本篇文章就概念、工作机制、数据备份、优势与不足4个方面详细介绍了Apache Kylin。
Apache Kylin 简介
1. Apache kylin 是一个开源的海量数据分布式预处理引擎。它通过 ANSI-SQL 接口,提供基于 hadoop 的超大数据集(TB-PB 级)的多维分析(OLAP)功能。
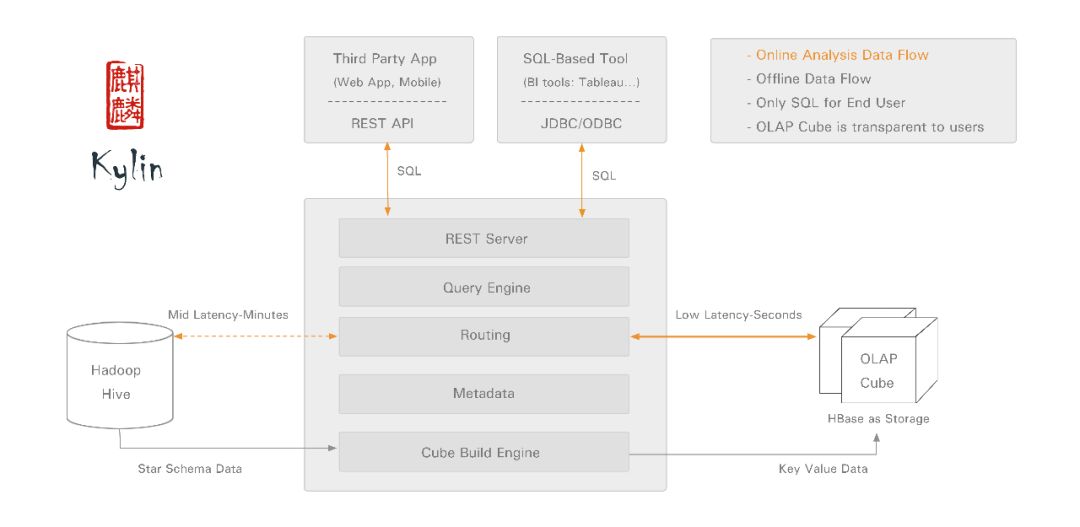
2. kylin 可实现超大数据集上的亚秒级(sub-second latency)查询。
1)确定 hadoop 上一个星型模式的数据集。
2)构建数据立方体 cube。
3)可通过 ODBC, JDBC,RESTful API 等接口在亚秒级的延迟内查询相
Apache Kylin 核心概念
1. 表(Table ):表定义在 hive 中,是数据立方体(Data cube)的数据源,在 build cube 之前,必须同步在 kylin 中。
2. 模型(model): 模型描述了一个星型模式的数据结构,它定义了一个事实表(Fact Table)和多个查找表(Lookup Table)的连接和过滤关系。
3. 立方体(Cube):它定义了使用的模型、模型中的表的维度(dimension)、度量(measure , 一般指聚合函数,如:sum、count、average 等)、如何对段分区( segments partition)、合并段(segments auto-merge)等的规则。
4. 立方体段(Cube Segment):它是立方体构建(build)后的数据载体,一个 segment 映射 hbase 中的一张表,立方体实例构建(build)后,会产生一个新的 segment,一旦某个已经构建的立方体的原始数据发生变化,只需刷新(fresh)变化的时间段所关联的 segment 即可。
5. 作业(Job):对立方体实例发出构建(build)请求后,会产生一个作业。该作业记录了立方体实例 build 时的每一步任务信息。作业的状态信息反映构建立方体实例的结果信息。如作业执行的状态信息为 RUNNING 时,表明立方体实例正在被构建;若作业状态信息为 FINISHED ,表明立方体实例构建成功;若作业状态信息为 ERROR ,表明立方体实例构建失败!作业的所有状态如下:
1)NEW - This denotes one job has been just created.
2)PENDING - This denotes one job is paused by job scheduler and waiting for resources.
3)RUNNING - This denotes one job is running in progress.
4)FINISHED - This denotes one job is successfully finished.
5)ERROR - This denotes one job is aborted with errors.
6)DISCARDED - This denotes one job is cancelled by end users.
