2011年开源的KinectFusion,是第一个使用RGBD相机进行实时稠密三维重建的系统(需要GPU,甚至多个GPU),在当时具有重大开创意义,其所用的地图为TSDF地图,对后续稠密地图的发展有着重大的意义。目前很多动态环境下的实时三维重建系统,都是在KinectFusion或者ElasticFusion基础上扩展的。
实时三维重建技术与SLAM有很大的相关性,不同之处在于,三维重建更关注建图的完整度和精度,而SLAM更关注定位精度。SLAM建图是为了辅助定位,并不太关注地图精度以及稠密程度。
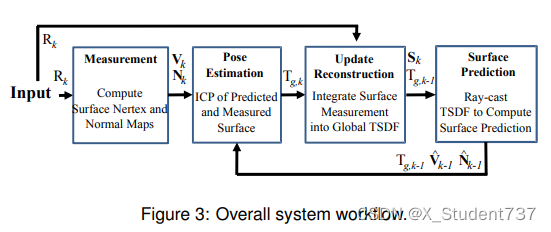
总体架构
参考源码:https://github.com/JingwenWang95/KinectFusion
Kinect Fusion算法整体流程如下:
(1)当k=0时,即对第0帧传感器采集到的深度图,恢复成三维点云,融合到volume地图中。
(2)当k=1、2、···、n时:
Step1:基于上一帧的位姿值,将volume地图投影到上一帧的像素平面上,得到投影的深度图。
Step2:利用上一帧的投影深度图,和当前帧采集到的深度图,ICP匹配计算位姿。
Step3:基于当前帧的位姿,将当前帧传感器采集到的深度图,融合到volume地图中。
一、数据预处理
tum数据集,包含depth文件夹(存储采集到的深度图)、rgb文件夹(存储采集到的rgb图)、depth.txt(存储不同时刻的深度图文件名)、rgb.txt(存储不同时刻的rgb图文件名)、groundtruth.txt(存储不同时刻的位姿真值)。
由于深度图、rgb图、位姿值的传感器的采集频率不同,因此文件数量不同。源码根据采集时刻,记max_difference=0.02,选取最邻近时刻采集到的数据作匹配,存储得到572张深度图、572张rgb图、572个真实位姿。
值得注意的是,tum数据集的真实位姿,是用四元数[tx ty tz qx qy qz qw]形式记录的,默认是c2w形式(从相机坐标系到世界坐标系的位姿变换)。源码中需要将四元数转化为位姿矩阵的形式,存储在raw_poses.npz文件中(默认c2w的位姿矩阵)。
二、超参数设置
data_root:存储数据集的存放路径。
near=0.1:忽略深度值(归一化后)小于0.1的位置,将其深度数值记为-1。
far=5:忽略深度值(归一化后)大于5的位置,将其深度值记为-1。
vol_bound=[-2.5, 2.0, -0.7, 2.7, -0.2, 2.0]:volume地图在三个维度上的边界(最远、最近坐标)。
voxel_size=0.04:volume地图由一系列正方体voxel组成,此处voxel的物理边长设为0.04m。
n_pyramids=3:进行icp匹配时,对图像采用三层金字塔变换,由粗到细迭代。
n_iters=[6, 3, 3]:在三种尺度的缩放图像上,最优化迭代次数设置为6、3、3。
dampings=[1.0e-4, 1.0e-4, 1.0e-2]:三次最优化迭代的高斯牛顿阻尼系数。
n_steps=192:对于渲染过程(volume地图投影到像素平面),每条射线方向均匀采样192个点。
三、数据加载部分
基于数据预处理得到的depth文件夹、rgb文件夹,data_loader部分核心操作如下:
(1)加载每帧的内参矩阵,外参矩阵(c2w格式),分别存储在self.K_all、self.c2w_all中。
(2)读取depth深度图,除以5000归一化到某个尺度,这样可以使得深度值都在1附近,后续求解起来更加稳定。将depth数值小于0.2或大于5的位置全部忽略,深度值设置为-1,代表无效值。
(3)原始图像尺寸为[480, 640],下采样至[120, 160],以减少计算资源消耗,同时内参系数也要做相应放缩调整。
四、点云融合部分
将当前帧点云和volume地图融合的难点是,如何将点云中的每个三维坐标点,都准确的对应到volume地图的指定voxel上? 这里为了避免多个三维坐标点同属于一个voxel的情况,反其道而行,将volume的每个voxel投影至像素平面,由此获得每个voxel的sdf值。
Step1:将volume地图中每个voxel的世界坐标,投影到当前帧的像素平面,得到对应索引位置。
Step2:只保留视锥内部的所有voxel,排除所有无效投影的三维voxel坐标。
(即投影到像素平面的位置在[0, img_w]、[0, img_h]之外)
Step3:计算这些有效位置的voxel的depth_diff值,即传感器测量的深度值减去voxel中的实际z值。
Step4:对depth_diff值做截断,得到有效位置的sdf值(截断在[-1, 1]之间,这里以三个voxel_size值为标准)。同时将这些有效位置的权重w全取1。
Step5:将当前帧点云构建出的tsdf地图,与旧的volume进行加权更新。此处要更新三个值:sdf值(记录物体表面距离)、权重(每个voxel被多次观测所提升的权重)、rgb值。由权值更新公式可以看出,某些voxel如果被多次观测,它旧的权值就会越来越大,历史累积下来的影响也会更大。
这个更新过程也很大程度上解决了我之前一直百思不得其解的问题,当融合不同帧的点云时,往往会有很多位置是重合的,此时该如何处理这种重叠伪影的情况呢?借助volume和voxel即可完美解决,利用权重更新公式,哪怕某个场景被多次观测到,它的点云累积点也不会变密集,始终由一个特定的voxel加权融合。
五、render_mode部分
给定一个相机位姿,将volume地图投影至像素平面,生成当前位姿下的rgb图像和depth深度图。
难点在于,此时三维场景是完整的(投影时候可能存在视角遮挡的情况),如何处理才能使得可见的点云部分准确投影到像素平面,而不可见的部分不进行投影?
