PRISM—probabilistic model checker概率模型检测器
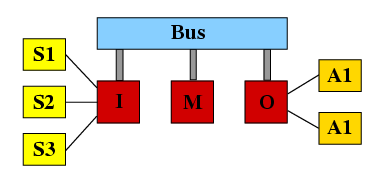
嵌入式控制系统模型 Theembedded control system
http://www.prismmodelchecker.org/casestudies/embedded.php 与连续时间马尔科夫链有关
模型说明
系统说明:
1.系统包含一个输入处理器inputprocessor(I),可读取和处理来自三个传感器sensor(S1,S2,S3)的数据
2.一个主处理器main processor(M)读取来自I的数据并把指令传给O;记录处理时间周期长度的计时器timer在M内
3.一个输出处理器outputprocessor(O),接受收到的指令并由此控制两个驱动器actuator(A1,A2)
4.一个总线bus连接三个处理器(I,M,O)
停机(shut down)条件:
-
超过一个传感器S失效,即S的数量<2,系统停机----MIN_SENSORS=2;
-
两个驱动器A都失效,即A的数量<1,系统停机----MIN_ACTUATORS=1;
-
输入/输出处理器也会失效,可能是永久性故障(permanentfault)或暂时性故障(transientfault):
如果系统暂时性故障,它自己可以自动改正并重新启动(reboot),也就是说暂时性故障的后一状态可能是重启(几率为1/30);
如果是永久性,那么I/O处理器不能运作导致主处理器不能读取和输出,那么M会强力直接跳过这个周期,如果M跳过的连续周期数量超过限制,系统会停机----MAX_COUNT
-
除非特殊规定,我们假设MAX_COUNT=2
-
主处理器M也可以失效,系统也就自动死机了
平均失效发生次数(概率)rate
一个传感器S sensor:1 month ---- lambda_s = 1/(30*24*60*60);
一个驱动器A actuator: 2 month ---- lambda_a = 1/(2*30*24*60*60);
一个处理器(I,M,O)processor:1 year ---- lambda_p = 1/(365*24*60*60)
一个暂时性故障transient fault:1day ---- delta_f = 1/(24*60*60);
一个计时器周期timer cycle:1minute ----tau=1/60;
一个处理器重启时间processor reboot:30seconds ----delta_r = 1/30;
(假设这些延期时间呈指数分布,所以这个系统可以用连续时间马尔科夫链CTMC建模)
PRISM code:
ctmc
//constants
constintMAX_COUNT;
constintMIN_SENSORS =2;
constintMIN_ACTUATORS =1;
//rates
constdoublelambda_p =1/(365*24*60*60);// 1 year
constdoublelambda_s =1/(30*24*60*60);// 1 month
constdoublelambda_a =1/(2*30*24*60*60);// 2 months
constdoubletau =1/60;// 1 min
constdoubledelta_f =1/(24*60*60);// 1 day
constdoubledelta_r =1/30;// 30 secs
//sensors
modulesensors
s : [0..3]init3;// number of sensorsworking
[]s>1 -> s*lambda_s : (s'=s-1);// failure of a singlesensor
endmodule
//input processor
//(takes data from sensors and passes onto main processor)
moduleproci
i : [0..2]init2;// 2=ok, 1=transientfault, 0=failed
[]i>0 & s>=MIN_SENSORS -> lambda_p : (i'=0);// failure ofprocessor
[]i=2 & s>=MIN_SENSORS -> delta_f : (i'=1);// transient fault
[input_reboot]i=1 & s>=MIN_SENSORS -> delta_r : (i'=2);// reboot aftertransient fault
endmodule
//actuators
moduleactuators
a : [0..2]init2;// number of actuatorsworking
[]a>0 -> a*lambda_a : (a'=a-1);// failure of a singleactuator
endmodule
//output processor
//(receives instructions from main processor and passes onto actuators)
moduleproco =proci [i=o,s=a,input_reboot=output_reboot,MIN_SENSORS=MIN_ACTUATORS ] endmodule
//main processor
//(takes data from proci, processes it, and passes instructions to proco)
moduleprocm
m : [0..1]init1;// 1=ok, 0=failed
count : [0..MAX_COUNT+1]init0;// number ofconsecutive skipped cycles
//failure of processor
[]m=1 -> lambda_p : (m'=0);
//processing completed before timer expires - reset skipped cycle counter
[timeout] comp ->tau : (count'=0);
//processing not completed before timer expires - increment skipped cycle counter
[timeout] !comp -> tau : (count'=min(count+1,MAX_COUNT+1));
endmodule
//connecting bus
modulebus
//flags
//main processor has processed data from input processor
//and sent corresponding instructions to output processor (since last timeout)
comp :bool init true;
//input processor has data ready to send
reqi :bool init true;
