从LSTM到LSTM-attention
LSTM来源:
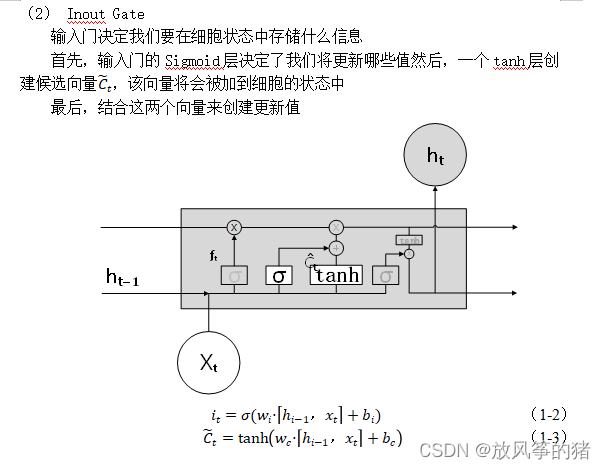
RNN问题:长期依赖问题和梯度消失问题,所以提出了 LSTM。
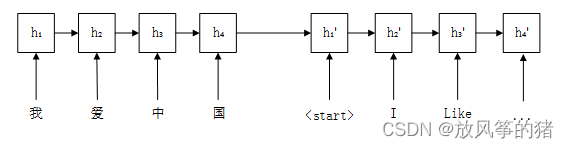
RNN结构图如图所示
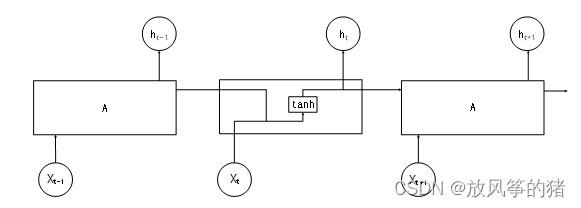
LSTM结构:

LSTM是RNN的变体,LSTM引入了一组记忆单元(Memory Units),允许网络可以学习何时遗忘历史信息,何时用新信息更新记忆单元。
核心:记忆(细胞状态)和门机制

细胞的状态在整条链上运行,只有一些小的线性操作作用其上,信息很容易保持不变的流过整条链。
门(Gate)是一种可选地让信息通过的方式。 它由一个sigmoid神经网络层和一个点乘法运算组成。
Sigmoid神经网络层输出0和1之间的数字,这个数字描述每个组件有多少信息可以通过, 0表示不通过任何信息,1表示全部通过。



LSTM-Attention模型
LSTM-Attention模型是一种基于循环神经网络(RNN)和注意力机制(Attention)的模型。它在长文本或序列数据的处理中表现出色,可以用于诸如自然语言处理(NLP)、语音识别、视频分类等领域。

LSTM-Attention模型的核心是将注意力机制嵌入到LSTM网络中,以便网络可以自动学习并关注输入序列中最重要的信息。在传统的LSTM网络中,每个时间步的输出都是固定的,无论输入序列的哪一部分对当前时间步的输出最有影响。而LSTM-Attention模型可以根据输入序列的内容,自适应地计算每个时间步的输出,使得模型更加灵活和准确。
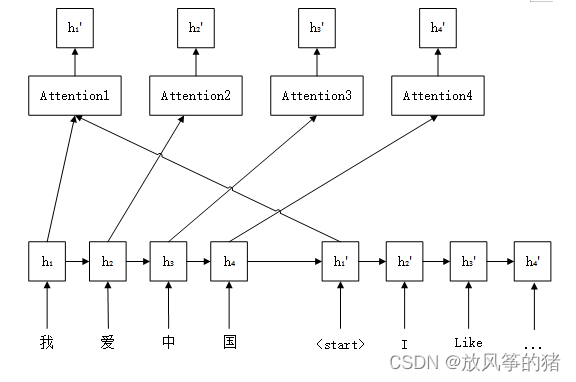
LSTM-Attention模型的工作原理如下:
输入序列的每个元素都通过嵌入层转换为一个向量表示。
LSTM网络对嵌入层的输出进行处理,生成一个包含所有时间步的输出序列。
对于每个时间步的输出,通过注意力机制计算出一个权重向量,该向量表示当前时间步输入序列中每个元素的重要性。
将所有时间步的输出和对应的权重向量进行加权求和,生成最终的表示。
最终表示经过一个全连接层,输出模型的预测结果。
需要注意的是,不同的LSTM-Attention模型可能在具体实现上有所不同,比如不同的注意力机制或不同的网络架构。但是总体来说,LSTM-Attention模型都是基于RNN和Attention机制的结合,用于处理序列数据的高效模型。
