量之间做一个权衡。
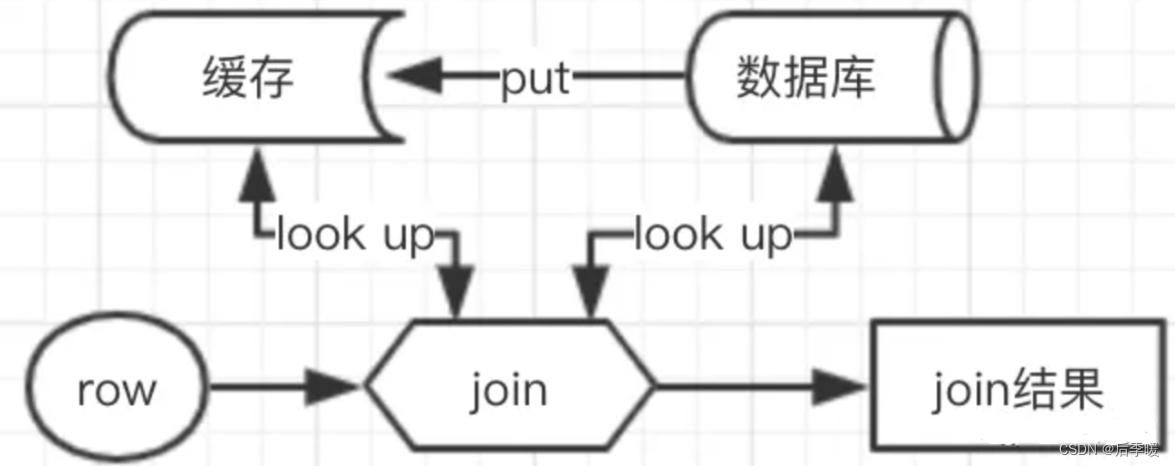
总结就是,防止一直访问维度表,查完一次后会将数据先放在缓存中,然后查缓存,但是这样的话维度表更新了就可能查不到更新后的数据,所以用max rows、ttl来控制
还有三个参数,可能有些同学也有疑问:

其实也很好理解 就是比如说hbase的数据不都是写到memstore缓存起来 然后达到一定数量以后再flush一次写入storeFile嘛 这边的max-rows就是最大多少行 然后flush interval是间隔时间(到了时间 不管你多少行 都要写入了) retries:写入失败的重试次数