文章目录
Swin Transformer
Shifted Window 窗口自注意力到全局自注意力,窗口建模到全局建模。
BackBone
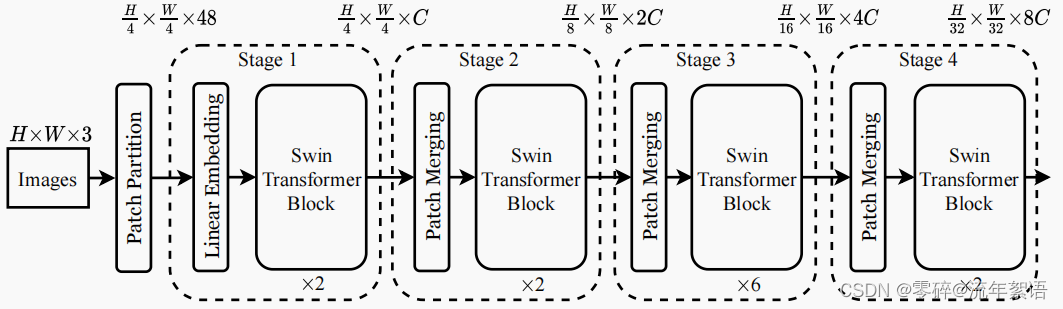
上图为 Swin-Tiny的网络架构图。
- Swin-T: C = 96, layer numbers = {2, 2, 6, 2}
- Swin-S: C = 96, layer numbers ={2, 2, 18, 2}
- Swin-B: C = 128, layer numbers ={2, 2, 18, 2}
- Swin-L: C = 192, layer numbers ={2, 2, 18, 2}
Stage 0
Images:224 * 224 * 3 (H * W * 3)
Patch Partition: 56 * 56 * 48 (H/4 * W/4 * 48)
Stage 1
Linear Embedding:56 * 56 * 96 (H/4 * W/4 * C)。类似于卷积操作。
Swin Transformer Block * 2:3136 * 96。
Stage 2
Patch Merging:28 * 28 * 192 (H/8 * W/8 * 2C)。
Swin Transformer Block * 2:784 * 192。
Stage 3
Patch Merging:14 * 14 * 384 (H/16 * W/16 * 4C)。
Swin Transformer Block * 6:196 * 384 。
Stage 4
Patch Merging:7 * 7 * 768 (H/32 * W/32 * 8C)。
Swin Transformer Block * 2:49 * 768。
Patch Merging 操作
Swin Transformer Blocks 计算单元
- 进入LayerNorm(层归一化),然后进行多头自注意力(W-MSA),进行LayerNorm(层归一化),进行MLP操作
- 进入LayerNorm(层归一化),然后进行移动多头自注意力(SW-MSA),进行LayerNorm(层归一化),进行MLP操作

基于窗口自注意力计算复杂度推导
Multi-head Self-Attention模块(MSA)
Window Multi-head Self-Attention模块(W-MSA)
https://blog.csdn.net/qq_45588019/article/details/122599502
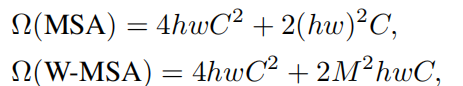
掩码操作
后续……
改进
后续……