抖音评论爬取
这里只爬取了用户名和评论,id和url可以换成自己需要的网页,userName 和 comment 后面的path可以自己修改
# 打开页面后,尽量直接拉到评论下面!!!!
import random
import pandas as pd
import time
from selenium import webdriver
from tqdm import tqdm, trange
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeOptions
# 实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches',['enable-automation'])
def getData(url):
# chromedriver.exe,下载,这个看自己安装的Google的版本,下载解压后放到当前代码路径下。下载地址 http://chromedriver.storage.googleapis.com/index.html
driver = webdriver.Chrome(options=option)
driver.get(url)
time.sleep(20) # 手动点下弹窗关闭登录,或者自己扫码登录!!!
userNames = [] # 用户名
comments = [] # 评论文本
for i in trange(1, 1000): # 自行设定爬取条数,不建议太多!!!
try:
# 去掉中途出现的登录页面
driver.find_element(by=By.XPATH,
value='//*[@id="login-pannel"]/div[2]').click()
print("1")
except:
try:
# 用户名
userName = driver.find_element(by=By.XPATH,
value= f"//*[@id='douyin-right-container']/div[2]/div/div[1]/div[5]/div/div/div[3]/div[{i}]/div/div[2]/div/div[1]/div[1]/div/a/span/span/span/span/span/span").text
print(userName)
# 评论
comment = driver.find_element(by= By.XPATH,
value= f"//*[@id='douyin-right-container']/div[2]/div/div[1]/div[5]/div/div/div[3]/div[{i}]/div/div[2]/div[1]/p/span/span/span/span/span/span/span").text
print(comment)
userNames.append(userName)
comments.append(comment)
print(f"第{i}条下载完成!!!")
except:
continue
return userNames, comments
if __name__ == "__main__":
id = "7220016152687201593" # 这串数字是视频ID
url = f"https://www.douyin.com/video/{id}"
userNames, comments = getData(url)
print(userNames,comments)
data = pd.DataFrame({"userName":userNames, "comments": comments})
data.to_csv(f"./result_ID{id}.csv") # save path
print("**********done***********")爬取结果
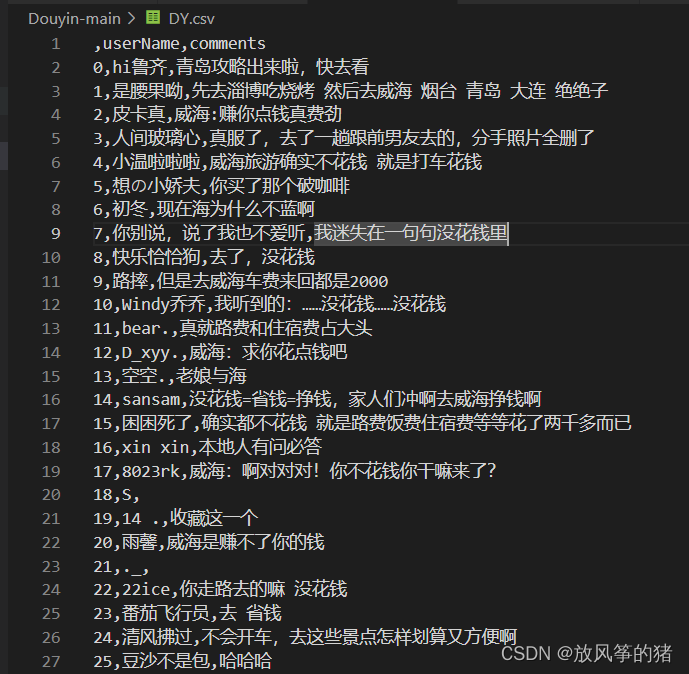
注意:我在爬取抖音的评论后,发现其中并没有什么谣言信息,很多都是网友的快乐评论,继续这样实现效果会效果会很不好,所以就只是用这个数据走了一遍流程,把数据处理到标注是否为谣言的这一步就停止了。下面放一下我处理这个数据的代码。
- 爬取到的数据是存储在csv文件中的,需要先转化为json格式,在这个过程中用jieba做简单分词处理。