//output processor has instructions ready to be processed
reqo :bool init false;
//input processor reboots
[input_reboot] true -> 1 :
//performs a computation if has already done so or
//it is up and ouput clear (i.e. nothing waiting)
(comp'=(comp | (m=1 & !reqo)))
//up therefore something to process
& (reqi'=true)
//something to process if not functioning and either
//there is something already pending
//or the main processor sends a request
& (reqo'=!(o=2 & a>=1) & (reqo |m=1));
//output processor reboots
[output_reboot]true -> 1 :
//performs a computation if it has already or
//something waiting and is up
//(can be processes as the output has come up and cleared pending requests)
(comp'=(comp | (reqi &m=1)))
//something to process it they are up or
//there was already something and the main processor acts
//(output now up must be due to main processor being down)
& (reqi'=(i=2 & s>=2) | (reqi &m=0))
//output and actuators up therefore nothing can be pending
& (reqo'=false);
//main processor times out
[timeout]true -> 1 :
//performs a computation if it is up something was pending
//and nothing is waiting for the output
(comp'=(reqi & !reqo &m=1))
//something to process if up or
//already something and main process cannot act
//(down or outputs pending)
& (reqi'=(i=2 & s>=2) | (reqi & (reqo | m=0)))
//something to process if they are not functioning and
//either something is already pending
//or the main processor acts
& (reqo'=!(o=2 & a>=1) & (reqo | (reqi & m=1)));
endmodule
//the system is down
formuladown = (i=2&s<MIN_SENSORS)|(count=MAX_COUNT+1)|(o=2&a<MIN_ACTUATORS)|(m=0);
//transient failure has occured but the system is not down
formuladanger = !down & (i=1 | o=1);
//the system is operational
formulaup = !down & !danger;
//reward structures
rewards "up"
up :1/3600;
endrewards
rewards "danger"
danger :1/3600;
endrewards
rewards "down"
down :1/3600;
endrewards
代码解释:
• []s>1 ->s*lambda_s : (s'=s-1); “:”左边是执行下一状态的概率,右边是下一状态。这里指当s>1时,执行s’=s-1的概率为s*lambda_s。如s为3时,执行s=2的概率为3*lambda_s.
•moduleproco =proci [i=o,s=a,input_reboot=output_reboot,MIN_SENSORS=MIN_ACTUATORS ]endmodule 即把上个模型proci的变量套用到这里。
•i: [0..2]init2;// 2=ok,1=transient fault,0=failed状态2正常运行,1暂时失效,0死机。
[]i=2 &s>=MIN_SENSORS ->delta_f: (i'=1);当I,S没问题时,有暂时失效的可能性跳到i=1。
[input_reboot]i=1 &s>=MIN_SENSORS->delta_r : (i'=2);在暂时失效状态时有重启可能回到状态t=2,即OK。该动作叫input_reboot,在模块proci内。(动作:可使不同模块间的不同状态(在同一动作内)同时发生,具体参考同时性synchronisationhttp://www.prismmodelchecker.org/manual/ThePRISMLanguage/Synchronisation)
•count: [0..MAX_COUNT+1]init0;设count记录连续跳跃周期的数目,初始值为0.
[timeout] comp ->tau : (count'=0);设置timeout动作,当处于comp状态时(后面有说明是主处理器M的上一状态是正常的),有tau的可能性,进程在一个时间周期内完成,跳跃就不连续了,重设count=0.
[timeout] !comp ->tau: (count'=min(count+1,MAX_COUNT+1)); 设置timeout动作,当处于非comp状态时(即主处理器M的上一状态是不正常的),有tau的可能性,进程没能在一个时间周期内完成,跳跃就连续了,count就加1.
• [input_reboot] true ->1: (comp'=(comp| (m=1& !reqo))) & (reqi'=true) & (reqo'=!(o=2 &a>=1) &(reqo |m=1));(该动作与上面的在不同的模块,该动作在bus模块内,两处同时发生)
当proci模块中的input_reboot动作发生时,bus模块里的input_reboot动作百分之一百(true)执行,概率为1(百分之一百)执行下一状态comp’,reqi‘和reqo’:
comp’状态执行时,M输入输出正常(comp),或者M正常时O不正常(m=1 & !reqo)。
reqi’为I百分之百正常(reqi'=true)。
reqo’为O可正常也可不正常& (reqo'=!(o=2 &a>=1) &(reqo |m=1)。
这里的括号要注意!!