Step1:根据图像索引位置,投影生成每个像素点对应的三维坐标,即射线向量(投影到归一化平面)。ray_d表示每条射线在世界坐标系下的方向向量(乘上了c2w旋转矩阵),ray_o表示每条射线在世界坐标系下的起始点(即w2c相机位姿的t分量)。
Step2:从最近距离near=0.1到最远距离far=5,均匀采样192个样本点,得到[120, 160, 192, 3]维度射线样本的三维坐标。
Step3:剔除不在volume地图内部的射线样本点,得到[1609083, 3]个射线样本的三维坐标。
Step4:基于已经构建好的volume点云地图,对[1609083, 3]个射线样本的sdf值进行三次插值拟合,将得到的sdf值记录在[120, 160, 192]数组中。
Step5:通过[:-1]和[1:]邻位相乘,判断相邻样本sdf值是否变号,由此确定物体的表面位置。每条射线选定一个value值最小的样本,再利用hit_surface_mask判断该样本是否有效。第1个判别条件,value值为负,代表出现过正负交叉。第2个判别条件,代表是由正的位置变到负的位置,而不是负变正,代表射线是从外部射入内部,而不是内部射出。第3个判别条件,射线样本在volume地图内部。由此得到hit_pts(一系列三维坐标点),代表射线穿过的物体表面在世界坐标系下的坐标。
Step6:计算volume地图的norms信息(sdf值在三个方向上的变化梯度)。
Step7:基于已得到的volume地图的norms信息,对hit_pts三维点的sdf值变化梯度进行插值拟合。
Step8:对物体表面位置的坐标再做一些细化微调(原来的hit_pts记录的只是voxel的坐标,这里根据voxel上的sdf值再做一些修正,使得物体表面的坐标更加精确)。
Step9:基于已得到的物体表面位置的三维坐标(世界坐标系),转化到相机坐标系,z轴分量即可代表depth深度图,三维坐标点上的rgb分量即可投影得到rgb图像。
六、ICP_Tracker部分
ICP_Tracker用于计算上一帧到当前帧的位姿变换,用于估计当前帧的c2w位姿矩阵。
输入:depth0、depth1、K
输出:位姿变换矩阵T10。
值得注意的是,这里depth0代表的是volume地图重投影到上一帧的深度图,depth1代表传感器采集到的当前帧深度图。之所以depth0不使用传感器采集到的深度图,而引入一个复杂的重投影过程,是因为frame-to-model策略相比于frame-to-frame策略,能够减少位姿累积误差。
Step1:将rgb、depth金字塔缩放三次,[30, 40]、[60, 80]、[120, 160]。初始位姿变换设为I,按照从小到大的顺序,先估计小分辨率的位姿变换,再逐步迭代到大分辨率的位姿变换,不断迭代。
Step2:根据某个尺度下depth0、depth1深度值,得到位姿0和位姿1下的三维点云坐标。
Step3:将vertex0点云坐标,乘上位姿变换,得到新的点云坐标vertex0_to1。
Step4:根据vertex0_to1的投影索引坐标,对vertex1点云坐标进行重采样,得到对应的r_vertex1点云,这样做的目的是将两个点云同一投影位置的三维点关联起来。
Step5:如果位姿变换是准确的,则vertex0_to1和r_vertex1应该很接近,由此定义损失函数 diff = vertex0_to1 - r_vertex1,阻尼高斯牛顿法求解。
七:实验结果
采用"tum/rgbd_dataset_freiburg1_desk"数据集进行三维重建,速度接近实时,重建效果如下:

不过阅读源码后,有些细节还是难以把握:
此处超参数设置为[-2.5, 2.0, -0.7, 2.7, -0.2, 2.0]的T_SDF volume,采用2cm resolution,这些数值是如何预先设定出来的?在实际部署重建时,该怎样调整得到合适的超参?
细节备注:
(1)t_sdf截断,采用3个voxel_size为基准,距离超过3个voxel_size的sdf值均取为+1或-1,在3个voxel_length范围内的则用小数记录。
(2)volume地图,物体内部voxel的sdf值为负,物体外部voxel的sdf值为正。射线判断物体表面有两种可能,一种是由正值变为负值,代表穿入物体,另一种是由负值变为正值,代表穿出物体。