import pandas as pd import jieba import json import os # 获取当前工作目录 cwd = os.getcwd() # 将相对路径转换为绝对路径 csv_path = os.path.abspath('./Douyin-main/DY.csv') # 使用绝对路径读取CSV文件 df = pd.read_csv(csv_path, encoding='utf-8') # 对数据做中文分词去噪处理 def clean_text(text): text = str(text) # 去掉换行符、制表符、多余空格 text = text.replace('\n', '').replace('\t', '').strip() # 分词并去掉停用词 stop_words = set(['的', '了', '是', '在', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这']) words = jieba.cut(text) words = [w for w in words if w not in stop_words] return ' '.join(words) data = [] with open('./Douyin-main/DY.json', 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False) f.write('\n') with open('./Douyin-main/DY.json', 'w', encoding='utf-8') as f: for index, row in df.iterrows(): item = { 'id': row['id'], 'userName': row['userName'], 'comments': clean_text(row['comments']) } json.dump(item, f, ensure_ascii=False) f.write('\n')得到的json如下:

- 将上面的json文件中的每一条数据分为一个json文件
import json import os # 创建all文件夹 if not os.path.exists('./Douyin-main/all'): os.makedirs('./Douyin-main/all') # 打开包含多个JSON对象的文件 with open('./Douyin-main/DY.json', 'r', encoding='utf-8') as f: json_data = f.read() # 将JSON字符串按照换行符分割成一个列表 json_objects = json_data.strip().split('\n') # 遍历列表,将每个JSON对象存储到单独的文件中 for i, json_str in enumerate(json_objects): # 将JSON字符串转换为Python对象 json_obj = json.loads(json_str) # 将Python对象转换为JSON字符串,格式化输出到文件中 with open(f'./Douyin-main/all/json_obj_{i}.json', 'w', encoding='utf-8') as out_file: out_file.write(json.dumps(json_obj, ensure_ascii=False, indent=4))接下来如果想自己标注数据的话就需要手动将谣言和非谣言分到两个文件夹中。
实现原理
本次实践使用基于循环神经网络(RNN)的谣言检测模型,将文本中的谣言事件向量化,通过循环神经网络的学习训练来挖掘表示文本深层的特征,避免了特征构建的问题,并能发现那些不容易被人发现的特征,从而产生更好的效果。
数据集介绍:
本次实践所使用的数据是从新浪微博不实信息举报平台抓取的中文谣言数据,数据集中共包含1538条谣言和1849条非谣言。每条数据均为json格式,其中text字段代表微博原文的文字内容。
数据集介绍参考https://github.com/thunlp/Chinese_Rumor_Dataset
环境设置
缺少的包用下面的命令下载即可
paddle包需要的python环境是3.8及以下,我这里使用的3.8,其他包都很好装。
pip install numpy==1.23.5 -i https://pypi.tuna.tsinghua.edu.cn/simple数据处理
下面的数据是项目中用到的数据,是从网上下载的标注好的谣言数据
(1)解压数据,读取并解析数据,生成all_data.txt
(2)生成数据字典,即dict.txt
(3)生成数据列表,并进行训练集与验证集的划分,train_list.txt 、eval_list.txt
(4)定义训练数据集提供器train_reader和验证数据集提供器eval_reader
- 生成all_data.txt
import zipfile
import os
import io
import random
import json
import matplotlib.pyplot as plt
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Linear, Embedding
from paddle.fluid.dygraph.base import to_variable
target_path = "."