代码用法具体网址:http://www.prismmodelchecker.org/manual/ThePRISMLanguage/Commands
http://www.prismmodelchecker.org/manual/ThePRISMLanguage/ModulesAndVariables
http://www.prismmodelchecker.org/manual/ThePRISMLanguage/Synchronisation
测试1:
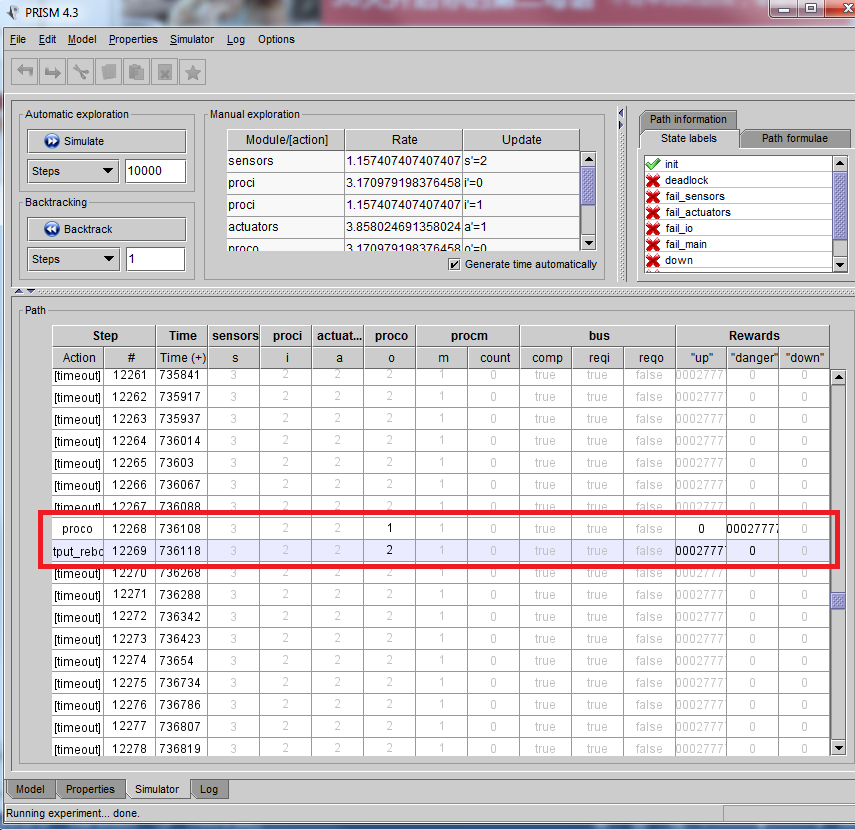
我用模拟器simulator玩了一下这个系统,在步骤steps里填入1000,10000,100000,1000000分别测试,发现10000是比较好的步骤测试数。下图就是两次10000步的运行下系统死机的情况:
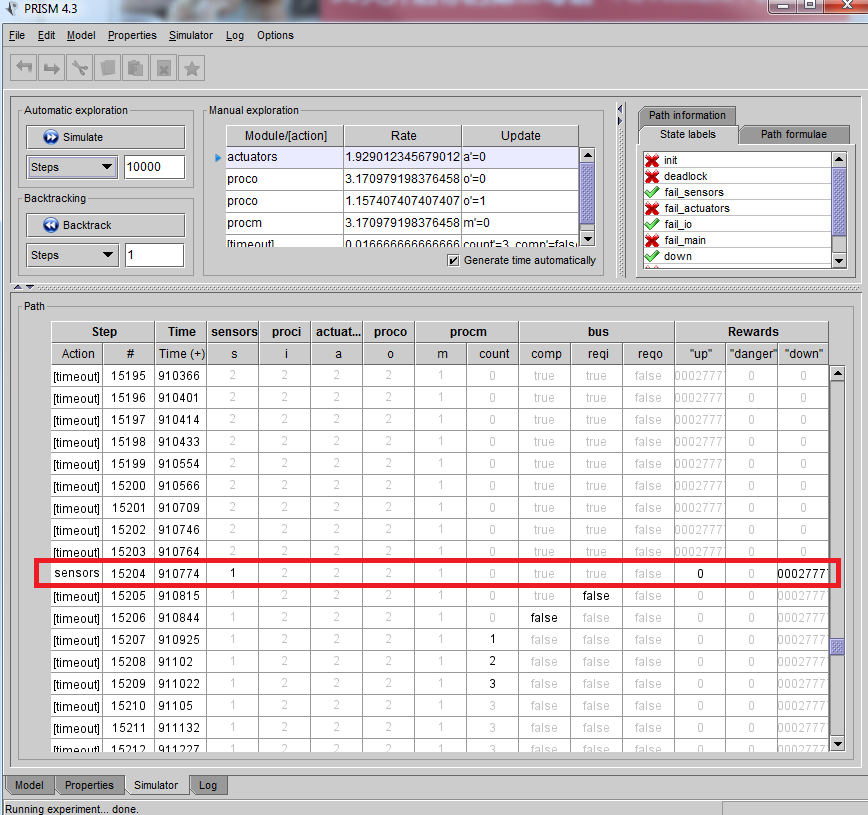
可以看出这次系统死机是因为两个传感器都挂了(S<2)所以系统直接死机了,在‘down’一栏不为0了。当然这次测试的步骤中间系统还是进行过多次自救的(reboot),如下图。仔细看Rewards中的‘up’和‘danger’栏,O暂时失效了。
测试2:
我用PRISM给的属性测了一下概率分布图,属性的源代码地址:
http://www.prismmodelchecker.org/casestudies/examples/embedded.csl
-
第一个测试的属性是P=? [ !"down"U<=T"fail_j" ]:
- 这里的down即是死机,插入源代码后down标签已设置好,不用自己设。
- “fail_j”的j=1..4,标签"fail_1"意义为"s<2 & i=2",对应代码中的fail_sensors;
- 标签"fail_2"意义为"a<1 &o=2 ",对应代码中的fail_actuators;
- 标签"fail_3"意义为"COUNT=MAX_COUNT+1",对应代码中的fail_io;
- 标签"fail_4"意义为"m=0",对应代码中的fail_main;
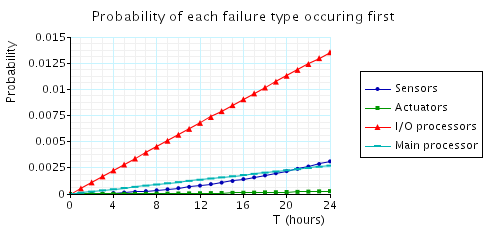
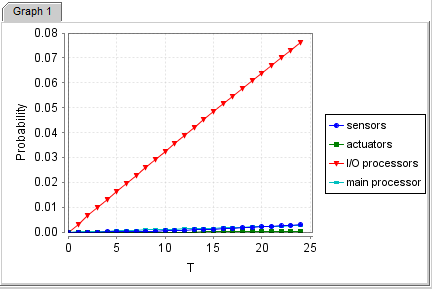
