常用的推荐算法:

- 基于协同过滤的算法是一种推荐系统算法,它利用用户行为数据(如历史浏览、评分、购买等数据)来发现用户与物品(如电影、书籍、商品等)之间的相似性,从而推荐给用户未曾接触过的物品。
- 基于邻域的协同过滤方法是利用用户或物品之间的相似度来推荐物品,通常包括基于用户的邻域方法和基于物品的邻域方法。
- 基于模型的协同过滤是一种使用机器学习或其他建模技术来预测用户评分的方法。这种方法首先会从用户历史评分数据中学习出一个模型,然后使用这个模型来预测用户对未评分物品的评分。基于模型的协同过滤通常使用的是一些流行的机器学习算法,例如矩阵分解、神经网络、决策树等。这些算法可以从用户的历史评分数据中学习出一些隐含的因素或特征,这些因素或特征可以帮助我们更好地理解用户的兴趣和偏好。与基于邻域的方法相比,基于模型的协同过滤通常需要更多的计算资源和时间来训练模型,但它可以处理稀疏数据和大规模数据集,并且在推荐准确度上通常有更好的表现。
- 隐语义模型(Latent Semantic Model)是一种基于矩阵分解的技术,它可以将用户和物品的特征表示成潜在的低维度向量,从而捕捉到它们之间的潜在关系。这种技术通常用于解决稀疏数据集中的推荐问题,例如电影评分数据集中的用户电影评分。
- 矩阵分解:我们通过将用户和物品的特征矩阵分解为两个低维度的矩阵,即用户矩阵和物品矩阵。这两个矩阵可以相乘得到原始矩阵的近似值,这种方法被称为矩阵分解。通过将特征矩阵分解成低维矩阵,我们可以将高维度的特征表示成低维度的潜在向量,从而能够更好地捕捉到用户和物品之间的关系。具体来说,我们可以通过优化一个损失函数来学习这些潜在向量,使得它们在特征空间中的点积与原始评分数据的误差最小化。在学习完成后,我们可以使用学习到的用户和物品向量来计算用户对物品的评分,进而进行推荐。
- LDA是一种文本主题模型,它是一种非监督学习算法,用于从大量文档中发现潜在的主题,并分析它们之间的关系。在LDA模型中,每个文档被表示为一组主题的分布,每个主题又被表示为一组单词的分布。通过对文档中的单词进行统计,可以计算出每个单词属于每个主题的概率,从而得到文档中每个主题的分布。LDA模型被广泛应用于文本分析、信息检索、推荐系统等领域。
- SVM (Support Vector Machine)是一种监督学习算法,主要用于分类和回归问题。在分类问题中,SVM尝试构建一个将数据点映射到不同类别的最优超平面。超平面被定义为在n维空间中的一个(n-1)维子空间,它可以最大程度地将不同类别的数据点分开。在SVM中,对于每个数据点,算法会尝试找到一个向量(即支持向量),它们距离超平面最近,并且支持向量与超平面之间的距离被最大化。这个距离被称为间隔(margin),它是SVM分类器的一个关键因素。
补充:
监督学习是指在给定一组有标签的训练数据的情况下,训练一个模型,使其能够预测未标记数据的标签。在监督学习中,训练数据的标签信息用于指导模型的学习过程,因此该算法被称为监督学习。
非监督学习是指在没有标签信息的情况下,从给定的数据集中学习数据的内在结构和特征。在非监督学习中,模型只能通过观察数据本身来发现数据中的潜在模式和结构。因此该算法被称为非监督学习。
矩阵分解理论理解:
矩阵分解算法将mxn维的共现矩阵R分解为mxk维的用户矩阵U和kxn维的物品矩阵V相乘的形式。其中 m 是用户数量,n 是物品数量,k是隐向量的维度。k 的大小决定了隐向量表达能力的强弱。k 的取值越小,隐向量包含的信息越少,模型的泛化程度越高;反之,k 的取值越大,隐向量的表达能力越强但泛化程度相应降低。此外,k 的取值还与矩阵分解的求解复杂度直接相关。
我们下面拿一个音乐评分的例子来具体看一下隐特征矩阵的含义。 假设每个用户都有自己的听歌偏好, 比如A喜欢带有小清新的, 吉他伴奏的, 王菲的歌曲,如果一首歌正好是王菲唱的,并且是吉他伴奏的小清新, 那么就可以将这首歌推荐给这个用户。 也就是说是小清新,吉他伴奏,王菲这些元素连接起了用户和歌曲。 当然每个用户对不同的元素偏好不同, 每首歌包含的元素也不一样, 所以我们就希望找到下面的两个矩阵:

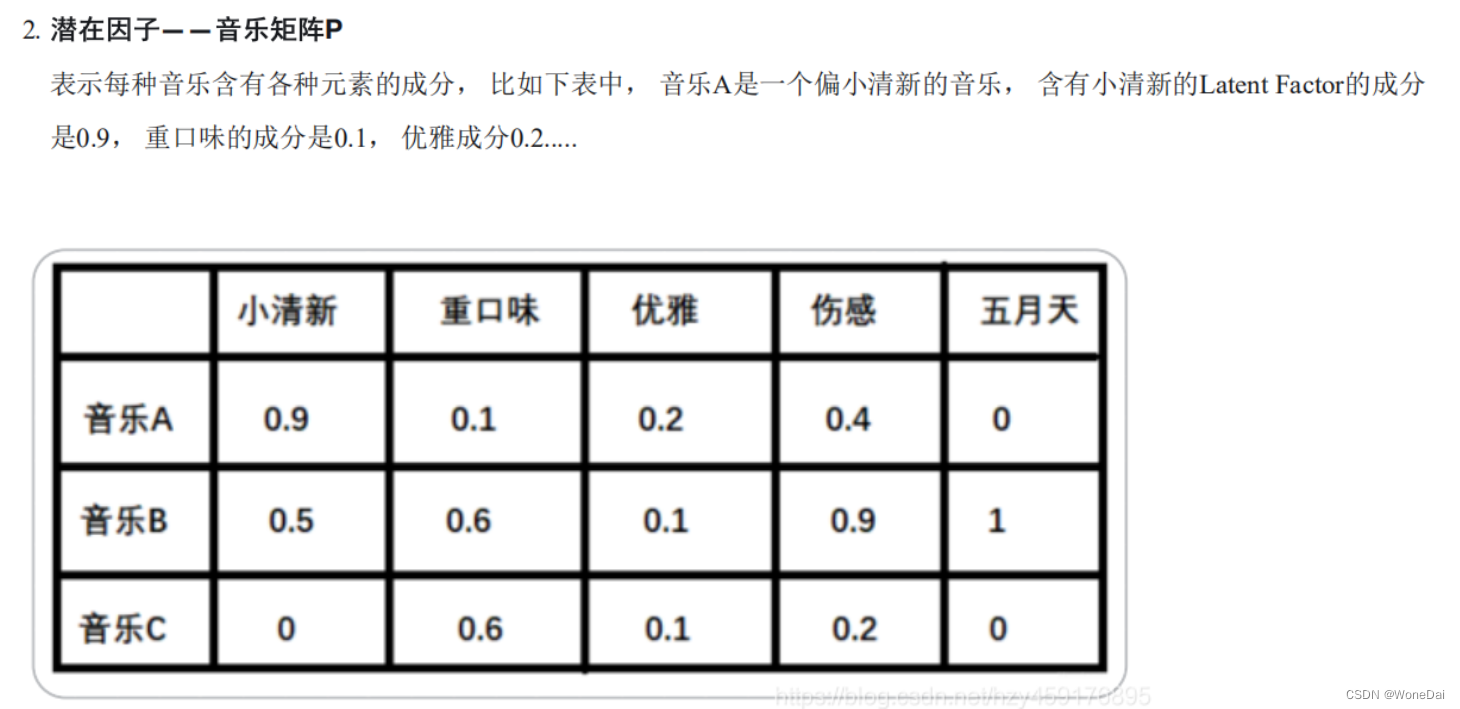



(1) 特征值分解(Eigen Decomposition)
特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵,那这也是后来又引入了奇异值分解的原因之一。
(2) 奇异值分解(Singular Value Decomposition,SVD)