#谣言数据文件路径
rumor_class_dirs = os.listdir(target_path+"/CED_Dataset/rumor-repost/")
#非谣言数据文件路径
non_rumor_class_dirs = os.listdir(target_path+"/CED_Dataset/non-rumor-repost/")
original_microblog = target_path+"/CED_Dataset/original-microblog/"
#谣言标签为0,非谣言标签为1
rumor_label="0"
non_rumor_label="1"
#分别统计谣言数据与非谣言数据的总数
rumor_num = 0
non_rumor_num = 0
all_rumor_list = []
all_non_rumor_list = []
#解析谣言数据
for rumor_class_dir in rumor_class_dirs:
if(rumor_class_dir != '.DS_Store'):
#遍历谣言数据,并解析
try:
with open(original_microblog + rumor_class_dir, 'r',encoding='utf-8') as f:
rumor_content = f.read()
rumor_dict = json.loads(rumor_content)
all_rumor_list.append(rumor_label+"\t"+rumor_dict["text"]+"\n")
rumor_num +=1
except:
print("无法读取文件:"+rumor_class_dir)
continue
#解析非谣言数据
for non_rumor_class_dir in non_rumor_class_dirs:
if(non_rumor_class_dir != '.DS_Store'):
try:
with open(original_microblog + non_rumor_class_dir, 'r',encoding='utf-8') as f2:
non_rumor_content = f2.read()
non_rumor_dict = json.loads(non_rumor_content)
all_non_rumor_list.append(non_rumor_label+"\t"+non_rumor_dict["text"]+"\n")
non_rumor_num +=1
except:
print("无法读取文件:"+non_rumor_class_dir)
continue
print("谣言数据总量为:"+str(rumor_num))
print("非谣言数据总量为:"+str(non_rumor_num))
#全部数据进行乱序后写入all_data.txt
data_list_path="./"
all_data_path=data_list_path + "all_data.txt"
all_data_list = all_rumor_list + all_non_rumor_list
random.shuffle(all_data_list)
#在生成all_data.txt之前,首先将其清空
with open(all_data_path, 'w') as f:
f.seek(0)
f.truncate()
with open(all_data_path, 'a') as f:
for data in all_data_list:
f.write(data)
print('all_data.txt已生成') 生成下面的文件:
- 生成数据字典
# 生成数据字典
data_path = "./all_data.txt"
dict_path = "./dict_data.txt"
# 生成数据字典
def create_dict(data_path, dict_path):
with open(dict_path, 'w') as f:
f.seek(0)
f.truncate()
dict_set = set()
# 读取全部数据
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 把数据生成一个元组
for line in lines:
content = line.split('\t')[-1].replace('\n', '')
for s in content:
dict_set.add(s)
# 把元组转换成字典,一个字对应一个数字
dict_list = []
i = 0
for s in dict_set:
dict_list.append([s, i])
i += 1
# 添加未知字符
dict_txt = dict(dict_list)
end_dict = {"<unk>": i}
dict_txt.update(end_dict)
end_dict = {"<pad>": i+1}
dict_txt.update(end_dict)
# 把这些字典保存到本地中
with open(dict_path, 'w', encoding='utf-8') as f:
f.write(str(dict_txt))
print("数据字典生成完成!")
create_dict(data_path, dict_path)生成下面的文件:

- 生成数据列表
import os
data_list_path = './'
# 创建序列化表示的数据,并按照一定比例划分训练数据train_list.txt与验证数据eval_list.txt
def create_data_list(data_list_path):
#在生成数据之前,首先将eval_list.txt和train_list.txt清空
with open(os.path.join(data_list_path, 'eval_list.txt'), 'w', encoding='utf-8') as f_eval:
f_eval.seek(0)
f_eval.truncate()
with open(os.path.join(data_list_path, 'train_list.txt'), 'w', encoding='utf-8') as f_train:
f_train.seek(0)
f_train.truncate()
with open(os.path.join(data_list_path, 'dict_data.txt'), 'r', encoding='utf-8') as f_data:
dict_txt = eval(f_data.readlines()[0])
with open(os.path.join(data_list_path, 'all_data.txt'), 'r', encoding='utf-8') as f_data:
lines = f_data.readlines()
i = 0
maxlen = 0
with open(os.path.join(data_list_path, 'eval_list.txt'), 'a', encoding='utf-8') as f_eval,open(os.path.join(data_list_path, 'train_list.txt'), 'a', encoding='utf-8') as f_train:
for line in lines:
words = line.split('\t')[-1].replace('\n', '')
maxlen = max(maxlen, len(words))
label = line.split('\t')[0]
labs = ""
# 每8个 抽取一个数据用于验证
if i % 8 == 0:
for s in words:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + label + '\n'
f_eval.write(labs)
else:
for s in words:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + label + '\n'
f_train.write(labs)
i += 1
print("数据列表生成完成!")