- 所以这个测试不需要自己写属性,只要把标签中的一些意义稍微改动即可。注意,在生成新试验图时,MAX_COUNT的范围range选择前面的start,T设为后面的end并赋值0-24(图一时间长是24小时且T=1h,图二是30天且T=1d要填0-30,step为1)
- 图一用的属性是P=? [!"down" U<=T*3600 "fail_main" ]等等(共四个属性),T被乘了3600说明T单位为1h(小时)。
- 图二用的属性是P=? [!"down" U<=T*3600*24 "fail_sensors" ]等等(共四个),T被乘以3600*24,说明T单位为1d(天)。
24小时:第一张是PRISM给的结果图,第二张是我测的图
-
-
-
结果看来还是有一些差距的,我的图中M的线和S靠得很近被盖住了,但放大看其实和给的图走向差不多,唯一的区别就是I/O线。我一开始有点迷茫为什么差距这么大,直到我调了MAX_COUNT的参数。我之前设它的range点击start并给值0,也就是说不允许M连续跳跃I/O的失效。我把值分别改成1和2,对应的是下面的I/O线和I/O(2)线。
果然,I/O(2)线的结果和PRISM给的结果相似,所以PRISM测试时count的值设的是2,而我设的是0,至于我的图中别的线没有受影响也是因为count对应的连续跳跃超限只给I/O死机带来影响。
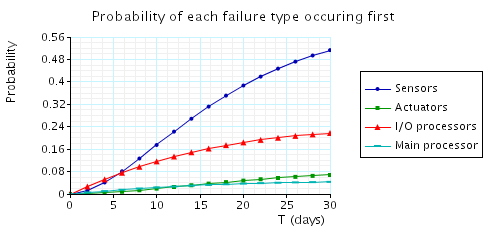
1个月:T设30。一个月的图确实每个曲线都要跑十几分钟才出来。第一张PRISM的,第二张我的。别问我为什么只有S。。跑太久了,你们要跑自己跑吧。。后面还有测试呢,实际上测试结果都和PRISM给的图差不多,可以自己改动参数玩玩。
-
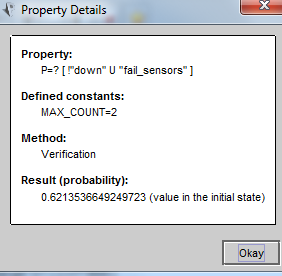
第二个测的属性是P=? [ !"down" U "fail_j"]
这里的j也是1..4,对应的也和上面一样。右键单击属性,用“Verify”测试。
测试时count也是用2。PRISM给出的结果如左下,右下是sensor的结果:

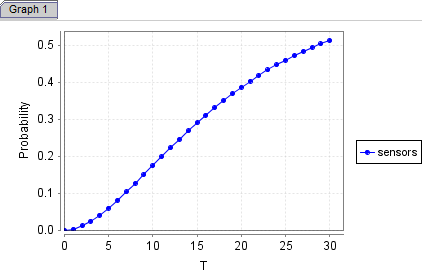
| Failure type |
|
Probability |
| Sensors |
0.6214 |
|
| Actuators |
0.0877 |
|
| I/O processors |
0.2425 |