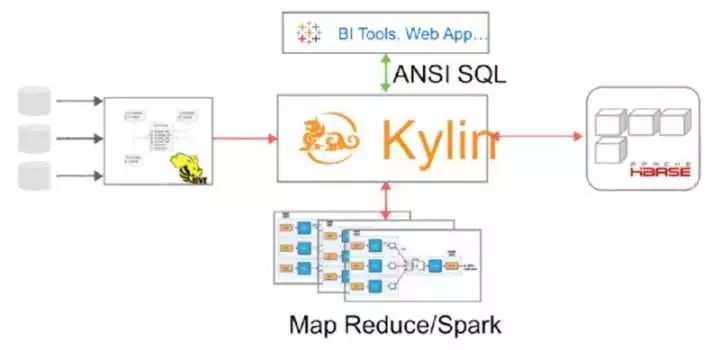
Apache Kylin 工作机制
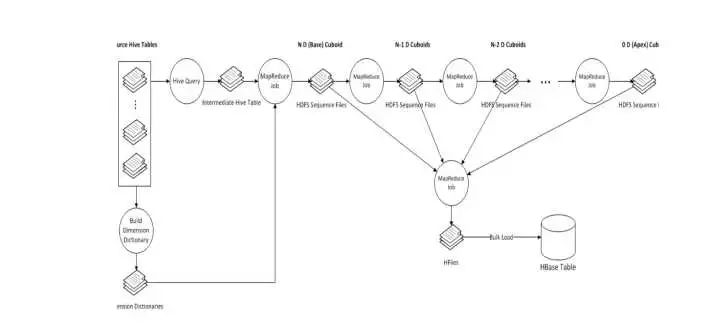
1. Apache kylin 能提供低延迟(sub-second latency)的秘诀就是预计算,即针对一个星型拓扑结构的数据立方体,预计算多个维度组合的度量,然后将结果保存在 hbase 中,对外暴露 JDBC、ODBC、Rest API 的查询接口,即可实现实时查询。数据立方体一般由 Hive 中的一个事实表, 多个查找表组成。预计算的过程在 kylin 中就是 Cube 的 build 过程,如下图:
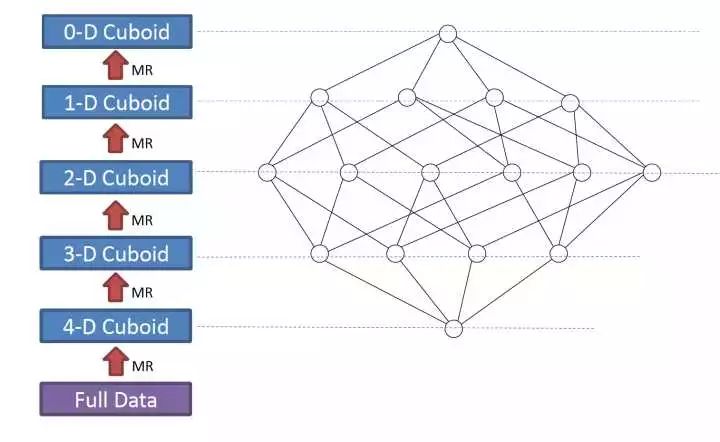
2. 当前 Apache kylin 构建(build)数据立方体,采用逐层算法(By Layer Cubing)。未来的发布中将采用快速立方体算法(Fast Cubing)。
下面简单介绍一下逐层算法:
一个完整的数据立方体,由 N-dimension 立方体,N-1 dimension 立方体,N-2 维立方体,0 dimension 立方体这样的层关系组成,除了 N-dimension 立方体,基于原数据计算,其他层的立方体可基于其父层的立方体计算。所以该算法的核心是 N 次顺序的 MapReduce 计算。
在 MapReduce 模型中,key 由维度的组合的构成,value 由度量的组合构成,当一个 Map 读到一个 key-value 对时,它会计算所有的子立方体(child cuboid),在每个子立方体中,Map 从 key 中移除一个维度,将新 key 和 value 输出到 reducer 中。直到当所有层计算完毕,才完成数据立方体的计算。过程如下图:
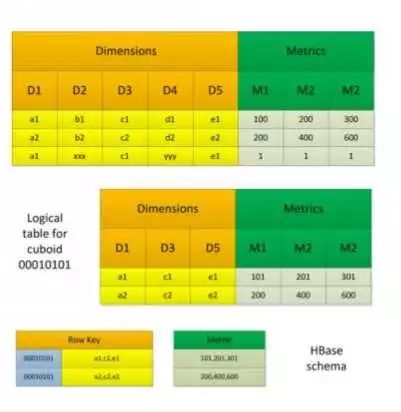
3. 在数据立方体计算完毕后,有一个任务(Convert Cuboid Data to HFile),其职责是将 reduce 输出的运算结果(Cuboid Data)转化成 Hbase 中的存储载体(HFile),最终将 HFile 加载到 Hbase 表中便于查询。其中表的 rowkey 由维度组合而成,维度组合对应的度量值构成了 column family,为了查询减少存储空间,会对 RowKey 和 column family 的值进行编码,默认编码是 Snappy。
4. 整个数据立方体的构建流程如下:
5. Apache kylin 架构如下:

6. 核心组件:
1)数据立方体构建引擎(Cube Build Engine):当前底层数据计算引擎支持 MapReduce1、MapReduce2、Spark 等。
2)Rest Server:当前 kylin 采用的 rest API、JDBC、ODBC 接口提供 web 服务。
3)查询引擎(Query Engine):Rest Server 接收查询请求后,解析 sql 语句,生成执行计划,然后转发查询请求到 Hbase 中,最后将结构返回给 Rest Server。
Apache Kylin 元数据备份
1. 备份元数据
Kylin 将它全部的元数据(包括 cube 描述和实例、项目、倒排索引描述和实例、任务、表和字典)组织成层级文件系统的形式。然而,Kylin 使用 hbase 来存储元数据,而不是一个普通的文件系统。如果你查看过 Kylin 的配置文件(kylin.properties),你会发现这样一行:
## The metadata store in hbase
kylin.metadata.url=kylin_metadata@hbase
这表明元数据会被保存在一个叫作 “kylin_metadata” 的 htable 里。你可以在 hbase shell 里 scan 该 htbale 来获取它。
2. 使用二进制包来备份 Metadata Store 有时你需要将 Kylin 的 Metadata Store 从 hbase 备份到磁盘文件系统。在这种情况下,假设你在部署 Kylin 的 hadoop 命令行(或沙盒)里,你可以到 KYLIN_HOME 并运行:
./bin/metastore.sh backup
来将你的元数据导出到本地目录,这个目录在 KYLIN_HOME/metadata_backps 下,它的命名规则使用了当前时间作为参数:KYLIN_HOME/meta_backups/meta_year_month_day_hour_minute_second 。
3. 使用二进制包来恢复 Metatdara Store
万一你发现你的元数据被搞得一团糟,想要恢复先前的备份:
首先,重置 Metatdara Store(这个会清理 Kylin 在 hbase 的 Metadata Store 的所有信息,请确保先备份):
./bin/metastore.sh reset
然后上传备份的元数据到 Kylin 的 Metadata Store:
./bin/metastore.sh restore $KYLIN_HOME/meta_backups/meta_xxxx_xx_xx_xx_xx_xx
4. 在开发环境备份 / 恢复元数据在开发调试 Kylin 时,典型的环境是一台装有 IDE 的开发机上和一个后台的沙盒,通常你会写代码并在开发机上运行测试案例,但每次都需要将二进制包放到沙盒里以检查元数据是很麻烦的。这时有一个名为 SandboxMetastoreCLI 工具类可以帮助你在开发机本地下载 / 上传元数据。
5. 从 Metadata Store 清理无用的资源
随着运行时间增长,类似字典、表快照的资源变得没有用(cube segment 被丢弃或者合并了),但是它们依旧占用空间,你可以运行命令来找到并清除它们:
首先,运行一个检查,这是安全的因为它不会改变任何东西:
./bin/metastore.sh clean
将要被删除的资源会被列出来:
接下来,增加 “–delete true” 参数来清理这些资源;在这之前,你应该确保已经备份 metadata store:
./bin/metastore.sh clean --delete true
Apache Kylin 的优势与不足
1. 性能非常稳定。因为 Kylin 依赖的所有服务,比如 Hive、HBase 都是非常成熟的,Kylin 本身的逻辑并不复杂,所以稳定性有一个很好的保证。目前在生产环境中,稳定性可以保证在 99.99% 以上。同时查询时延也比较理想。
2. 特别重要的一点,就是数据的精确性要求。其实现在能做到的只有 Kylin,在这一点上也没有什么太多其他的选择。
3. 从易用性上来讲,Kylin 也有非常多的特点。首先是外围的服务,不管是 Hive 还是 HBase,只要大家用 Hadoop 系统的话基本都有了,不需要额外工作。在部署运维和使用成本上来讲,都是比较低的。Kylin 有一个通用的 Web Server 开放出来,所有用户都可以去测试和定义,只有上线的时候需要管理员再 review 一下,这样体验就会好很多。
4. 查询灵活性。经常有业务方问到,如果 Cube 没定义的话怎么办?现在当然查询只能失败。这个说明有的查询模式不是那么固定的,可能突然要查一个数,但以后都不会再查了。实际上在需要预定义的 OLAP 引擎上,这种需求普遍来讲支持都不是太好。 从维度的角度来看,一般维度的个数在 5-20 个之间,相对来说还是比较适合用 Kylin 的。另一个特点是一般都会有一个日期维度,有可能是当天,也有可能是一个星期,一个月,或者任意一个时间段。另外也会有较多的层次维度,比如组织架构从最上面的大区一直到下面的蜂窝,就是一个典型的层次维度。 从指标的角度来讲,一般情况下指标个数在 50 个以内,相对来说 Kylin 在指标上的限制并没有那么严格,都能满足需求。其中有比较多的表达式指标,在 Kylin 里面聚合函数的参数只能是单独的一列,像 sum(if…) 这种就不能支持,因此需要一些特别的解决方法。另外一个非常重要的问题是数据的精确性,目前在 OLAP 领域,各个系统都是用 hyperloglog 等近似算法做去重计数,这主要是出于开销上的考虑,但业务场景有时要求数据必须是精确的。因此这也是要重点解决的问题
【本文转载自小米运维】