解析YOLO读取数据集的逻辑
1、解析xml文件
1.1正常进行划分
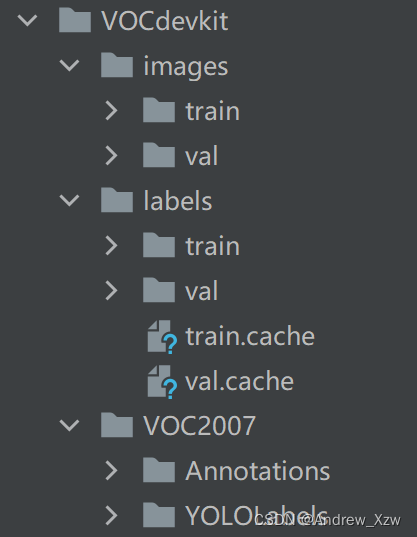
第1种解析方式,Annotations目录存放所有的 xml文件,进行解析后, YOLOLabels目录存放的是所有的标注信息转换的 txt文件。
然后,根据train、 val的比例,将images、 labels划分成train、val。
images存放每一张图片, labels存放的是刚才 YOLOLabels的txt文件。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
# 标签种类
classes = ['truck', 'car', 'van', 'camping_car', 'pick-up', 'tractor', 'vehicle', 'boat', 'plane', 'others']
TRAIN_RATIO = 80 # 训练集占比
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
#xml标注信息的目录地址
in_file = open('C:/Users/Desktop/yolov3/VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('C:/Users/Desktop/yolov3/VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
# clear_hidden_files(annotation_dir)
image_dir = 'C:/Users/Desktop/train/JPEGImages/'
# image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
# clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
# clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
# clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
# clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
# clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
# clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
# clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
# clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "car_train.txt"), 'w')
test_file = open(os.path.join(wd, "car_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "car_train.txt"), 'a')
test_file = open(os.path.join(wd, "car_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob,int(i))
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
1.2直接生成绝对路径
val.txt
第2种解析方式,
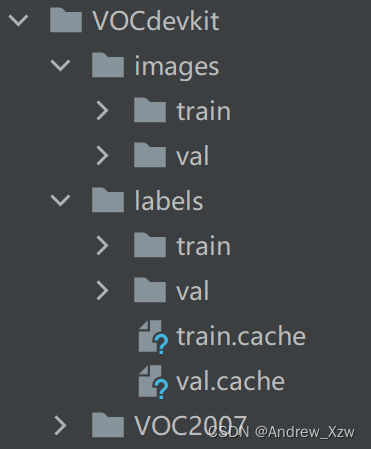
Annotations目录存放所有的 xml文件,images存放每一张图片, labels目录存放的是所有的标注信息转换的 txt文件。
dataSet_path目录下存放的就是train.txt、val.txt(绝对路径)

第一步先解析xml文件,按照train、val之间的比例,在下面文件夹下生成txt文件,存放的是每个图片的名称(不含后缀)
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='D:/yolo_vedai/yolov5-7.0/VOCDATA2/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='D:/yolo_vedai/yolov5-7.0/VOCDATA2/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
第2步,解析xml文件,按照train、val之间的比例,在下面文件夹下生成txt文件,存放的是每个图片的绝对路径(这个方法在下面的生成数据集,直接读)
// An highlighted block