|
| Main processor |
0.0484 |
结果都是一样的,另外三个我也测了都一样,就不列出来了。
有意思的是,当我把count改成1时,可能性也跟着变了(0也不一样):
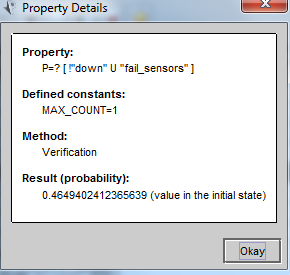
我倒回去再试了一次上一属性sensor的count分别为0,1,2时,曲线几乎的盖在一起,说明上一属性确实没问题。那么这里的sensor的可能性为什么就会受count影响呢?
嗯我仔细想了想,我个人觉得应该和这个属性的设置有关,这个属性里只有“U”没有“T”,也就没有时间这个变量了。所以能够影响属性的就只有恒量count,而count因为我设置的不同,就产生了不同的结果。(具体内部是怎么计算的我目前还没搞懂。。)
测试3:
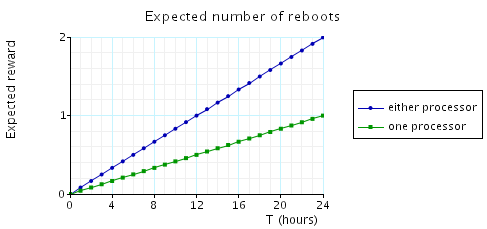
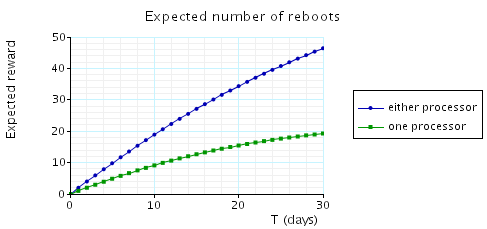
-
R{"reward_structure"}=? [C<=T ] 这个R指的是total cumulatedreward,也就是总共积累的reward。reward_structure对应有三个标签"down","danger"和"up"。
同样绘制两幅图,第一副24h,第二幅30d。count先默认设2看看。下面是PRISM跑出来的图。
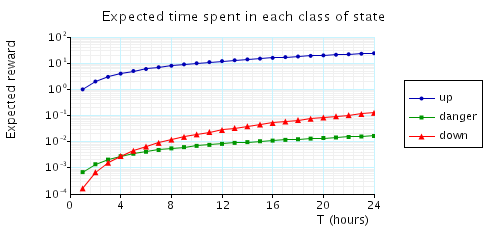
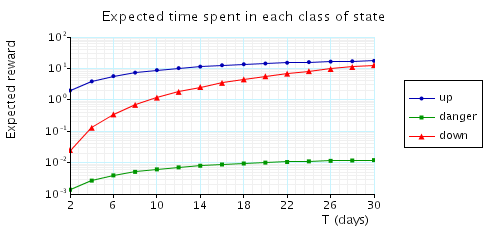
值得注意的是,这里count恒量的改动是会引起reward变化的,PRISM也给出了变化的结果:
| MAX_COUNT: |
|
Expected time: |
|
| danger (hrs): |
up (days): |
||
| 1 |
0.236 |
14.323 |
|
| 2 |
0.293 |
17.660 |
|
| 3 |
0.318 |
19.100 |
|
| 4 |
0.327 |
19.628 |
|
| 5 |
0.330 |
19.809 |
|
| 6 |
0.331 |
19.871 |
|
| 7 |
0.332 |
19.891 |
|
1.最后一个 R {"reward_structure"}=? [ F "down" ]的步骤也都类似。