一、Kylin二进制源码目录解析
bin: shell 脚本,用于启动/停止Kylin,备份/恢复Kylin元数据,以及一些检查端口、获取Hive/HBase依赖的方法等;conf: Hadoop 任务的XML配置文件,这些文件的作用可参考配置页面
lib: 供外面应用使用的jar文件,例如Hadoop任务jar, JDBC驱动, HBase coprocessor 等.meta_backups: 执行bin/metastore.sh backup后的默认的备份目录;sample_cube用于创建样例 Cube 和表的文件。spark: 自带的spark。tomcat: 自带的tomcat,用于启动Kylin服务。tool: 用于执行一些命令行的jar文件。
二、HDFS 目录结构
Kylin 会在 HDFS 上生成文件,根目录是 “/kylin” (可以在conf/kylin.properties中定制),然后会使用 Kylin 集群的元数据表名作为第二层目录名,默认为 “kylin_metadata”。
通常,/kylin/kylinmetadata目录下会有这么几种子目录:cardinality, coprocessor, kylin-jobid, resources, jdbc-resources.
- cardinality:Kylin 加载 Hive 表时,会启动一个 MR 任务来计算各个列的基数,输出结果会暂存在此目录。此目录可以安全清除。各个列的基数计算如下图所示:

- coprocessor:Kylin用于存放
HBase coprocessor jar的目录;请勿删除。 - kylin-jobid:Cube 计算过程的数据存储目录,请勿删除。 如需要清理,请遵循 [storage cleanup guide](http://kylin.apache.org/cn/docs/howto/howtocleanup_storage.html). 在构建Cube过程中,会在该目录下生成中间文件,如下图所示:
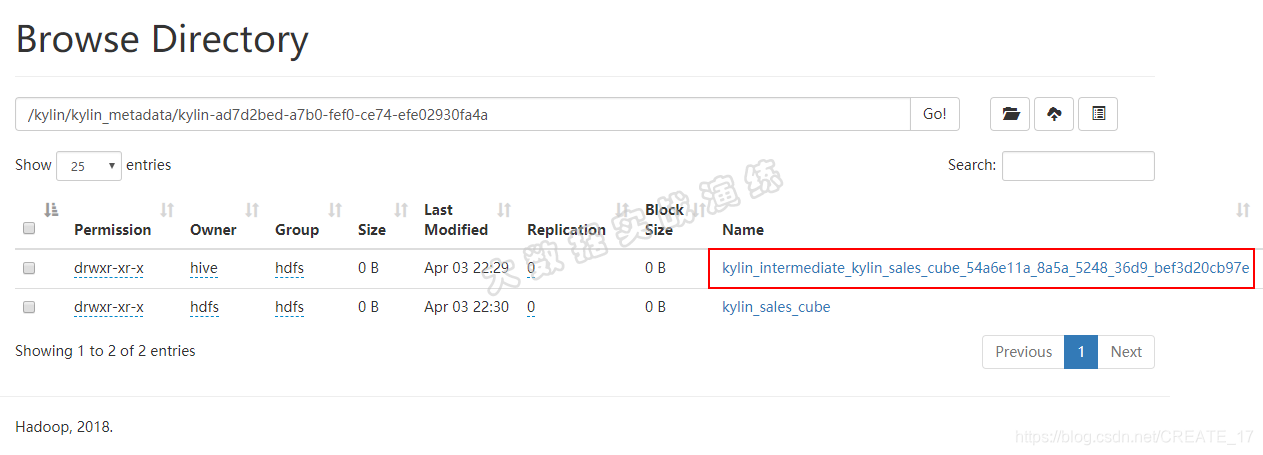
如果cube构建成功,该目录会自动删除;如果cube构建失败,需要手动删除该目录。
- resources:Kylin 默认会将元数据存放在 HBase,但对于太大的文件(如字典或快照),会转存到 HDFS 的该目录下,请勿删除。如需要清理,请遵循 cleanup resources from metadata.
- jdbc-resources:性质同上,只在使用 MySQL 做元数据存储时候出现。
执行Kylin官方自带的sample.sh文件,会将数据都临时加载到/tmp/kylin/sample_cube文件中,等到脚本执行完毕,会将该目录删除。
三、Zookeeper存储
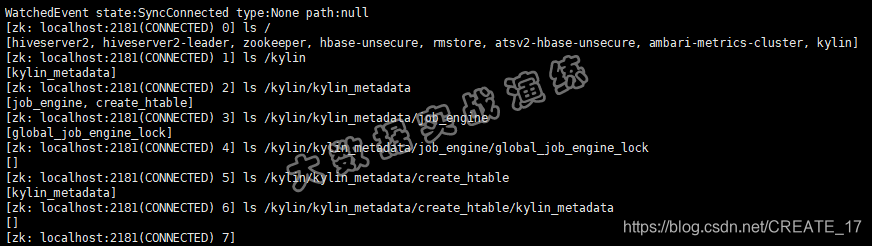
Kylin启动成功后,会在Zookeeper中注册/kylin的Znode节点,里面包含job_engine与create_htable的Znode节点,其中create_htable与HBase服务有关。
四、Hive表
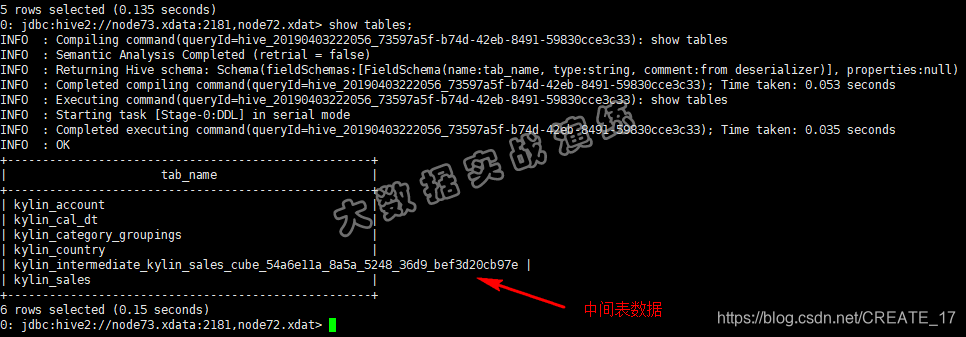
Kylin的数据来源于Hive数据库。在构建cube的时候,会在Hive数据库中生成中间表,如果cube构建成功,中间表会被删除;如果cube构建失败,中间表就会被遗留在Hive中,需要手动执行命令清理。
五、HBase表
kylin中有大量的元数据信息,包括cube的定义,星状模型的定义、job的信息、job的输出信息、维度的directory信息等等,元数据和cube都存储在hbase中,其中元数据默认存储在hbase的kylin_metadata表里面,存储的格式是json字符串。
当清理/删除/合并cube时,一些HBase表可能被遗留在HBase表。如果需要清理,请咨询:storage cleanup guide。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是 人才。
白嫖不好,创作不易。 各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !