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['truck', 'car', 'van', 'camping_car', 'pick-up', 'tractor', 'vehicle', 'boat', 'plane', 'others'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('D:/yolo_vedai/yolov5-7.0/VOCDATA2/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/yolo_vedai/yolov5-7.0/VOCDATA2/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('D:/yolo_vedai/yolov5-7.0/VOCDATA2/labels/'):
os.makedirs('D:/yolo_vedai/yolov5-7.0/VOCDATA2/labels/')
image_ids = open('D:/yolo_vedai/yolov5-7.0/VOCDATA2/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('D:/yolo_vedai/yolov5-7.0/VOCDATA2/dataSet_path/'):
os.makedirs('D:/yolo_vedai/yolov5-7.0/VOCDATA2/dataSet_path/')
list_file = open('D:/yolo_vedai/yolov5-7.0/VOCDATA2/dataSet_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image_id in image_ids:
list_file.write('D:/yolo_vedai/yolov5-7.0/VOCDATA2/images/%s.png\n' % (image_id))
convert_annotation(image_id)
list_file.close()
2、读取images地址
第一种方式首先将数据集的images、labels,分别划分成train、val。
class LoadImagesAndLabels(Dataset):
def __init__(self, path)
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
elif p.is_file(): # file
with open(p, 'r') as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace('./', parent) if x.startswith('./') else x for x in t]
img_files = sorted([x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in img_formats])
def __len__(self):
return len(img_files)
如果是第 1种方式,传入的 path = ‘D:\yolov\VOCdevkit\images\train’,那么当前路径下为文件, p.is_dir()为 True;
如果是第 2种方式,传入的 path = ‘D:\yolo\VOCdevkit\dataSet_path\train.txt’,那么当前路径下为目录, p.is_file()为 True;,那么当前路径下为文件。最终 f这个 list存放的都是每一张图片的绝对路径:
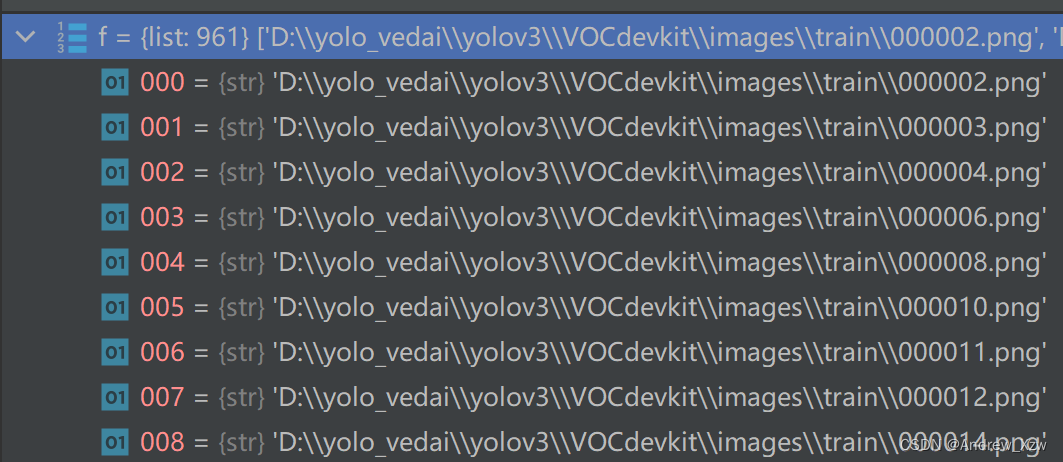
对 f进行排序, img_files这个变量接受的就是数据集中(这里就以train)的每一张图片的路径地址了。
3、根据images路径读取labels地址
label_files = img2label_paths(im_files)
def img2label_paths(img_paths):
sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}'
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
label_files 存放的就是通过解析xml文件(标注信息)转换的txt文件
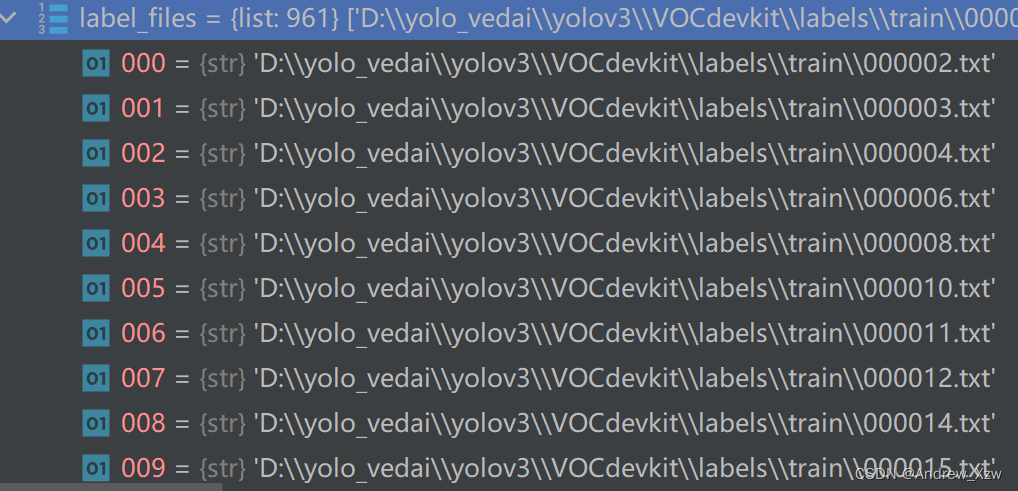
4、读取labels下每一个txt文件的标注信息
labels, shapes, self.segments = zip(*cache.values())
self.labels = list(labels)
这里的 self.labels存放的就是每一个txt文件的标注信息。
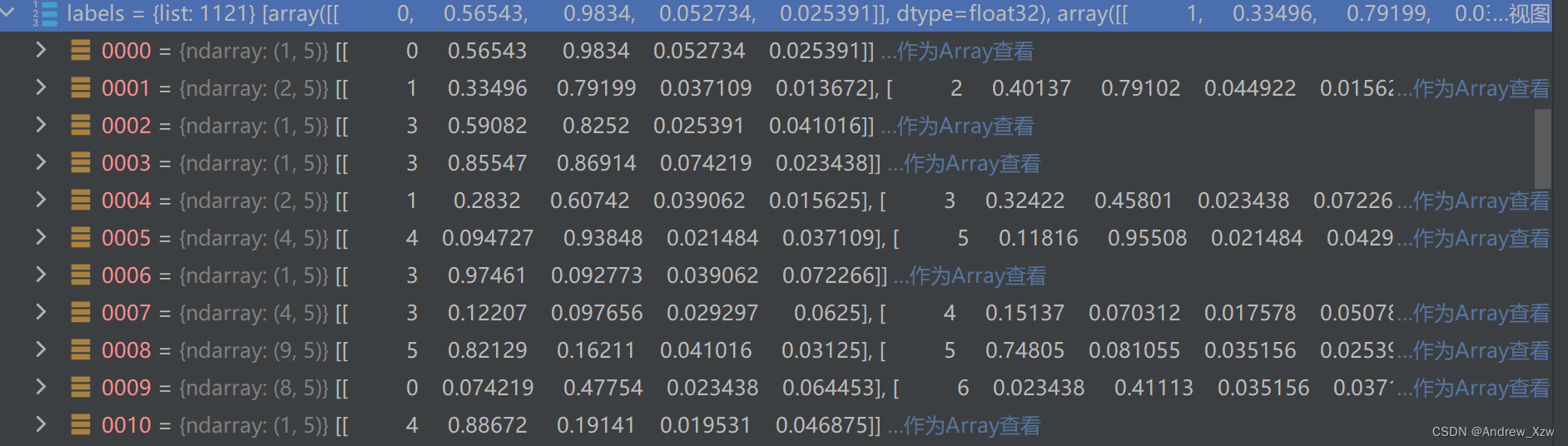
第1列就是类别对应的索引,依次往后就是box 的定位信息。