1、CDC 简介
1.1、什么是CDC
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1.2、CDC的种类
CDC 主要分为基于查询和基于 Binlog 两种方式,我们主要了解一下这两种之间的区别:
| 介绍 | 基于查询的 CDC | 基于 Binlog 的 CDC |
|---|---|---|
| 开源产品 | Sqoop、Kafka JDBC Source | Canal、Maxwell、Debezium |
| 执行模式 | Batch | Streaming |
| 是否可以捕获所有数据变化 | 否 | 是 |
| 延迟性 | 高延迟 | 低延迟 |
| 是否增加数据库压力 | 是 | 否 |
1.3、Flink-CDC
Flink CDC 是一个独立的开源项目,项目代码托管在 GitHub 上。Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
开源地址:https://github.com/ververica/flink-cdc-connectors
Flink CDC 技术的核心是支持将表中的全量数据和增量数据做实时一致性的同步与加工,让用户可以方便地获每张表的实时一致性快照。比如一张表中有历史的全量业务数据,也有增量的业务数据在源源不断写入,更新。Flink CDC 会实时抓取增量的更新记录,实时提供与数据库中一致性的快照,如果是更新记录,会更新已有数据。如果是插入记录,则会追加到已有数据,整个过程中,Flink CDC 提供了一致性保障,即不重不丢。
从广义的概念上讲,能够捕获数据变更的技术, 我们都可以称为 CDC 技术。通常我们说的 CDC 技术是一种用于捕获数据库中数据变更的技术。CDC 技术应用场景也非常广泛,包括:
数据分发,将一个数据源分发给多个下游,常用于业务解耦、微服务。
数据集成,将分散异构的数据源集成到数据仓库中,消除数据孤岛,便于后续的分析。
