一、前言
通过以下系列章节:
Spring Boot集成ShardingSphere实现数据分片(一) | Spring Cloud 40
Spring Boot集成ShardingSphere实现数据分片(二) | Spring Cloud 41
Spring Boot集成ShardingSphere实现数据分片(三) | Spring Cloud 42
Spring Boot集成ShardingSphere实现读写分离 | Spring Cloud 43
Spring Boot集成ShardingSphere实现按月数据分片及创建自定义分片算法 | Spring Cloud 44
Spring Boot集成ShardingSphere分片利器 AutoTable (一)—— 简单体验 | Spring Cloud 45
Spring Boot集成ShardingSphere分片利器 AutoTable (二)—— 自动分片算法示例 | Spring Cloud 46
ShardingSphere 5.3 系列Spring 配置升级指南 | Spring Cloud 47
Spring Boot集成ShardingSphere实现数据加密及数据脱敏 | Spring Cloud 48
Spring Boot集成ShardingSphere配合dynamic-datasource进行数据源切换 | Spring Cloud 49
对ShardingSphere的数据分片、各分片算法应用、读写分离、数据加密、数据脱敏、最新版本升级等情况有了详细的了解,今天我们继续对其ShardingSphere的另一款产品ShardingSphere-Proxy进行了解学习。
二、ShardingSphere-Proxy
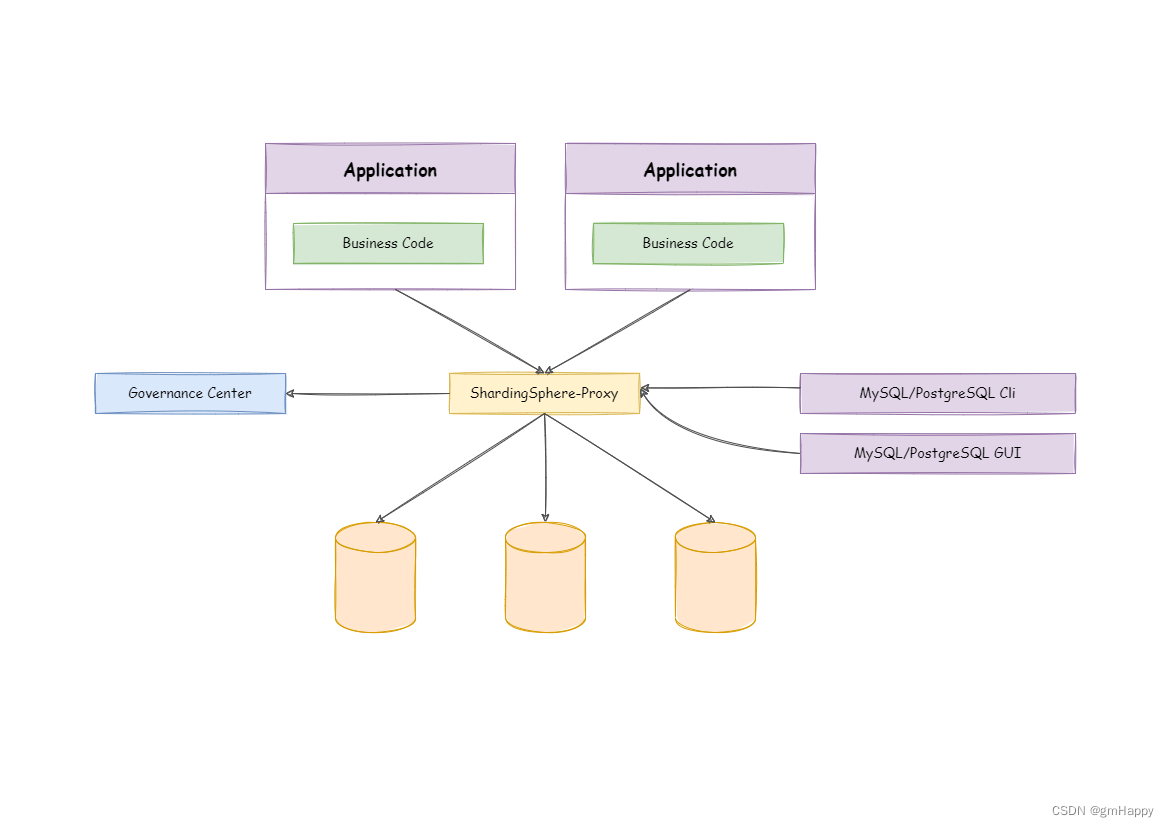
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
2.1 产品功能
| 特性 | 定义 |
|---|---|
| 数据分片 | 数据分片,是应对海量数据存储与计算的有效手段。ShardingSphere 基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储。 |
| 分布式事务 | 事务能力,是保障数据库完整、安全的关键技术,也是数据库的核心技术。基于 XA 和 BASE 的混合事务引擎,ShardingSphere 提供在独立数据库上的分布式事务功能,保证跨数据源的数据安全。 |
| 读写分离 | 读写分离,是应对高压力业务访问的手段。基于对 SQL 语义理解及对底层数据库拓扑感知能力,ShardingSphere 提供灵活的读写流量拆分和读流量负载均衡。 |
| 高可 | 用 高可用,是对数据存储计算平台的基本要求。ShardingSphere 提供基于原生或 Kubernetes 环境下数据库集群的分布式高可用能力。 |
| 数据迁移 | 数据迁移,是打通数据生态的关键能力。ShardingSphere 提供跨数据源的数据迁移能力,并可支持重分片扩展。 |
| 联邦查询 | 联邦查询,是面对复杂数据环境下利用数据的有效手段。ShardingSphere 提供跨数据源的复杂查询分析能力,实现跨源的数据关联与聚合。 |
| 数据加密 | 数据加密,是保证数据安全的基本手段。ShardingSphere 提供完整、透明、安全、低成本的数据加密解决方案。 |
| 影子库 | 在全链路压测场景下,ShardingSphere 支持不同工作负载下的数据隔离,避免测试数据污染生产环境。 |
2.2 与 ShardingSphere-JDBC 比较
| 维度 | ShardingSphere-JDBC | ShardingSphere-Proxy |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅 Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
三、部署使用
本文基于
Docker部署ShardingSphere-Proxy无须额外依赖,部署版本为5.3.2
使用二进制分发包部署ShardingSphere-Proxy,需要环境具备Java JRE 8或更高版本。
3.1 操作步骤
3.1.1 获取docker镜像
docker pull apache/shardingsphere-proxy:5.3.2
3.1.2 配置conf/server.yaml和conf/config-*.yaml
可以从
docker容器中获取配置文件模板,拷贝到宿主机任意目录中:
docker run -d --name tmp --entrypoint=bash apache/shardingsphere-proxy:5.3.2
docker cp tmp:/opt/shardingsphere-proxy/conf /root/apps/shardingsphere-proxy
docker rm tmp
由于容器内的网络环境可能与宿主机的网络环境有差异,如果启动时报无法连接到数据库错误等错误,请确保
conf/config-*.yaml配置文件中指定的数据库的ip可以被docker容器内部访问到。
3.1.3 引入数据库驱动(可选)
如果后端连接 MySQL 数据库,请下载驱动,在宿主机中任意位置创建 ext-lib 目录,并将驱动放入,且在启动容器时进行目录挂载。
3.1.4 配置conf/server.yaml
ShardingSphere-Proxy 运行模式在 server.yaml 中配置,配置格式与 ShardingSphere-JDBC 一致,请参考 模式配置。
我配置的是单机模式并开启权限:
mode:
type: Standalone
repository:
type: JDBC
authority:
users:
- user: root@%
password: root
- user: sharding
password: sharding
privilege:
type: ALL_PERMITTED
其他配置项请参考:
3.1.5 配置conf/config-*.yaml
修改宿主机conf目录下以 config- 前缀开头的文件,如:conf/config-sharding.yaml 文件,进行分片规配置。
config-*.yaml 文件的 * 部分可以任意命名。 ShardingSphere-Proxy 支持配置多个逻辑数据源,每个以 config- 前缀命名的 yaml 配置文件,即为一个逻辑数据源。
conf/config-sharding.yaml 文件示例:
databaseName: sharding_db
dataSources:
ds1:
url: jdbc:mysql://192.168.0.35:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds2:
url: jdbc:mysql://192.168.0.46:3306/db2?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
autoTables:
# 取模
t_auto_order_mod:
actualDataSources: ds$->{
1..2}
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: auto_order_mod
# 分布式序列策略
keyGenerateStrategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: order_id
# 分布式序列算法名称
keyGeneratorName: snowflake
# 散列取模
t_auto_order_hash_mod:
actualDataSources: ds1
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: auto_order_hash_mod
# 分布式序列策略
keyGenerateStrategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: order_id
# 分布式序列算法名称
keyGeneratorName: snowflake
# 容量范围
t_auto_order_volume_range:
actualDataSources: ds$->{
1..2}
shardingStrategy:
standard:
shardingColumn: price
shardingAlgorithmName: auto_order_volume_range
# 分布式序列策略
keyGenerateStrategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: order_id
# 分布式序列算法名称
keyGeneratorName: snowflake
# 边界范围
t_auto_order_boundary_range:
actualDataSources: ds$->{
1..2}
shardingStrategy:
standard:
shardingColumn: price
shardingAlgorithmName: auto_order_boundary_range
# 分布式序列策略
keyGenerateStrategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: order_id
# 分布式序列算法名称
keyGeneratorName: snowflake
# 自动日期间隔
t_auto_order_auto_interval:
actualDataSources: ds$->{
1..2}
shardingStrategy:
standard:
shardingColumn: create_time
shardingAlgorithmName: auto_order_auto_interval
# 分布式序列策略
keyGenerateStrategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: order_id
# 分布式序列算法名称
keyGeneratorName: snowflake
# 分片算法配置
shardingAlgorithms:
# 取模
auto_order_mod:
type: MOD
props:
sharding-count: 6
# 散列取模
auto_order_hash_mod:
type: HASH_MOD
props:
sharding-count: 6
# 容量范围
auto_order_volume_range:
type: VOLUME_RANGE
props:
range-lower: 0
range-upper: 20000
sharding-volume: 10000
# 边界范围
auto_order_boundary_range:
type: BOUNDARY_RANGE
props:
sharding-ranges: 10,15,100,12000,16000
# 自动日期间隔
auto_order_auto_interval:
type: AUTO_INTERVAL
props:
datetime-lower: "2023-05-07 00:00:00"
datetime-upper: "2023-05-10 00:00:00"
sharding-seconds: 86400
# 分布式序列算法配置(如果是自动生成的,在插入数据的sql中就不要传id,null也不行,直接插入字段中就不要有主键的字段)
keyGenerators:
# 分布式序列算法名称
snowflake:
# 分布式序列算法类型
type: SNOWFLAKE
此处配置采用自动分配算法,具体使用说明请参考:Spring Boot集成ShardingSphere分片利器 AutoTable (二)—— 自动分片算法示例 | Spring Cloud 46
3.1.6 启动 ShardingSphere-Proxy容器
version: "3.8"
# 通用日志设置
x-logging:
&default-logging
# 日志大小和数量
options:
max-size: "100m"
max-file: "3"
# 文件存储类型
driver: json-file
services:
shardingsphere-proxy:
image: apache/shardingsphere-proxy:5.3.2
container_name: shardingsphere-proxy
environment:
- PORT=3308
- JAVA_OPTS=XX:InitialRAMPercentage=80.0 -XX:MaxRAMPercentage=80.0 -XX:MinRAMPercentage=80.0
volumes:
- /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime #设置系统时区
- /root/apps/shardingsphere-proxy/conf:/opt/shardingsphere-proxy/conf
- /root/apps/shardingsphere-proxy/ext-lib:/opt/shardingsphere-proxy/ext-lib
ports:
- "13308:3308"
restart: always
logging: *default-logging
其中,
ext-lib非必需,用户可按需挂载。ShardingSphere-Proxy默认端口3307,可以通过环境变量-e PORT指定。 自定义JVM相关参数可通过环境变量JVM_OPTS设置。
3.2 连接示例
3.2.1 使用客户端连接ShardingSphere-Proxy
执行 MySQL/PostgreSQL/openGauss 的客户端命令直接操作 ShardingSphere-Proxy 即可。
使用 MySQL 客户端连接 ShardingSphere-Proxy:
mysql -h${proxy_host} -P${proxy_port} -u${proxy_username} -p${proxy_password}
使用 PostgreSQL 客户端连接 ShardingSphere-Proxy:
psql -h ${proxy_host} -p ${proxy_port} -U ${proxy_username}
使用 openGauss 客户端连接 ShardingSphere-Proxy:
gsql -r -h ${proxy_host} -p ${proxy_port} -U ${proxy_username} -W ${proxy_password}
3.2.2 使用Navicat连接ShardingSphere-Proxy
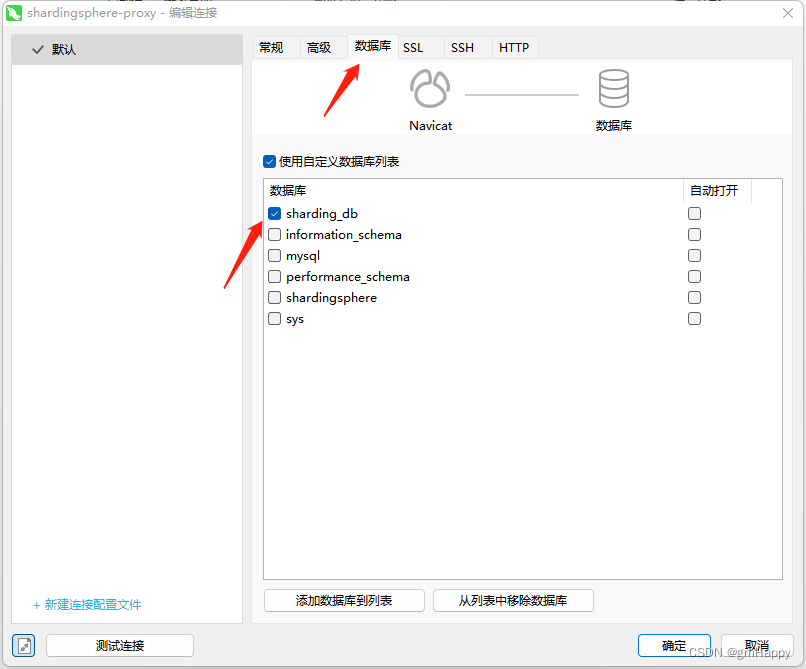
请在数据标签栏勾选对应的逻辑数据库,其中sharding_db是逻辑数据库名称,由config-sharding.yaml中定义。
3.3 常规使用
对上述定义分片规则的逻辑表可正常进行CRUD操作。
3.4 DistSQL
3.4.1 定义
DistSQL(Distributed SQL)是 Apache ShardingSphere 特有的操作语言。 它与标准 SQL 的使用方式完全一致,用于提供增量功能的 SQL 级别操作能力。
灵活的规则配置和资源管控能力是 Apache ShardingSphere 的特点之一。
在使用 4.x 及其之前版本时,开发者虽然可以像使用原生数据库一样操作数据,但却需要通过本地文件或注册中心配置资源和规则。然而,操作习惯变更,对于运维工程师并不友好。
从 5.x 版本开始,DistSQL(Distributed SQL)让用户可以像操作数据库一样操作 Apache ShardingSphere,使其从面向开发人员的框架和中间件转变为面向运维人员的数据库产品。
3.4.2 相关概念
DistSQL 细分为 RDL、RQL、RAL 和 RUL 四种类型:
-
RDL
Resource & Rule Definition Language,负责资源和规则的创建、修改和删除。 -
RQL
Resource & Rule Query Language,负责资源和规则的查询和展现。 -
RAL
Resource & Rule Administration Language,负责强制路由、熔断、配置导入导出、数据迁移控制等管理功能。 -
RUL
Resource & Rule Utility Language,负责 SQL 解析、SQL 格式化、执行计划预览等功能。
3.4.3 对系统的影响
- 之前
在拥有 DistSQL 以前,用户一边使用 SQL 语句操作数据,一边使用 YAML 文件来管理 ShardingSphere 的配置,如下图:
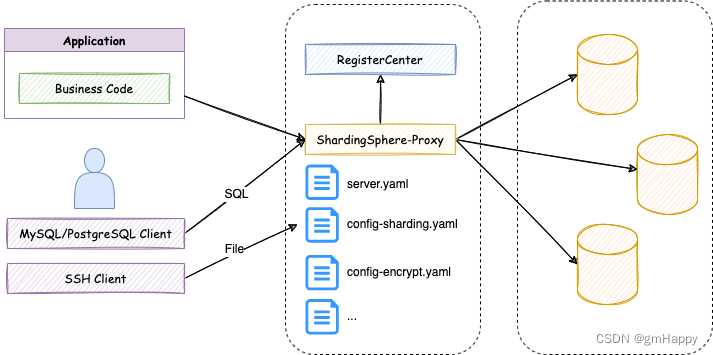
这时用户不得不面对以下几个问题:
-
需要通过不同类型的客户端来操作数据和管理
ShardingSphere规则; -
多个逻辑库需要多个
YAML文件; -
修改
YAML需要文件的编辑权限; -
修改
YAML后需要重启ShardingSphere。 -
之后
随着 DistSQL 的出现,对 ShardingSphere 的操作方式也得到了改变:
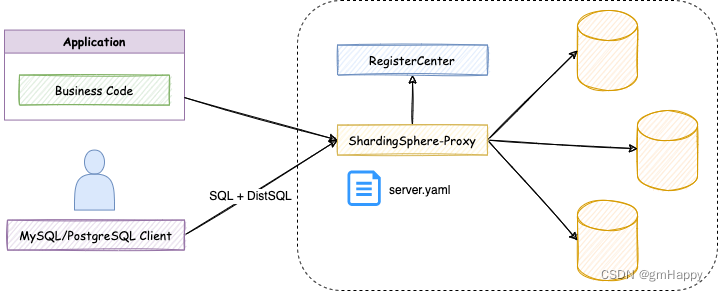
现在,用户的使用体验得到了巨大改善:
- 使用相同的客户端来管理数据和
ShardingSphere配置; - 不再额外创建
YAML文件,通过DistSQL管理逻辑库; - 不再需要文件的编辑权限,通过
DistSQL来管理配置; - 配置的变更实时生效,无需重启
ShardingSphere。
使用限制:
DistSQL只能用于ShardingSphere-Proxy,ShardingSphere-JDBC暂不提供。