print("样本最长长度:" + str(maxlen))
create_data_list(data_list_path)生成下面的文件:

- 定义训练数据集提供器
import os
import sys
import json
import torch.nn as nn
import torch
import matplotlib
import paddle
import io
import random
import numpy as np
# # 把生成的数据列表都放在自己的总类别文件夹中
data_root_path = "./"
def data_reader(file_path, phrase, shuffle=False):
all_data = []
with io.open(file_path, "r", encoding='utf8') as fin:
for line in fin:
cols = line.strip().split("\t")
if len(cols) != 2:
continue
label = int(cols[1])
wids = cols[0].split(",")
all_data.append((wids, label))
if shuffle:
if phrase == "train":
random.shuffle(all_data)
def reader():
for doc, label in all_data:
yield doc, label
return reader
class SentaProcessor(object):
def __init__(self, data_dir,):
self.data_dir = data_dir
def get_train_data(self, data_dir, shuffle):
return data_reader((self.data_dir + "train_list.txt"),
"train", shuffle)
def get_eval_data(self, data_dir, shuffle):
return data_reader((self.data_dir + "eval_list.txt"),
"eval", shuffle)
def data_generator(self, batch_size, phase='train', shuffle=True):
if phase == "train":
return paddle.batch(
self.get_train_data(self.data_dir, shuffle),
batch_size,
drop_last=True)
elif phase == "eval":
return paddle.batch(
self.get_eval_data(self.data_dir, shuffle),
batch_size,
drop_last=True)
else:
raise ValueError(
"Unknown phase, which should be in ['train', 'eval']")
def load_vocab(file_path):
fr = open(file_path, 'r', encoding='utf8')
vocab = eval(fr.read()) #读取的str转换为字典
fr.close()
return vocab
# 打印前2条训练数据
vocab = load_vocab(os.path.join(data_root_path, 'dict_data.txt'))
if "<pad>" not in vocab:
vocab["<pad>"] = len(vocab)
with open(os.path.join(data_root_path, 'dict_data.txt'), 'w', encoding='utf-8') as f:
f.write(str(vocab))
# print(vocab.keys())
def ids_to_str(ids):
words = []
for k in ids:
w = list(vocab.keys())[list(vocab.values()).index(int(k))]
words.append(w if isinstance(w, str) else w.decode('ASCII'))
return " ".join(words)
file_path = os.path.join(data_root_path, 'train_list.txt')
with io.open(file_path, "r", encoding='utf8') as fin:
i = 0
for line in fin:
i += 1
cols = line.strip().split("\t")
if len(cols) != 2:
sys.stderr.write("[NOTICE] Error Format Line!")
continue
label = int(cols[1])
wids = cols[0].split(",")
print(str(i) + ":")
print('sentence list id is:', wids)
print('sentence list is: ', ids_to_str(wids))
print('sentence label id is:', label)
print('---------------------------------')
if i == 2: break
vocab = load_vocab(os.path.join(data_root_path, 'dict_data.txt'))
class RumorDataset(paddle.io.Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir
self.all_data = []
with io.open(self.data_dir, "r", encoding='utf8') as fin:
for line in fin:
cols = line.strip().split("\t")
if len(cols) != 2:
sys.stderr.write("[NOTICE] Error Format Line!")
