嗯…,这个项目我自己调了快一个星期,最终在昨晚把代码跑通了,然后在今天早上又解决了两三个bug,总的来说,bingo思密达~
突然发现调试程序还挺有趣的(ps:当然仅仅是在调出来的那一刻,看见数据在飞奔地运行,畅快=.=)
OK,下面先说一下项目的流程:
首先,当然是文本预处理
输入文本,在将输入文本转化成向量之前,我们需要将标点符号、括号、问号等删去,只留下字母、数字和字符, 同时将大写字母转化为小写,去除停用词。

效果如下图

然后就是将文本转化为词向量(即汉字要转化为计算机能识别的数字类(矩阵啥的))
在将深度学习运用于文本情感分析的过程中,我们需要考虑网络模型的输入数据的形式。在其他例子中,卷积神经网络(CNN)使用像素值作为输入,logistic回归使用一些可以量化的特征值作为输入,强化学习模型使用奖励信号来进行更新。通常的输入数据是需要被标记的标量值。当我们处理文本任务时,可能会想到利用这样的数据管道。
但是,这样的处理方式存在着很多问题。我们不能像点积或者反向传播那样在一个字符串上执行普通的运算操作。所以在这里我们不能将字符串作为输入,而是需要将文本转换成计算机可识别的格式,由于计算机只能识别数字,因此我们可以将文本中的每一个词都转化为一个向量,也称作词向量。词向量是用一个向量的形式表示文本中的一个词,通过这种转化方式就能采用机器学习来把任何输入量化成我们需要的数值表示,然后就可以充分利用计算机的计算能力,计算得出最终想要的结果,保证了操作的可行性。

如图所示,我们可以将上面的这段文本输入数据转化成一个 16*D 的输入矩阵。
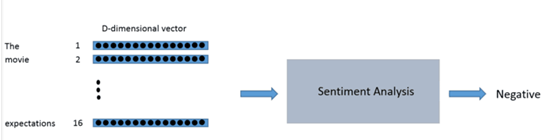
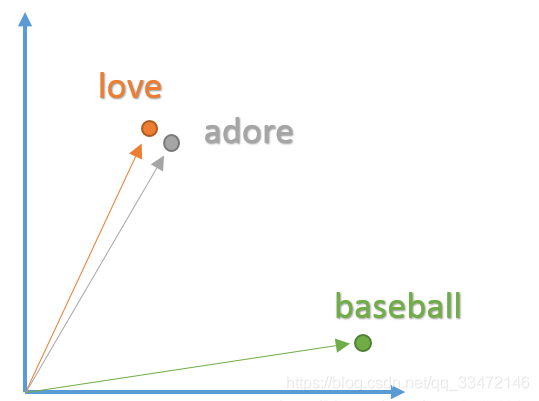
我们希望创建这种词向量的方式是可以表示单词及其在上下文中意义的。例如,我们希望单词 “love” 和 “adore” 这两个词在向量空间中是有一定的相关性的,因为他们的意思相似,而且都在类似的上下文中使用,因此他们的空间相距距离会相对较小。而“love”、“adore”这两个单词与单词“baseball”的意思有很大的不同,词性也不相同,那么“love”、“adore”这两个单词的向量与单词“baseball”的向量相距距离就会相对较大。单词的向量表示也被称之为词嵌入。
特征提取:
为了得到这些词嵌入,我们采用一个很著名的模型 “Word2Vec”。“Word2Vec”是近几年很火的算法,它通过神经网络机器学习算法来训练N-gram 语言模型,并在训练过程中求出word所对应的vector的方法。它是将词表征为实数值向量的一种高效的算法模型,其利用深度学习的思想,可以通过训练,把对文本内容的处理简化为 K 维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似。在这个模型中,每个词的词向量是根据上下文的语境来进行推断的,如果两个词在上下文的语境中可以被互换,那么这就表示这两个词的意思相似,词性相似,那么他们的词向量中相距距离就非常近。在自然语言中,上下文的语境对分析词语的意义是非常重要的。
简单来说,Word2Vec这个模型的作用就是从一大堆句子(以 Wikipedia 为例)中为每个独一无二的单词进行建模,并且输出一个唯一的向量,Word2Vec 模型的输出被称为一个嵌入矩阵。该嵌入矩阵将包含训练语料库中每个不同单词的向量。 传统上,嵌入矩阵可以包含超过300万个单词向量。

Word2Vec模型是通过对数据集中的每个句子进行训练,在其上滑动一个固定大小的窗口,并试图预测窗口的中心词,给出其他词。使用损失函数和优化程序,该模型为每个唯一字生成向量。这个训练过程的细节可能会变得有点复杂,所以我们现在要跳过细节,但这里主要的一点是,任何深度学习方法对于NLP任务的输入可能都会有单词向量作为输入。
后面特征提取这一块,应该会将用word2vec提取的方式改为用doc2vec来提取,不过具体修改时间待定,得看我啥时候能将这一操作学会(哈哈哒)。
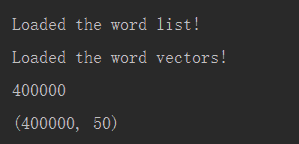
Google 已经帮助我们在大规模数据集上训练出来了 Word2Vec 模型,它包括 1000 亿个不同的词,在这个模型中,谷歌能创建300万个词向量,每个向量维度为 300。在理想情况下,我们将使用这些向量来构建模型,但是因为这个单词向量矩阵太大了(3.6G),因此在此次研究中我们将使用一个更加易于管理的矩阵,该矩阵由 GloVe 进行训练得到。矩阵将包含 400000 个词向量,每个向量的维数为 50。
这里有用到一些.npy文件,是通过glove已经转好的,存为了npy文件。
我们将导入两个不同的数据结构,一个是包含 400000 个单词的 Python 列表,一个是包含所有单词向量值的 400000*50 维的嵌入矩阵。
结果对比:
CNN网络层数包括:卷积层,池化层,全连接层。
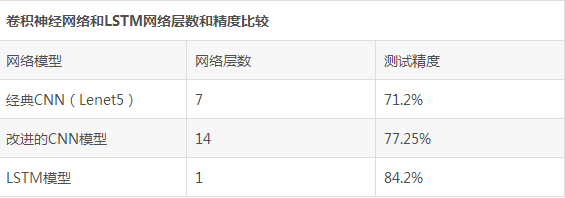
CNN神经网络模型运用于文本情感分析时效果不如LSTM神经网络模型效果好,经典的CNN模型在文本情感分析正确率只有71.2%,而对经典进行改进之后,增加了卷积层和池化层,CNN模型的正确率得到了提高,但正确率也是只有77.25%,仍然比不上只用了一层LSTM网络的正确率高。从结果对比中我们可以知道,CNN不光可以应用于图像处理领域,也能成功有效地对文本信息进行分析,但LSTM在解决文本情感分析的问题时效果要比CNN好。
下面是一些运行结果:
训练数据集的结果
嗯…,训练了800多个数据,发现最高的时候准确率在百分之七十几,但是绝大多数稳定在百分之五十左右,这个准确度还是有点低的,后面加强学习,改进代码,应该可以将准确度提高。(方法推荐:改改epoch可能会提高准确度,模型收敛+准确率)
输出词列表的长度,词向量的维数
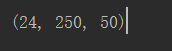
维度的个数
这个项目采用的数据集是IMDB数据集,这个数据集是一个关于电影评论的数据集,在这个数据集上做训练和测试。这个数据集包含 25000 条电影数据,其中 12500 条正向数据,12500 条负向数据。将其中的23000个文本评论作为训练集,将剩下的2000个文本评论作为测试集。

下面为正面评价文本和负面评价文本示例
正面:
负面:


总结:
将CNN与LSTM两种神经网络模型应用到了文本情感分析的问题当中,使用Word2Vec模型及它的子矩阵GloVe来将文本信息进行预处理,转换成了词向量及向量矩阵,使用了IMDB数据集来对模型进行训练,并用TensorFlow进行建模、训练。
路途且长,不留遗憾,Fighting!!!
