前言
本文隶属于专栏《大数据安装部署》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
软件要求
Hadoop: cdh5.x, cdh6.x, hdp2.x, EMR5.x, EMR6.x, HDI4.x
Hive: 0.13 - 1.2.1+
Spark: 2.4.7/3.1.1
Mysql: 5.1.17 及以上
JDK: 1.8+
OS: Linux only, CentOS 6.5+ or Ubuntu 16.0.4+
准备
在 node1 执行下面的操作:
建议使用下面的安装包:
解压到指定文件夹:
tar -zxvf apache-kylin-4.0.2-bin.tar.gz -C /opt/bigdata/
配置环境变量 $KYLIN_HOME 指向 Kylin 文件夹。
vim /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_341-amd64
KYLIN_HOME=/opt/bigdata/apache-kylin-4.0.2-bin
PATH=$PATH:$JAVA_HOME/bin:$KYLIN_HOME/bin
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL JAVA_HOME KYLIN_HOME
source /etc/profile
使用脚本下载 spark
download-spark.sh
下载的 Spark 版本是 3.1.3 版本的,Spark 的安装目录在 $KYLIN_HOME/spark 目录下。
JDBC 驱动包
我们需要将 Mysql JDBC 的驱动包放到 $KYLIN_HOME/ext 目录下(没有这个目录需要手动创建)
cp mysql-connector-java.jar /opt/bigdata/apache-kylin-4.0.2-bin/ext/
将 node1 节点的 kylin 安装目录拷贝到 node2 和 node3:
scp -r /opt/bigdata/apache-kylin-4.0.2-bin/ node2:/opt/bigdata/
scp -r /opt/bigdata/apache-kylin-4.0.2-bin/ node3:/opt/bigdata/
kylin.properties 配置
vim /opt/bigdata/apache-kylin-4.0.2-bin/conf/kylin.properties
3 个节点的 kylin 配置信息如下,其中 node1 用于查询, node2 和 node3 用于任务执行。
node1
kylin.metadata.url=kylin_test@jdbc,driverClassName=com.mysql.jdbc.Driver,url=jdbc:mysql://node1:3306/kylin,username=kylin,[email protected]=node2:2181
kylin.server.cluster-servers-with-mode=node1:7070:query,node2:7070:job,node3:7070:job
kylin.job.scheduler.default=100
kylin.server.mode=query
kylin.cube.cubeplanner.enabled=true
kylin.server.query-metrics2-enabled=true
kylin.metrics.reporter-query-enabled=true
kylin.metrics.reporter-job-enabled=true
kylin.metrics.monitor-enabled=true
kylin.web.dashboard-enabled=true
kylin.metadata.url 配置了 Mysql 元数据库连接信息
kylin.env.zookeeper-connect-string 配置了 ZK 的连接信息
kylin.server.cluster-servers-with-mode 配置了所有 kylin 节点的信息,方便服务自主发现。
kylin.job.scheduler.default=100 配置了可以方便服务自主发现。
kylin.server.mode 配置了当前 kylin 节点的类型(query——代表查询节点,job——代表任务节点,all——代表两种都可以)
kylin.cube.cubeplanner.enabled/kylin.server.query-metrics2-enabled/kylin.metrics.* 可以开启 Cube Planner
Cube Planner使 Apache Kylin 变得更节约资源。其智能 build 部分 Cube 以最小化 building Cube 的花费且同时最大化服务终端用户查询的利益,然后从运行中的查询学习模式且相应的进行动态的推荐 cuboids。
kylin.web.dashboard-enabled 可以开启 Kylin Dashboard,这个只有 query/all 节点才有用。
Kylin Dashboard展示有用的 Cube 使用数据,对用户非常重要。
node2/node3
kylin.metadata.url=kylin_test@jdbc,driverClassName=com.mysql.jdbc.Driver,url=jdbc:mysql://node1:3306/kylin,username=kylin,password=1qaz@WSX
kylin.env.zookeeper-connect-string=node2:2181
kylin.server.cluster-servers-with-mode=node1:7070:query,node2:7070:job,node3:7070:job
kylin.server.mode=job
kylin.cube.cubeplanner.enabled=true
kylin.server.query-metrics2-enabled=true
kylin.metrics.reporter-query-enabled=true
kylin.metrics.reporter-job-enabled=true
kylin.metrics.monitor-enabled=true
kylin.web.dashboard-enabled=false
kylin.job.scheduler.default=100
kylin.server.self-discovery-enabled=true
kylin.job.lock=org.apache.kylin.job.lock.zookeeper.ZookeeperJobLock
node2 和 node3 的配置信息完全一样。
kylin.job.scheduler.default=100
kylin.server.self-discovery-enabled=true
以上配置可以引入基于Curator的主从模式多任务引擎调度器CuratorScheculer
kylin.job.lock=org.apache.kylin.job.lock.zookeeper.ZookeeperJobLock
这个配置可以使得任务引擎高可用。
解决root用户对HDFS文件系统操作权限不够问题
这时如果直接启动 kylin 会报错,因为 HDFS 文件系统中 hdfs 才有超级用户权限,故我们需要以下设置:
[root@node1 ~]# sudo -u hdfs hadoop fs -chown -R root:root /kylin
[root@node1 ~]# sudo -u hdfs hadoop fs -chown -R root:root /kylin
[root@node1 ~]# hadoop fs -ls /
Found 3 items
drwxr-xr-x - root root 0 2022-10-23 16:58 /kylin
drwxrwxrwt - hdfs supergroup 0 2022-10-23 15:47 /tmp
drwxr-xr-x - hdfs supergroup 0 2022-10-23 15:47 /user
这时我们在三个节点都运行运行环境检查脚本:
[root@node1 ~]# check-env.sh
Retrieving hadoop conf dir...
...................................................[PASS]
KYLIN_HOME is set to /opt/bigdata/apache-kylin-4.0.2-bin
Checking hive
...................................................[PASS]
Checking hadoop shell
...................................................[PASS]
Checking hdfs working dir
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
...................................................[PASS]
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
Checking environment finished successfully. To check again, run 'bin/check-env.sh' manually.
这就代表 kylin 可以正常启动了。
启动
在 3 个节点都执行下面的启动命令:
kylin.sh start
如下:
[root@node2 ~]# kylin.sh start
Retrieving hadoop conf dir...
...................................................[PASS]
KYLIN_HOME is set to /opt/bigdata/apache-kylin-4.0.2-bin
Checking hive
...................................................[PASS]
Checking hadoop shell
...................................................[PASS]
Checking hdfs working dir
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
...................................................[PASS]
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
WARNING: log4j.properties is not found. HADOOP_CONF_DIR may be incomplete.
Checking environment finished successfully. To check again, run 'bin/check-env.sh' manually.
Retrieving hadoop conf dir...
Retrieving Spark dependency...
Start replace hadoop jars under /opt/bigdata/apache-kylin-4.0.2-bin/spark/jars.
Find platform specific jars:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop/client/hadoop-annotations-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop/client/hadoop-auth-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop/client/hadoop-common-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop/hadoop-annotations-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop/hadoop-common-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop/hadoop-auth-3.0.0-cdh6.3.2.jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-hdfs/hadoop-hdfs-client.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-hdfs/hadoop-hdfs-httpfs.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-hdfs/hadoop-hdfs-native-client.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-hdfs/hadoop-hdfs-native-client-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-hdfs/hadoop-hdfs-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-hdfs/hadoop-hdfs-httpfs-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-hdfs/hadoop-hdfs-client-3.0.0-cdh6.3.2.jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-app-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-shuffle-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-yarn/hadoop-yarn-common-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-yarn/hadoop-yarn-api-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-yarn/hadoop-yarn-server-web-proxy-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-yarn/hadoop-yarn-client-3.0.0-cdh6.3.2.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../hadoop-yarn/hadoop-yarn-server-common-3.0.0-cdh6.3.2.jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/htrace-core4-4.2.0-incubating.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/htrace-core4-4.1.0-incubating.jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/woodstox-core-5.0.3.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/woodstox-core-5.1.0.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/commons-configuration2-2.1.1.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/woodstox-core-asl-4.4.1.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/re2j-1.1.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/commons-configuration2-2.1.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/stax2-api-3.1.4.jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/../../jars/re2j-1.0.jar , will replace with these jars under /opt/bigdata/apache-kylin-4.0.2-bin/spark/jars.
Done hadoop jars replacement under /opt/bigdata/apache-kylin-4.0.2-bin/spark/jars.
Start to check whether we need to migrate acl tables
Not HBase metadata. Skip check.