continue
label = []
label.append(int(cols[1]))
wids = cols[0].split(",")
if len(wids) >= 150:
wids = np.array(wids[:150]).astype('int64')
else:
wids = np.concatenate([wids, [vocab["<pad>"]] * (150 - len(wids))]).astype('int64')
label = np.array(label).astype('int64')
self.all_data.append((wids, label))
def __getitem__(self, index):
data, label = self.all_data[index]
return data, label
def __len__(self):
return len(self.all_data)
batch_size = 8
train_dataset = RumorDataset(os.path.join(data_root_path, 'train_list.txt'))
test_dataset = RumorDataset(os.path.join(data_root_path, 'eval_list.txt'))
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
test_loader = paddle.io.DataLoader(test_dataset, places=paddle.CPUPlace(), return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
# check
print('=============train_dataset =============')
for data, label in train_dataset:
print(data)
print(np.array(data).shape)
print(label)
break
print('=============test_dataset =============')
for data, label in test_dataset:
print(data)
print(np.array(data).shape)
print(label)
break
模型构建
model.py
import paddle
from paddle.nn import Conv2D, Linear, Embedding
from paddle import to_tensor
import paddle.nn.functional as F
import data_reader
class RNN(paddle.nn.Layer):
def __init__(self):
super(RNN, self).__init__()
self.dict_dim = data_reader.vocab["<pad>"]
self.emb_dim = 128
self.hid_dim = 128
self.class_dim = 2
self.embedding = Embedding(
self.dict_dim + 1, self.emb_dim,
sparse=False)
self._fc1 = Linear(self.emb_dim, self.hid_dim)
self.lstm = paddle.nn.LSTM(self.hid_dim, self.hid_dim)
self.fc2 = Linear(19200, self.class_dim)
def forward(self, inputs):
# [32, 150]
emb = self.embedding(inputs)
# [32, 150, 128]
fc_1 = self._fc1(emb)#第一层
# [32, 150, 128]
x = self.lstm(fc_1)
x = paddle.reshape(x[0], [0, -1])
x = self.fc2(x)
x = paddle.nn.functional.softmax(x)
return x
rnn = RNN()
paddle.summary(rnn,(32,150),"int64")
# class RNN(paddle.nn.Layer):
# def __init__(self):
# super(RNN, self).__init__()
# self.dict_dim = data_reader.vocab["<pad>"]
# self.emb_dim = 128
# self.hid_dim = 128
# self.class_dim = 2
# self.embedding = Embedding(
# self.dict_dim + 1, self.emb_dim, sparse=False)
# self._fc1 = Linear(self.emb_dim, self.hid_dim)
# self.lstm = paddle.nn.LSTM(self.hid_dim, self.hid_dim)
# self.fc2 = Linear(19200, self.class_dim)
# self.attention_layer = paddle.nn.Linear(self.hid_dim, 1)
# def forward(self, inputs):
# # [32, 150]
# emb = self.embedding(inputs)
# # [32, 150, 128]
# fc_1 = self._fc1(emb)
# # [32, 150, 128]
# lstm_out, (h_n, c_n) = self.lstm(fc_1)
# # [32, 150, 1]
# attn_weights = self.attention_layer(lstm_out)
# # [32, 150]
# attn_weights = paddle.nn.functional.softmax(attn_weights, axis=1)
# # [32, 128]
# attn_output = paddle.sum(lstm_out * attn_weights, axis=1)
# x = paddle.reshape(attn_output, [0, -1])
# x = self.fc2(x)
# x = F.softmax(x)
# return x
# rnn = RNN()
# paddle.summary(RNN, (32, 150), "int64")
# print(rnn)上面的代码中,前面的部分是只有LSTM实现的框架,后面注释掉的是LSTM-Attention实现的,LSTM-Attention实现的效果不太好,不知道为什么。
运行后的架构图为:

train.py
import os
import sys
import json
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
import paddle.fluid as fluid
from model import RNN
import paddle
import data_reader
import matplotlib.pyplot as plt
from PIL import Image
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
def train(model):
model.train()
opt = paddle.optimizer.Adam(learning_rate=0.002, parameters=model.parameters())
steps = 0
Iters, total_loss, total_acc = [], [], []
for epoch in range(5):
for batch_id, data in enumerate(data_reader.train_loader):
steps += 1
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
if batch_id % 50 == 0:
Iters.append(steps)
total_loss.append(loss.numpy()[0])
total_acc.append(acc.numpy()[0])
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
# evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(data_reader.test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss))
model.train()
paddle.save(model.state_dict(), "model_final.pdparams")
draw_process("trainning loss", "red", Iters, total_loss, "trainning loss")
draw_process("trainning acc", "green", Iters, total_acc, "trainning acc")
model = RNN()
train(model)
运行结果如下
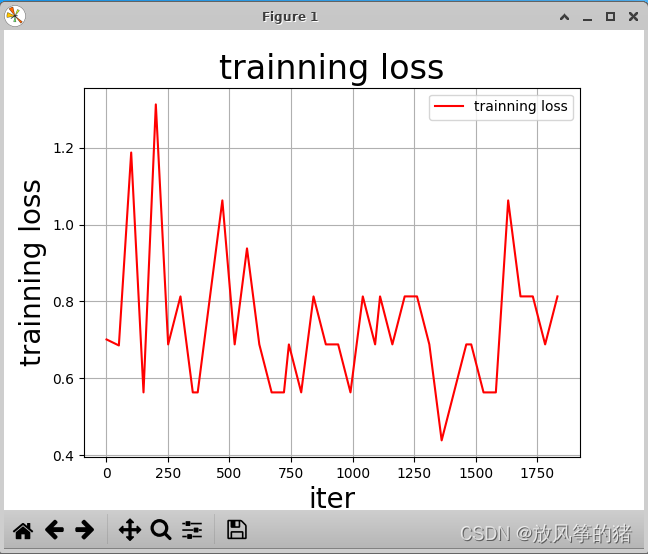
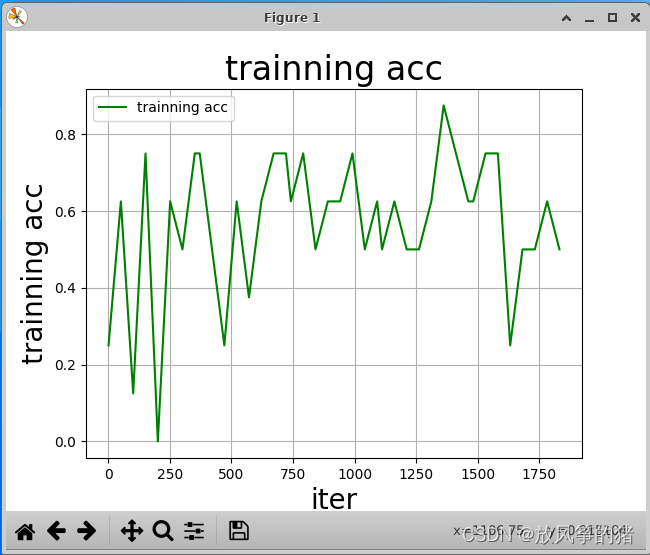
to_eval.py
import os
import sys
import json
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
import paddle.fluid as fluid
from model import RNN
import paddle
import data_reader
import matplotlib.pyplot as plt
from PIL import Image
'''
模型评估
'''
model_state_dict = paddle.load('model_final.pdparams')
model = RNN()
model.set_state_dict(model_state_dict)
model.eval()
label_map = {0: "是", 1: "否"}
samples = []
predictions = []
accuracies = []
losses = []
for batch_id, data in enumerate(data_reader.test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
for idx, probs in enumerate(logits):
# 映射分类label
label_idx = np.argmax(probs)
labels = label_map[label_idx]
predictions.append(labels)
samples.append(sent[idx].numpy())
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss))
print('数据: {} \n\n是否谣言: {}'.format(data_reader.ids_to_str(samples[0]), predictions[0]))
运行结果如下:

每次都会随机选取测试集中的一条数据进行判断
参考文章:
笔记&实践 | 基于LSTM实现谣言检测 |初识长短记忆神经网络_大数据界Olu的博客-CSDN博客
毕业设计 基于CNN实现谣言检测 - python 深度学习 机器学习_谣言检测代码_DanCheng-studio的博客-CSDN博客