奇异值分解的缺点
1、传统的SVD分解,会要求原始矩阵是密的,而我们这里的这种矩阵一般情况下是非常稀疏的,如果想用奇异值分解,就必须对缺失的元素进行填充,而一旦补全,空间复杂度就会非常高,且补的不一定对。
2、SVD分解计算复杂度非常高,而我们的用户-物品矩阵非常大,所以基本上无法使用。传统奇异值分解也不适用于解决大规模稀疏矩阵的矩阵分解问题。因此,梯度下降法成了进行矩阵分解的主要方法。
矩阵分解算法原理:


1、首先先初始化这两个参数矩阵U和V
2、通过两个隐向量乘积得到预测值pred
3、根据label和pred计算损失
4、通过梯度下降的方式,更新两个隐向量的值
5、未评过分的那些样本当做测试集,通过两个隐向量就可以得到测试集的label值这样就填充完了矩阵,下一步就可以进行推荐了
矩阵分解算法的发展进化参考下链接:
矩阵分解在协同过滤推荐算法中的应用 - 刘建平Pinard - 博客园 (cnblogs.com)![]() https://www.cnblogs.com/pinard/p/6351319.html
https://www.cnblogs.com/pinard/p/6351319.html
算法具体过程介绍:
矩阵P(n,K)表示n个user和K个特征之间的关系矩阵,这K个特征是一个中间变量,矩阵Q(K,m)的转置是矩阵Q(m,K),矩阵Q(m,K)表示m个item和K个特征之间的关系矩阵,这里的K值是自己控制的,可以使用交叉验证的方法获得最佳的K值。为了得到近似的R(n,m),必须求出矩阵P和Q。
1、首先令 ![]()
2、损失函数:使用原始的评分矩阵 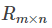 与重新构建的评分矩阵
与重新构建的评分矩阵 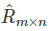 之间的误差的平方作为损失函数,即:
之间的误差的平方作为损失函数,即:
如果R(i,j)已知,则R(i,j)的误差平方和为:
![]()
最终,需要求解所有的非“-”项的损失之和的最小值:
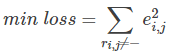
3、 使用梯度下降法获得修正的p和q分量:
求解梯度:
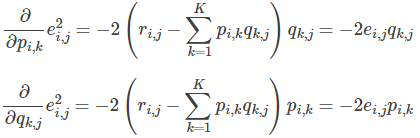
更新变量:
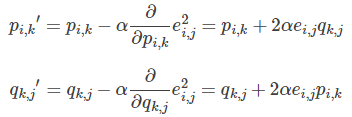
4. 不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
【加入正则项的损失函数求解】
1、首先令 ![]()
2、
通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入  正则的损失函数为:
正则的损失函数为:
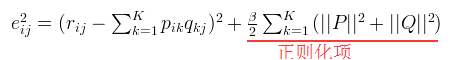
3、使用梯度下降法获得修正的p和q分量:
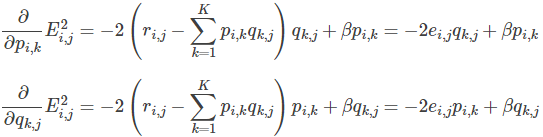

4、不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
BiasSVD(消除用户和物品打分的偏差)
在推荐系统中,偏置项(bias)是用来调整用户评分和物品评分的,因为每个用户和每个物品都有自己的特性和倾向性,这些特性会导致用户给出的评分总体偏高或偏低,物品也可能得到更多或更少的评分。因此,为了准确地预测用户的评分,我们需要根据用户和物品的特性进行调整,这就是偏置项的作用。偏置项可以用来减少整体的平均值或者调整特定用户或物品的评分。在推荐系统中,偏置项通常会加到预测的评分中,以提高预测的准确性。为了消除用户和物品打分的偏差,常用的做法是在矩阵分解时加入用户和物品的偏差向量。
目标函数(损失函数+正则项)