A new Kylin instance is started by root. To stop it, run 'kylin.sh stop'
Check the log at /opt/bigdata/apache-kylin-4.0.2-bin/logs/kylin.log
Web UI is at http://node2:7070/kylin
WEB UI
访问 node1 节点的 WEB UI:
http://node1:7070/kylin/login
用户名密码是: ADMIN/KYLIN
登录进去后,就可以看到:
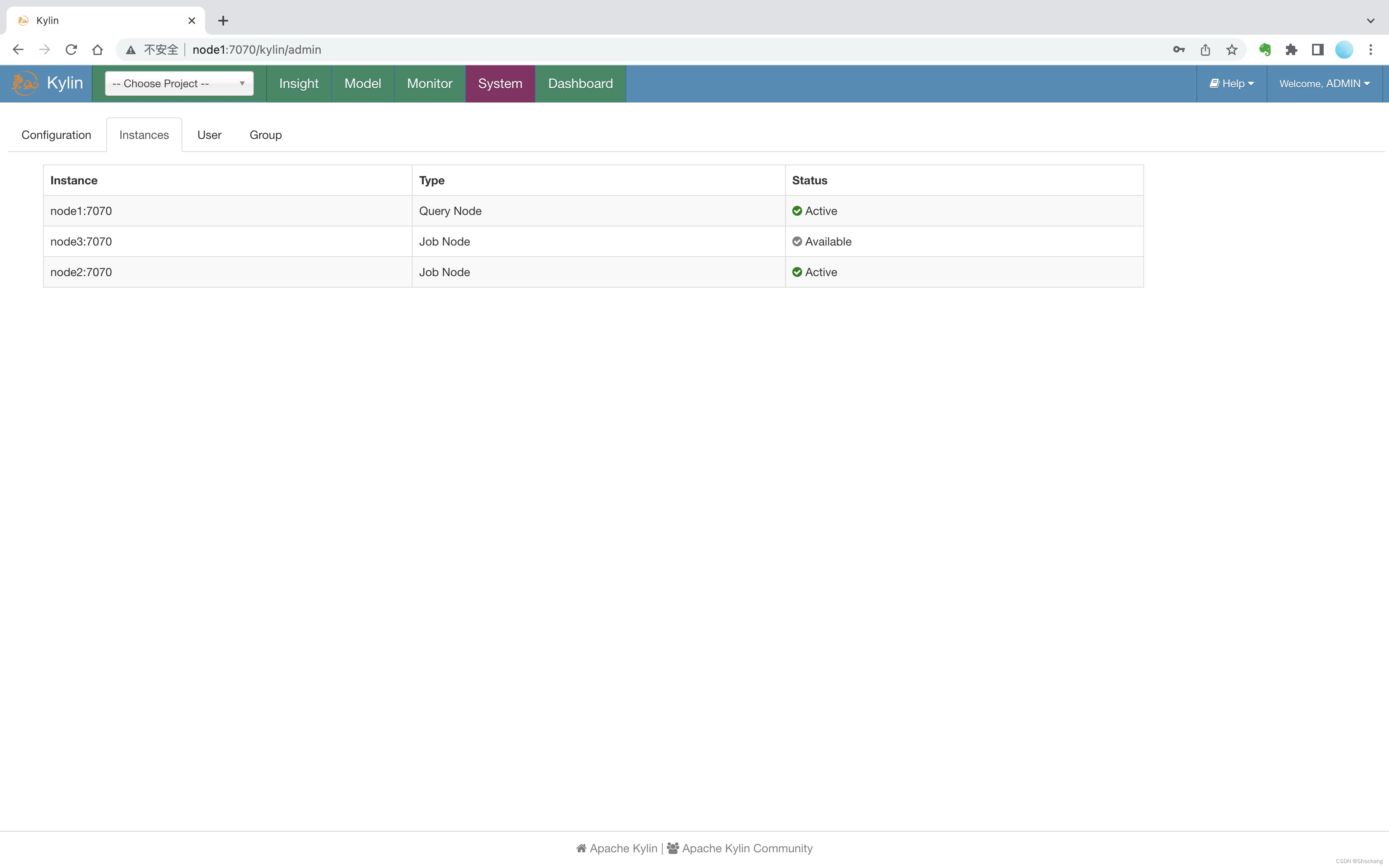
在 System => Instances 中我们可以看到 3 个节点的状态信息