CUDA是NVIDIA针对GPU加速计算而开发的编程框架。通过PyTorch可以很方便地使用CUDA,无须过多地改变代码。
一、numpy运算和python运算
使用
numpy
进行矩阵乘法比使用
Python
的效能会提高很多。
import torch
import numpy
# 方形矩阵大小
size = 600
a = numpy.random.rand(size, size)
b = numpy.random.rand(size, size)
使用numpy将两个数列相乘,使用timeeit进行计时:
%%timeit
x = numpy.dot(a,b)直接使用python相乘:
%%timeit
c = numpy.zeros((size,size))
for i in range(size):
for j in range(size):
for k in range(size):
c[i,j] += a[i,k] * b[k,j]
pass
pass比较二者的用时差异:
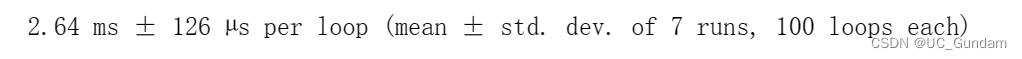
第二个用时到达了3分钟多,没有截屏。
二、GPU上的torch张量
创建一个
GPU
中的张量,并检查数据格式。
x = torch.cuda.FloatTensor([3.5])
x.type()
x.device

三、试验GPU性能
# 将前面的numpy数据转换为cuda格式
aa = torch.cuda.FloatTensor(a)
bb = torch.cuda.FloatTensor(b)开始运算:
%%timeit
cc = torch.matmul(aa, bb)
比之前还快。
四、检查CUDA是否可用的标准代码
# 检查CUDA是否可用
# 如果可用,转换为cuda格式
if torch.cuda.is_available():
torch.set_default_tensor_type(torch.cuda.FloatTensor)
print("using cuda:", torch.cuda.get_device_name(0))
pass
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device