数据迁移,常用于数据库备份、容灾等。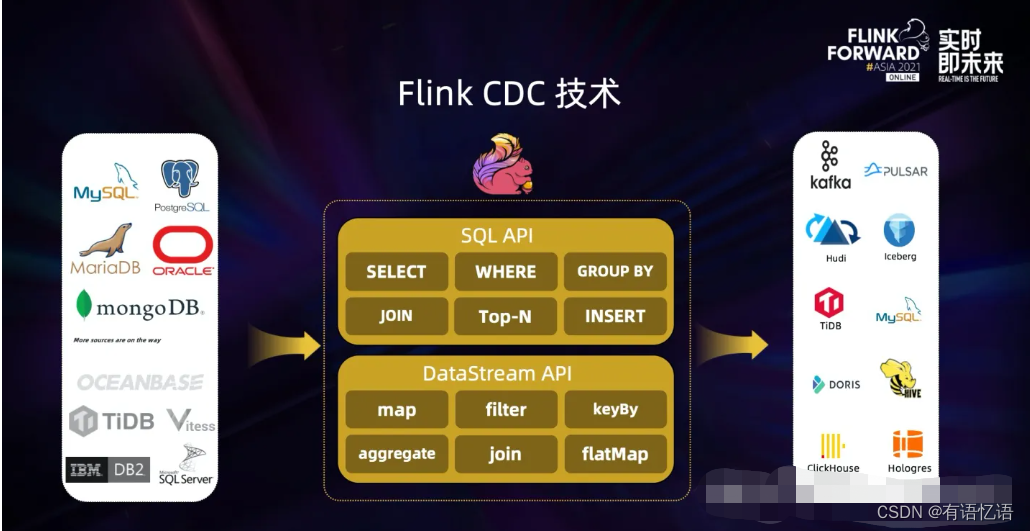
Flink CDC 基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
目前,Flink CDC 的上游已经支持了 MySQL、MariaDB、PG、Oracle、MongoDB 等丰富的数据源,对 Oceanbase、TiDB、SQLServer 等数据库的支持也已经在社区的规划中。
Flink CDC 的下游则更加丰富,支持写入 Kafka、Pulsar 消息队列,也支持写入 Hudi、Iceberg 等数据湖,还支持写入各种数据仓库。
同时,通过 Flink SQL 原生支持的 Changelog 机制,可以让 CDC 数据的加工变得非常简单。用户可以通过 SQL 便能实现数据库全量和增量数据的清洗、打宽、聚合等操作,极大地降低了用户门槛。 此外, Flink DataStream API 支持用户编写代码实现自定义逻辑,给用户提供了深度定制业务的自由度。
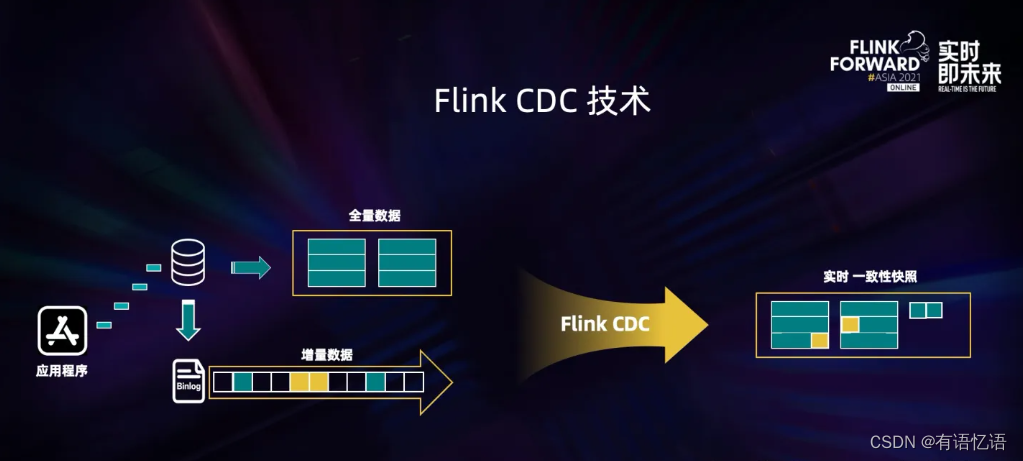
Flink CDC 技术的核心是支持将表中的全量数据和增量数据做实时一致性的同步与加工,让用户可以方便地获每张表的实时一致性快照。比如一张表中有历史的全量业务数据,也有增量的业务数据在源源不断写入,更新。Flink CDC 会实时抓取增量的更新记录,实时提供与数据库中一致性的快照,如果是更新记录,会更新已有数据。如果是插入记录,则会追加到已有数据,整个过程中,Flink CDC 提供了一致性保障,即不重不丢。
那么 Flink CDC 技术能给现有的数据入仓入湖架构带来什么样的改变呢?我们可以先来看看传统数据入仓的架构。

在早期的数据入仓架构中,一般会每天 SELECT 全量数据导入数仓后再做离线分析。这种架构有几个明显的缺点:
- 1.每天查询全量的业务表会影响业务自身稳定性。
- 2.离线天级别调度的方式,天级别的产出时效性差。
- 3.基于查询方式,随着数据量的不断增长,对数据库的压力也会不断增加,架构性能瓶颈明显。
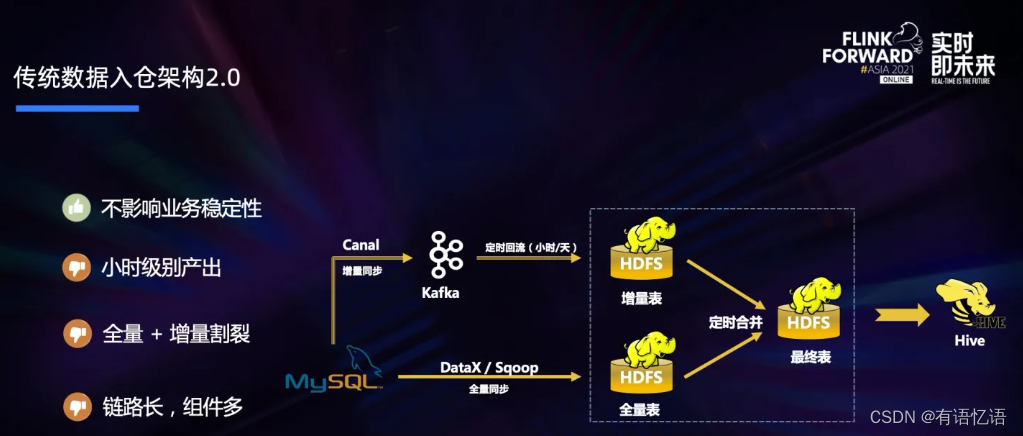
到了数据仓库的 2.0 时代,数据入仓进化到了 Lambda 架构,增加了实时同步导入增量的链路。整体来说,Lambda 架构的扩展性更好,也不再影响业务的稳定性,但仍然存在一些问题:
- 1.依赖离线的定时合并,只能做到小时级产出,延时还是较大;
- 2.全量和增量是割裂的两条链路;
- 3.整个架构链路长,需要维护的组件比较多,该架构的全量链路需要维护 DataX 或 Sqoop 组件,增量链路要维护 Canal 和 Kafka 组件,同时还要维护全量和增量的定时合并链路。

对于传统数据入仓架构存在的问题,Flink CDC 的出现为数据入湖架构提供了一些新思路。借助 Flink CDC 技术的全增量一体化实时同步能力,结合数据湖提供的更新能力,整个架构变得非常简洁。我们可以直接使用 Flink CDC 读取 MySQL 的全量和增量数据,并直接写入和更新到 Hudi 中。
这种简洁的架构有着明显的优势。首先,不会影响业务稳定性。其次,提供分钟级产出,满足近实时业务的需求。同时,全量和增量的链路完成了统一,实现了一体化同步。最后,该架构的链路更短,需要维护的组件更少。
2、Flink CDC 网址
开源地址:https://github.com/ververica/flink-cdc-connectors
官方文档:https://ververica.github.io/flink-cdc-connectors/master
Flink 中文学习网站:https://flink-learning.org.cn
3、运行原理

Flink CDC 的核心特性可以分成四个部分:
- 一是通过增量快照读取算法,实现了无锁读取,并发读取,断点续传等功能。
- 二是设计上对入湖友好,提升了 CDC 数据入湖的稳定性。
- 三是支持异构数据源的融合,能方便地做 Streaming ETL的加工。
- 四是支持分库分表合并入湖。接下来我们会分别介绍下这几个特性。

在 Flink CDC 1.x 版本时,MySQL CDC 存在三大痛点,影响了生产可用性。
一是 MySQL CDC 需要通过全局锁去保证全量和增量数据的一致性,而 MySQL 的全局锁会影响线上业务。
二是只支持单并发读取,大表读取非常耗时。
三是在全量同步阶段,作业失败后只能重新同步,稳定性较差。针对这些问题,Flink CDC 社区提出了 “增量快照读取算法”,同时实现了无锁读取、并行读取、断点续传等能力,一并解决了上述痛点。
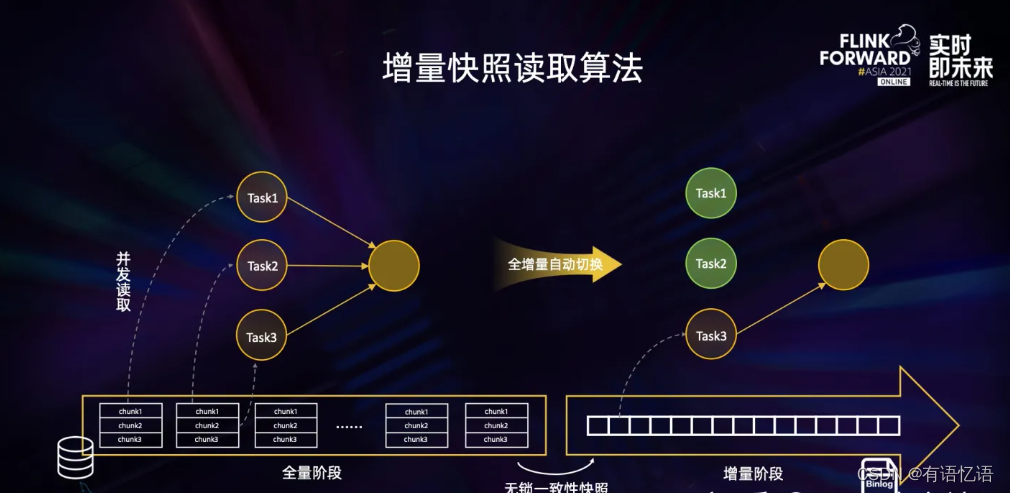
简单来说,增量快照读取算法的核心思路就是在全量读取阶段把表分成一个个 chunk 进行并发读取,在进入增量阶段后只需要一个 task 进行单并发读取 binlog 日志,在全量和增量自动切换时,通过无锁算法保障一致性。这种设计在提高读取效率的同时,进一步节约了资源。实现了全增量一体化的数据同步。这也是流批一体道路上一个非常重要的落地。
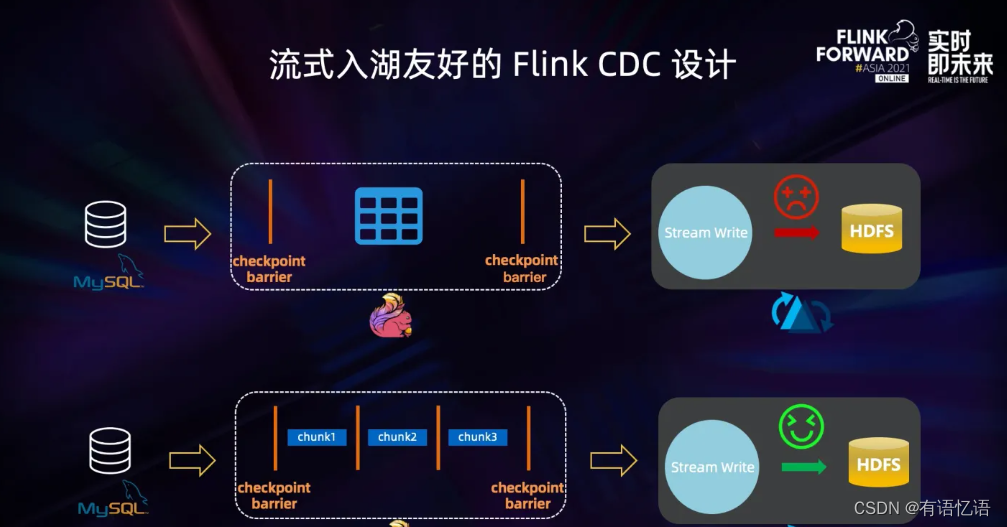
Flink CDC 是一个流式入湖友好的框架。在早期版本的 Flink CDC 设计中,没有考虑数据湖场景,全量阶段不支持 Checkpoint,全量数据会在一个 Checkpoint 中处理,这对依靠 Checkpoint 提交数据的数据湖很不友好。Flink CDC 2.0 设计之初考虑了数据湖场景,是一种流式入湖友好的设计。设计上将全量数据进行分片,Flink CDC 可以将 checkpoint 粒度从表粒度优化到 chunk 粒度,大大减少了数据湖写入时的 Buffer 使用,对数据湖写入更加友好。

