1、介绍(Introduction)
这个挑战的主要目标是在现实场景中从许多视觉对象类中识别对象(即不是预先分割的对象)。它本质上是一个监督学习问题,因为它提供了一个标记图像的训练集。已选择的20个对象类为:
Person :person
Animal :bird, cat, cow, dog, horse, sheep
Vehicle :aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor :bottle, chair, dining table, potted plant, sofa, tv/monitor
有三种主要的物体识别比赛:分类、检测和分割,动作分类比赛,以及由ImageNet运行的大规模识别比赛。此外,还有一个关于人体部位识别的比赛。
官方链接 :http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
分类/检测(Classification/Detection)
分类:对于二十个类中的每一个,预测 测试图像中是否存在该类的示例。
检测:从 测试图像中的 20 个目标类。

分割(Segmentation)
分割:生成逐像素的分割,使对象的类别在每个像素可见,否则为“背景”。
动作分类(Action Classification)
动作分类:预测一个人在静止图像中执行的动作。

人体部位
预测每个部分的边界框和标签 人(头、手、脚)。

2、VOC 2012 文件夹介绍
下载后将文件进行解压,解压后的文件目录结构如下所示:
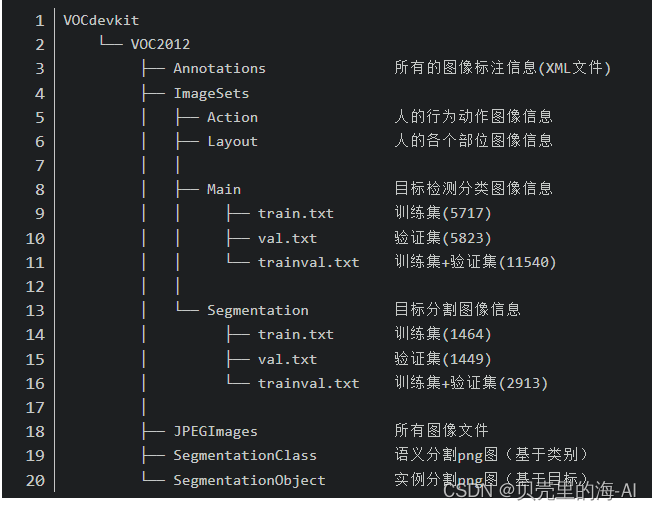
VOC 2012 文件夹下一共包括 5 个子文件夹
1)Annotations
文件为 XML格式 的图片标注信息,里面包含的信息有:图像数据的 名称、地址,目标的种类、位置等 。
size记录了对应图像的宽、高以及channel信息。每一个object代表一个目标,其中的name记录了该目标的名称,pose表示目标的姿势(朝向),truncated表示目标是否被截断(目标是否完整),difficult表示该目标的检测难易程度(0代表简单,1表示困难),bndbox记录了该目标的边界框信息。

2) ImageSets
ImageSets 下有 4 个子文件夹

Action
用于动作分类,包括三个部分(train.txt、trainval.txt、val.txt),对应的动作有 jumping、phoning 等 。
Layout
用于人体部位检测,包括三个部分(train.txt、trainval.txt、val.txt),对应的部位有 head、hand、feet 等 。
Main
用于图像分类 / 检测,包括三个部分(train.txt、trainval.txt、val.txt),一共包括 20 个类别 。
读取对应的txt文件(注意,在Main文件夹里除了train.txt、val.txt和trainval.txt文件外,还有针对每个类别的文件,例如bus_train.txt、bus_val.txt和bus_trainval.txt)。比如使用train.txt中的数据进行训练,那么读取该txt文件,解析每一行。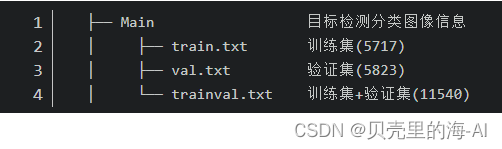
Segmentation
用于图像分割 。
3)JPEGImages
VOC 2012 数据集提供的所有的 .jpg 格式的图片,训练集和测试集一共 17125 张 ,
命名格式:“年份_编号.jpg”,与 1)Annotations 中的标签相对应,图片的像素尺寸不相同 。
4)SegmentationClass
语义分割标注掩模图,一共 2913 张 ,同一物体类别颜色一样,不同物体类别颜色不同 。
- 首先在Segmentarion文件中,读取对应的txt文件。比如使用train.txt中的数据进行训练,那么读取该txt文件,解析每一行,每一行对应一个图像的索引。
- 根据索引在JPEGImages 文件夹中找到对应的图片。还是以2007_000323为例,可以找到2007_000323.jpg文件。

- 根据索引在SegmentationClass文件夹中找到相应的标注图像(.png)。还是以2007_000323为例,可以找2007_000323.png文件。

在语义分割中对应的标注图像(.png)用PIL的Image.open()函数读取时,默认是P模式,即一个单通道的图像。在背景处的像素值为0,目标边缘处用的像素值为255(训练时一般会忽略像素值为255的区域),目标区域内根据目标的类别索引信息进行填充,例如人对应的目标索引是15,所以目标区域的像素值用15填充。
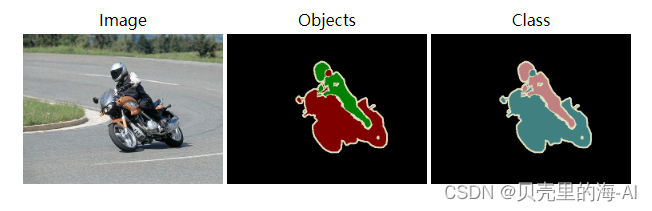
5)SegmentationObject
实例分割标注掩模图,一共2913张 ,同一物体类别和不同物体类别颜色都不同 。
- 首先在Segmentarion文件中,读取对应的txt文件。比如使用train.txt中的数据进行训练,那么读取该txt文件,解析每一行,每一行对应一个图像的索引。
- 根据索引在JPEGImages 文件夹中找到对应的图片。这里以2007_000032为例,可以找到2007_000032.jpg文件,如下图示。

- 再根据索引在SegmentationObject文件夹中找到相应的标注图像(.png)。还是以2007_000032为例,可以找到2007_000032.png文件。

注意,在实例分割中对应的标注图像(.png)用PIL的Image.open()函数读取时,默认是P模式,即一个单通道的图像。在背景处的像素值为0,目标边缘处或需要忽略的区域用的像素值为255(训练时一般会忽略像素值为255的区域)。
然后在Annotations文件夹中找到对应的xml文件,解析xml文件后会得到每个目标的信息,而对应的标注文件(.png)的每个目标处的像素值是按照xml文件中目标顺序排列的。如下图所示,xml文件中每个目标的序号是与标注文件(.png)中目标像素值是对应的。
参考文章:
https://blog.csdn.net/weixin_45084253/article/details/124332044
https://blog.csdn.net/qq_37541097/article/details/115787033