梯度下降

梯度更新

实例代码
1、自编代码(正则化)
import matplotlib.pyplot as plt
from math import pow
import numpy
def matrix_factorization(R,P,Q,K,steps=5000,alpha=0.0002,beta=0.02):
Q=Q.T # .T操作表示矩阵的转置
result=[]
for step in range(steps):
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j]>0:
eij=R[i][j]-numpy.dot(P[i,:],Q[:,j]) # .dot(P,Q) 表示矩阵内积
for k in range(K):
P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k])
Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j])
eR=numpy.dot(P,Q)
e=0
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j]>0:
e=e+pow(R[i][j]-numpy.dot(P[i,:],Q[:,j]),2)
for k in range(K):
e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2))
result.append(e)
if e<0.001:
break
return P,Q.T,result
if __name__ == '__main__':
R=[
[5,3,0,1],
[4,0,0,1],
[1,1,0,5],
[1,0,0,4],
[0,1,5,4]
]
R=numpy.array(R)
N=len(R)
M=len(R[0])
K=2
P=numpy.random.rand(N,K) #随机生成一个 N行 K列的矩阵
Q=numpy.random.rand(M,K) #随机生成一个 M行 K列的矩阵
nP,nQ,result=matrix_factorization(R,P,Q,K)
print("原始的评分矩阵R为:\n",R)
R_MF=numpy.dot(nP,nQ.T)
print("经过MF算法填充0处评分值后的评分矩阵R_MF为:\n",R_MF)
#-------------损失函数的收敛曲线图---------------
n=len(result)
x=range(n)
plt.plot(x,result,color='r',linewidth=3)
plt.title("Convergence curve")
plt.xlabel("generation")
plt.ylabel("loss")
plt.show()2、调用surprise库SVD
from surprise import Dataset
from surprise import Reader
from surprise import accuracy
from surprise import SVD
from surprise.model_selection import cross_validate, train_test_split
# 加载数据集
data = Dataset.load_builtin('ml-100k')
# 定义矩阵分解算法
'''
在这个示例中,SVD算法的超参数设置如下:
biased=False 表示不考虑偏置项。
n_epochs=50 表示迭代次数为50次。
lr_all=0.01 表示使用的学习率为0.01。
reg_all=0.02 表示正则化参数为0.02。
init_mean=0 表示对潜在向量的初始化均值为0。
init_std_dev=0.1 表示对潜在向量的初始化标准差为0.1。
'''
'''
SVD算法将矩阵分解为三个矩阵,其中两个是正交矩阵,一个是对角矩阵。
但是在Surprise库中的SVD算法默认只使用两个矩阵来进行分解,即将矩阵分解为用户矩阵和物品矩阵。