Flink CDC 区别于其他数据集成框架的一个核心点,就是在于 Flink 提供的流批一体计算能力。这使得 Flink CDC 成为了一个完整的 ETL 工具,不仅仅拥有出色的 E 和 L 的能力,还拥有强大的 Transformation 能力。因此我们可以轻松实现基于异构数据源的数据湖构建。
在上图左侧的 SQL 中,我们可以将 MySQL 中的实时产品表、实时订单表和 PostgreSQL 中的实时物流信息表进行实时关联,即 Streaming Join,关联后的结果实时更新到 Hudi 中,非常轻松地完成异构数据源的数据湖构建。
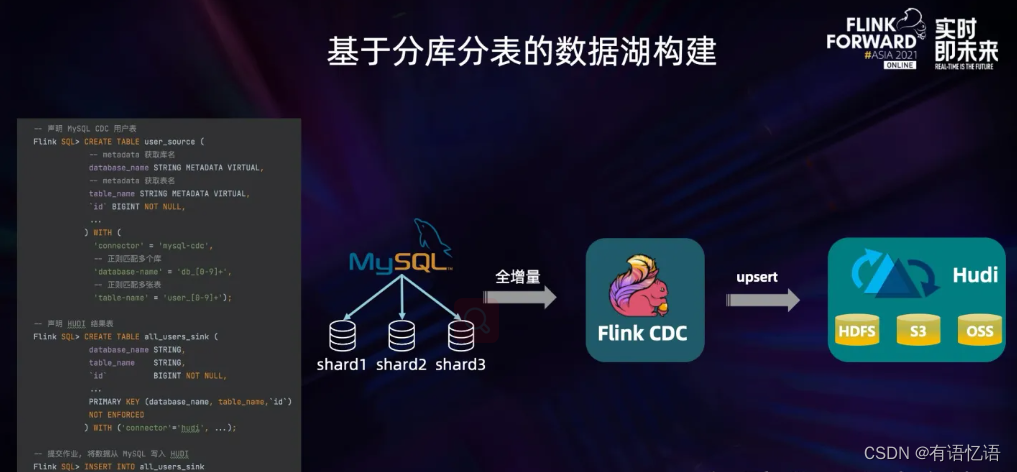
在 OLTP 系统中,为了解决单表数据量大的问题,通常采用分库分表的方式将单个大表进行拆分以提高系统的吞吐量。但是为了方便数据分析,通常需要将分库分表拆分出的表在同步到数据仓库、数据湖时,再合并成一个大表。Flink CDC 可以轻松完成这个任务。
在上图左侧的 SQL 中,我们声明了一张 user_source 表去捕获所有 user 分库分表的数据,我们通过表的配置项 database-name、table-name 使用正则表达式来匹配这些表。并且,user_source 表也定义了两个 metadata 列来区分数据是来自哪个库和表。在 Hudi 表的声明中,我们将库名、表名和原表的主键声明成 Hudi 中的联合主键。在声明完两张表后,一条简单的 INSERT INTO 语句就可以将所有分库分表的数据合并写入 Hudi 的一张表中,完成基于分库分表的数据湖构建,方便后续在湖上的统一分析。
5、简要安装
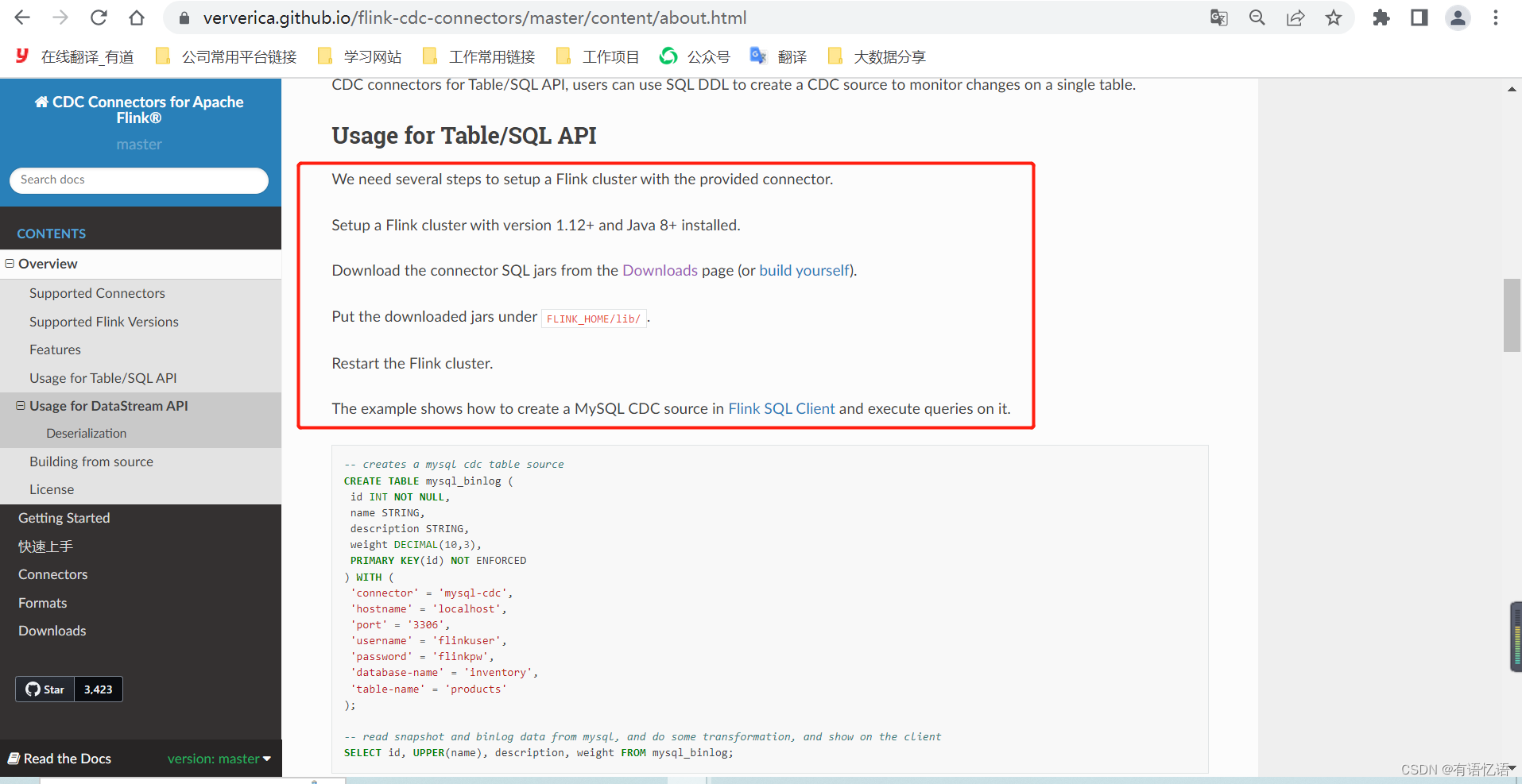
FlinkCDC的安装是基于Flink集群的,只需要将对应的FlinkCDC connector放到FLINK_HOME/lib/下面,再重启Flink集群即可。