参考:
Serving Runtimes - KServe Documentation Website
模型推理服务化:如何基于Triton开发自己的推理引擎? - 知乎
GitHub - openai/triton: Development repository for the Triton language and compiler
前言
ServingRuntime(在中文语境里,笔者经常把它叫做“推理运行时”)是KServe的一个核心概念。本文主要讲解ServingRuntime的概念,并重点介绍 Triton 模型服务化框架。
概念讲解
ServingRuntime,笔者对其解释为“加载模型文件、运行推理服务的容器环境”。大白话说 就是运行环境里要有能加载模型文件的代码,实际的承载也就是SDK、编译器/解释器这些具体的东西。
Kserve提供了以下几种开箱即用(out-of-the-box)的ServingRuntime,供用户进行使用:

Triton 简介
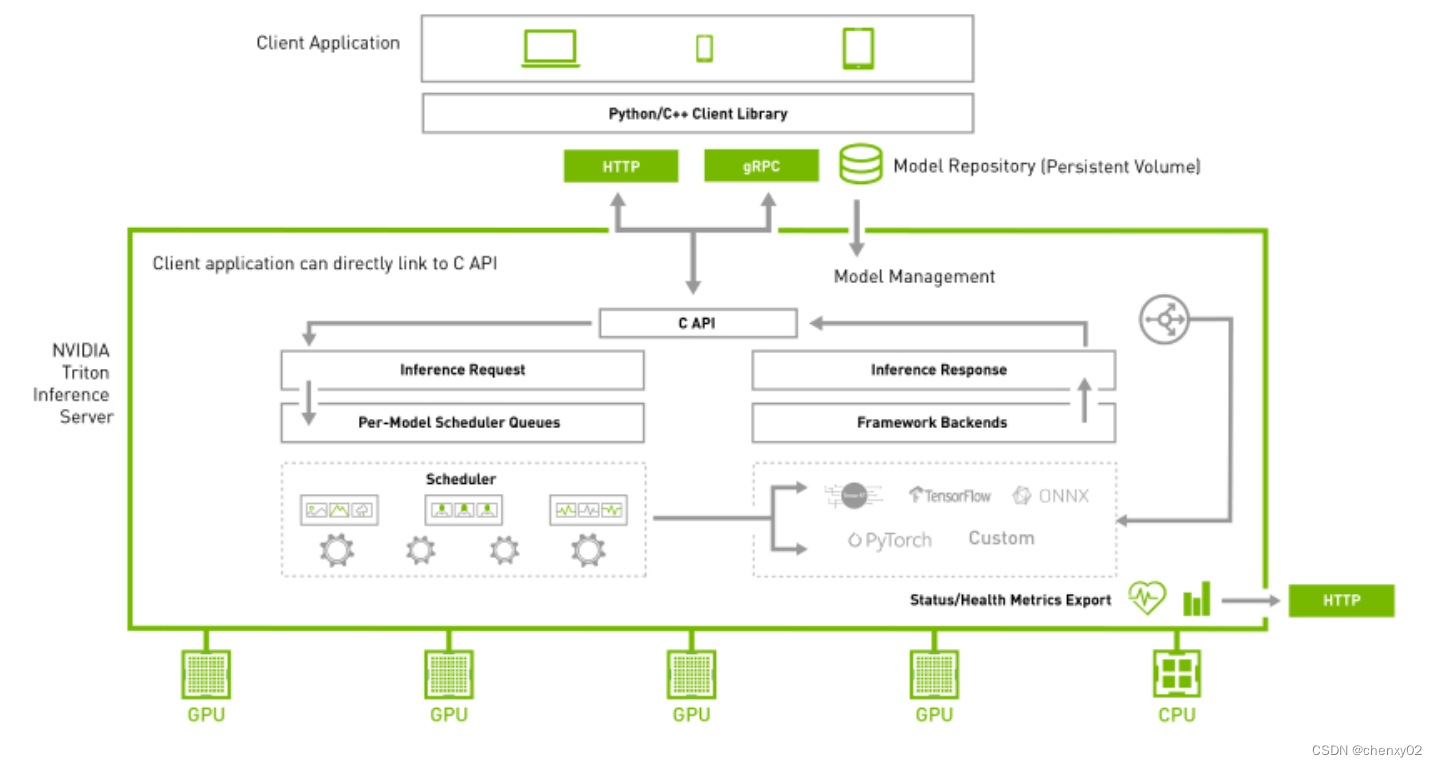
1、Triton接入层: 图中C API部分。可以看到Triton支持HTTP/REST和GRPC协议。
2、模型仓库:中Model Repository部分。按照Triton的官方文档所述,模型仓库可以是本地的持久化存储介质(磁盘),也可以接入Google Cloud Platform或者AWS S3的模型仓库。还需要注意:Triton的模型仓库支持多模型、也支持模型编排。
3、预编排:图中Pre-Model Scheduler Queues部分。笔者理解这块的核心内容就是模型编排:通过解析请求的URL,从模型仓库查询到编排信息,执行模型编排。
4、前向推理计算: 图中的Framework Backends部分。Triton框架支持TensorFlow, TensorRT, PyTorch, ONNX Runtime推理引擎,也支持用户扩展自己的推理引擎,Triton统一把它们称为“Backend”,笔者翻译为“推理引擎”,请注意:每一种框架都是一种Backend(推理引擎)。Backend(推理引擎)实际上就是各个框架的C++ API,不清楚英伟达有没有做底层的优化。需要注意一点:在Triton以开始启动时,模型仓库中的模型就已经被加载到内存或者显存上了;因此,每一次来推理请求的时候,只需要在内存或者显存中遍历一次模型做前向计算即可(这个是推理服务的常规操作,因为模型的加载非常耗时)。
5、结果返回:对应图中Inference Response部分。即把最终结果返回给客户端。
6、最后,来看Status/Health Metrics Export部分,这块就是Triton支持接入Prometheus监控的地方。