'''
algo = SVD(biased=False, n_epochs=50, lr_all=0.01, reg_all=0.02, init_mean=0, init_std_dev=0.1)
# 在数据集上执行交叉验证
'''
这段代码使用交叉验证来评估SVD算法的性能。
它将数据集拆分成5个互斥的折叠,每个折叠都被用作一次验证集,剩余的部分作为训练集。
算法在每个折叠上运行一次,并计算RMSE和MAE等度量值。
最终,它输出每个折叠的度量值,并计算平均值和标准差。
'''
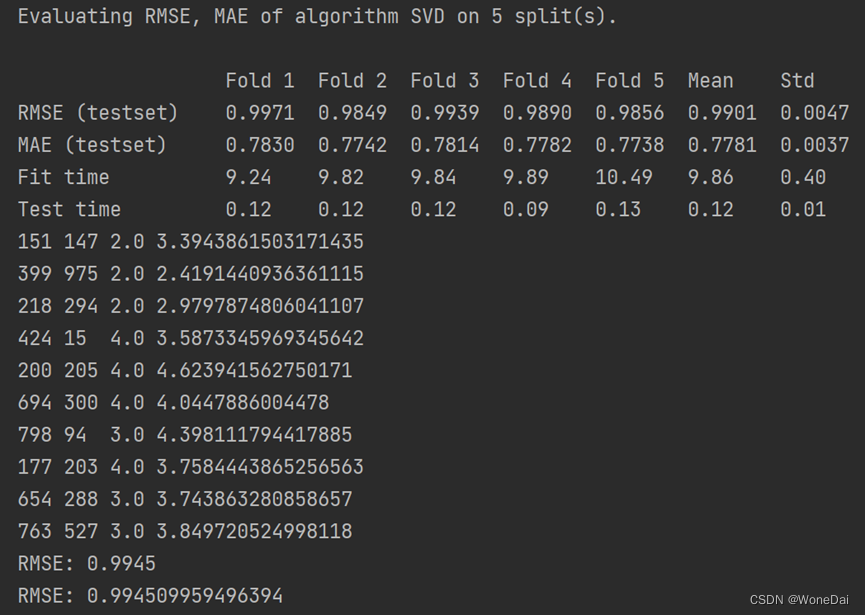
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
# 划分数据集
'''
test_size=.25表示将数据集按照3:1的比例划分成训练集和测试集,即测试集占25%
'''
trainset, testset = train_test_split(data, test_size=.25)
# 训练算法并预测评分
algo.fit(trainset)
predictions = algo.test(testset)
# 输出前10个预测结果
for i, (uid, iid, true_r, est, _) in enumerate(predictions[:10]):
print('{}\t{}\t{}\t{}'.format(uid, iid, true_r, est))
# 计算RMSE
'''
第一个RMSE表示交叉验证的结果,它是在整个数据集上进行5折交叉验证得到的平均RMSE。
第二个RMSE是基于随机划分得到的训练集和测试集计算得到的RMSE,它是在模型训练后用测试集数据计算的。
'''
print('RMSE:', accuracy.rmse(predictions))
from surprise import Dataset
from surprise import Reader
from surprise import accuracy
from surprise import SVD
from surprise.model_selection import cross_validate, train_test_split
# 加载数据集
data = Dataset.load_builtin('ml-100k')
# 划分数据集
trainset, testset = train_test_split(data, test_size=.25)
# 定义矩阵分解算法
algo = SVD(biased=False, n_epochs=50, lr_all=0.01, reg_all=0.02, init_mean=0, init_std_dev=0.1)
# 在训练集上训练算法
algo.fit(trainset)
# 在测试集上测试算法并计算RMSE
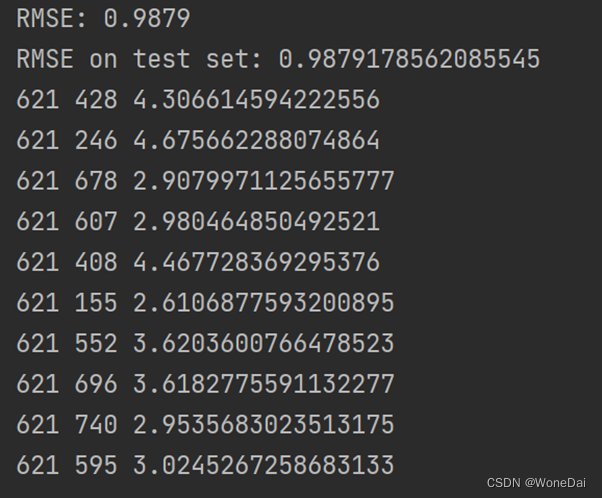
predictions = algo.test(testset)
rmse = accuracy.rmse(predictions)
print('RMSE on test set:', rmse)
# 生成所有用户未评分的物品
'''
对于每个用户,trainset.build_anti_testset() 方法会找出该用户没有评分的物品,
然后为每个用户-物品对创建一个新的元组,其中包含用户 ID,物品 ID 和默认评分
(通常是训练集中所有评分的平均值或中位数)。
'''
anti_testset = trainset.build_anti_testset()
# 对所有用户未评分的物品进行预测
predictions = algo.test(anti_testset)
# 输出前10个预测结果
for i, (uid, iid, _, est, _) in enumerate(predictions[:10]):
print('{}\t{}\t{}'.format(uid, iid, est))
参考文章: