文章目录
零拷贝技术前世
数据的四次拷贝与四次上下文切换
很多应用程序在面临客户端请求时,可以等价为进行如下的系统调用:
File.read;
Socket.send;
例如消息中间件 Kafka 就是这个应用场景,从磁盘中读取一批消息后原封不动地写入网卡(NIC,Network interface controller)进行发送。
在没有任何优化技术使用的背景下,操作系统为此会进行 4 次数据拷贝,以及 4 次上下文切换,如下图所示:
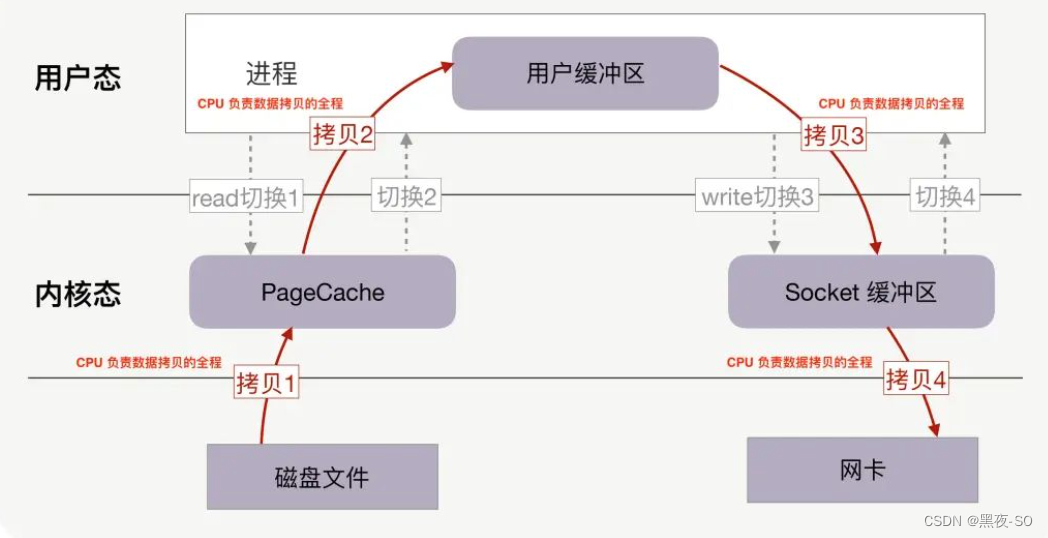
如果没有优化,读取磁盘数据,再通过网卡传输的场景性能比较差:
4 次 copy
物理设备 <-> 内存:
CPU 负责将数据从磁盘搬运到内核空间的 Page Cache 中;
CPU 负责将数据从内核空间的 Socket 缓冲区搬运到的网络中;
内存内部拷贝:
CPU 负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区;
CPU 负责将数据从用户空间的缓冲区搬运到内核空间的 Socket 缓冲区中;
4 次上下文切换
read 系统调用时:用户态切换到内核态;
read 系统调用完毕:内核态切换回用户态;
write 系统调用时:用户态切换到内核态;
write 系统调用完毕:内核态切换回用户态;
弊端
我们不免发出抱怨:
1、CPU 全程负责内存内部的数据拷贝还可以接受,因为内存的数据拷贝效率还行(不过还是比 CPU 慢很多),但是如果要 CPU 全程负责内存与磁盘、内存与网卡的数据拷贝,这将难以接受,因为磁盘、网卡的 I/O 速度远小于内存;
2、4 次 copy 太多了,4 次上下文切换也太频繁了;
零拷贝诞生准备–DMA技术
DMA 参与下的数据四次拷贝
DMA 技术很容易理解,本质上,DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
DMAC 的价值在如下情况中尤其明显:当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用 CPU 来搬运的话,肯定忙不过来,所以可以选择 DMAC。而当数据传输很慢的时候,DMAC 可以等数据到齐了,再发送信号,给到 CPU 去处理,而不是让 CPU 在那里忙等待。
注意 :这里面的“协”字。DMAC 是在“协助”CPU,完成对应的数据传输工作。在 DMAC 控制数据传输的过程中,DMAC 还是被 CPU 控制,只是数据的拷贝行为不再由 CPU 来完成。
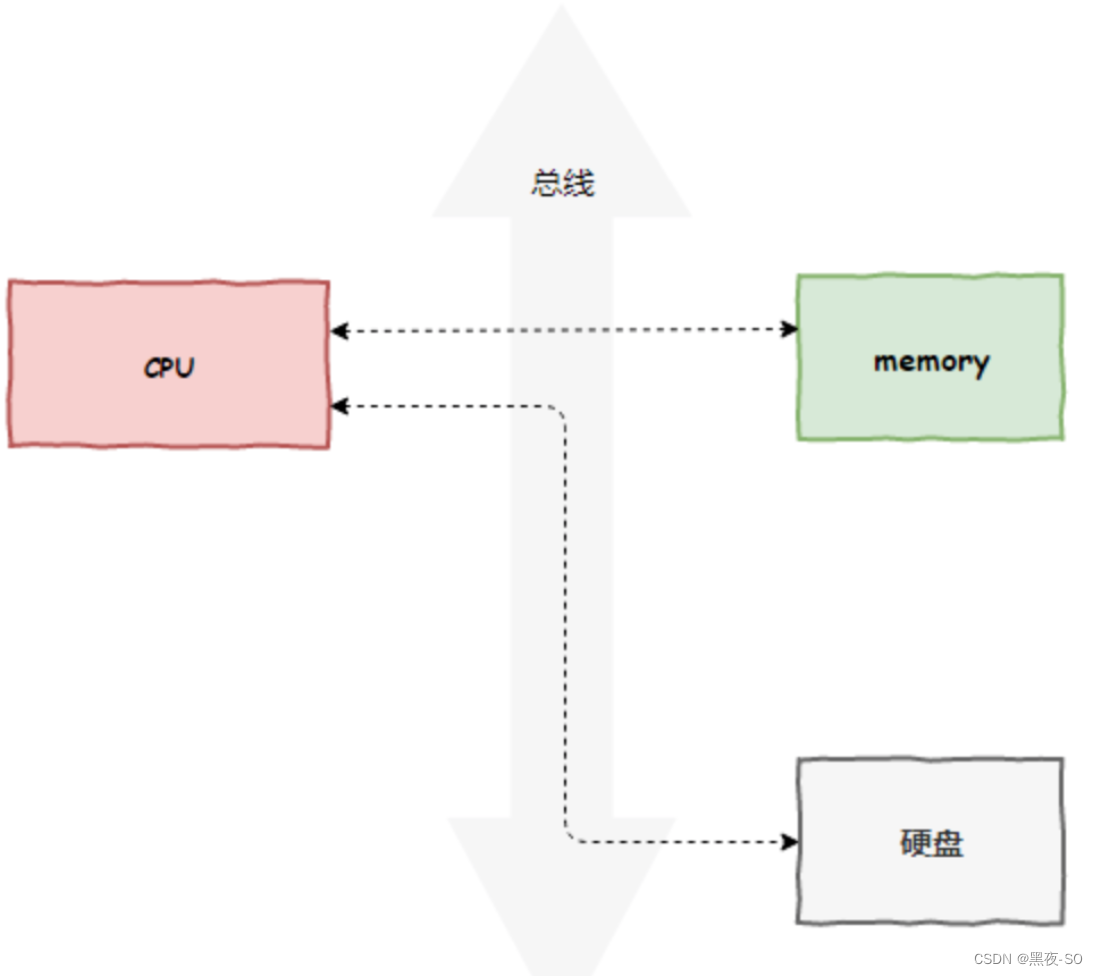
原本,计算机所有组件之间的数据拷贝(流动)必须经过 CPU。以磁盘读写为例,如下图所示:
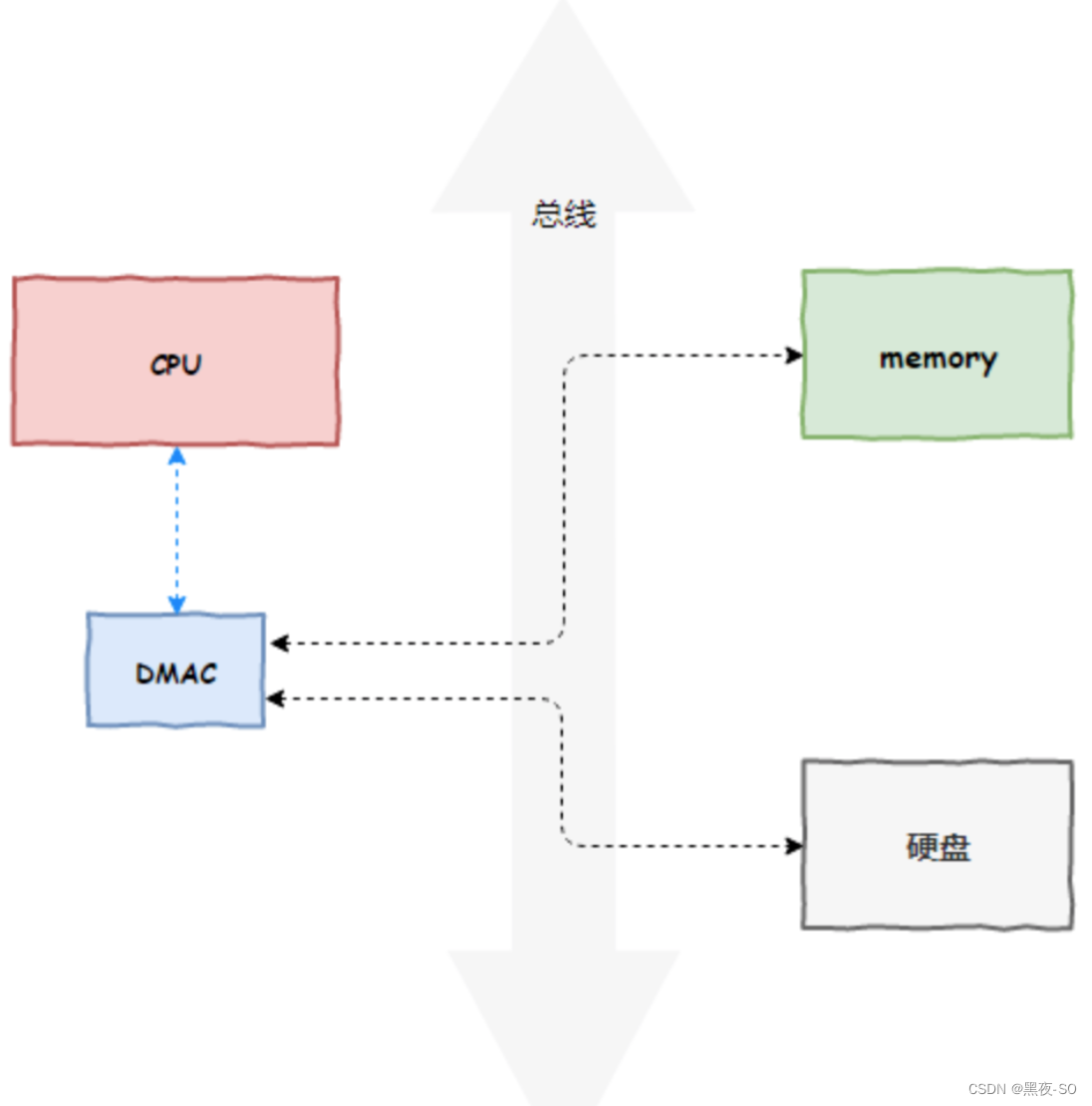
现在,DMAC 代替了 CPU 负责内存与磁盘、内存与网卡之间的数据搬运,CPU 作为 DMAC 的控制者,如下图所示:
但是 DMAC 有其局限性,DMAC 仅仅能用于设备间 交换数据时进行数据拷贝,但是计算机内核内部的数据拷贝还需要 CPU 来亲力亲为 。例如, CPU 需要负责内核空间与用户空间之间的数据拷贝(内存内部的拷贝),如下图所示:
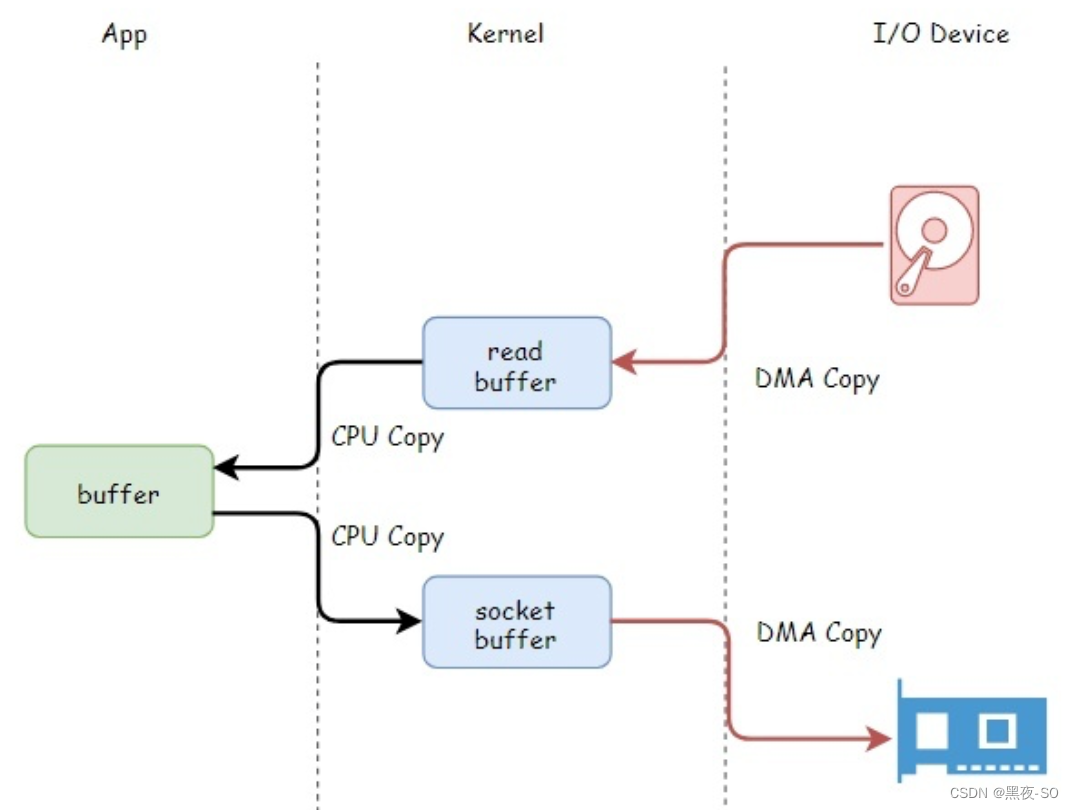
上图中的 read buffer 也就是 page cache,socket buffer 也就是 Socket 缓冲区。
零拷贝诞生
零拷贝技术
什么是零拷贝技术?
零拷贝技术是一个思想,指的是指计算机执行操作时,CPU 不全程负责先将数据从某处内存复制到另一个特定区域。
可见,零拷贝的特点是 CPU 不全程负责内存中的数据写入其他组件,CPU 仅仅起到管理的作用。但注意,零拷贝不是不进行拷贝,而是 CPU 不再全程负责数据拷贝时的搬运工作。如果数据本身不在内存中,那么必须先通过某种方式拷贝到内存中(这个过程 CPU 可以仅仅负责管理,DMAC 来负责具体数据拷贝),因为数据只有在内存中,才能被转移,才能被 CPU 直接读取计算。
零拷贝的实现方式
零拷贝技术的具体实现方式有很多,例如:
*sendfile
*mmap
- Direct I/O
*splice
不同的零拷贝方式适用于不同的应用场景,下面依次进行 sendfile、mmap、Direct I/O 的分析。
技术总结
不过,我们不妨先在这里做一个前瞻性的技术总结。
1、DMA 技术
DMA 负责内存与其他组件之间的数据拷贝,CPU 仅需负责管理,而无需负责全程的数据拷贝;
2、使用 page cache 的 zero copy:
2.1、sendfile:一次代替 read/write 系统调用,通过使用 DMA 技术以及传递文件描述符,实现了 zero copy
2.2、mmap:仅代替 read 系统调用,将内核空间地址映射为用户空间地址,write 操作直接作用于内核空间。通过 DMA 技术以及地址映射技术,用户空间与内核空间无须数据拷贝,实现了 zero copy
3、不使用 page cache 的 zero copy:
Direct I/O:读写操作直接在磁盘上进行,不使用 page cache 机制,通常结合用户空间的用户缓存使用。通过 DMA 技术直接与磁盘/网卡进行数据交互,实现了 zero copy
sendfile
Linux 在版本 2.1 中引入了 sendfile() 这个系统调用,sendfile()是一种零拷贝的实现。Java对sendfile的支持就是NIO中的FileChannel.transferTo()或者transferFrom()。
snedfile 的应用场景是:用户从磁盘读取一些文件数据后不需要经过任何计算与处理就通过网络传输出去 。此场景的典型应用是消息队列。
在传统 I/O 下,正如上面所示,上述应用场景的一次数据传输需要四次 CPU 全权负责的拷贝与四次上下文切换,正如本文第一节所述。
sendfile 主要使用到了两个技术:
1、DMA 技术;
2、传递文件描述符代替数据拷贝;
下面依次讲解这两个技术的作用。
利用 DMA 技术
sendfile 依赖于 DMA 技术,将四次 CPU 全程负责的拷贝与四次上下文切换减少到两次,如下图所示:
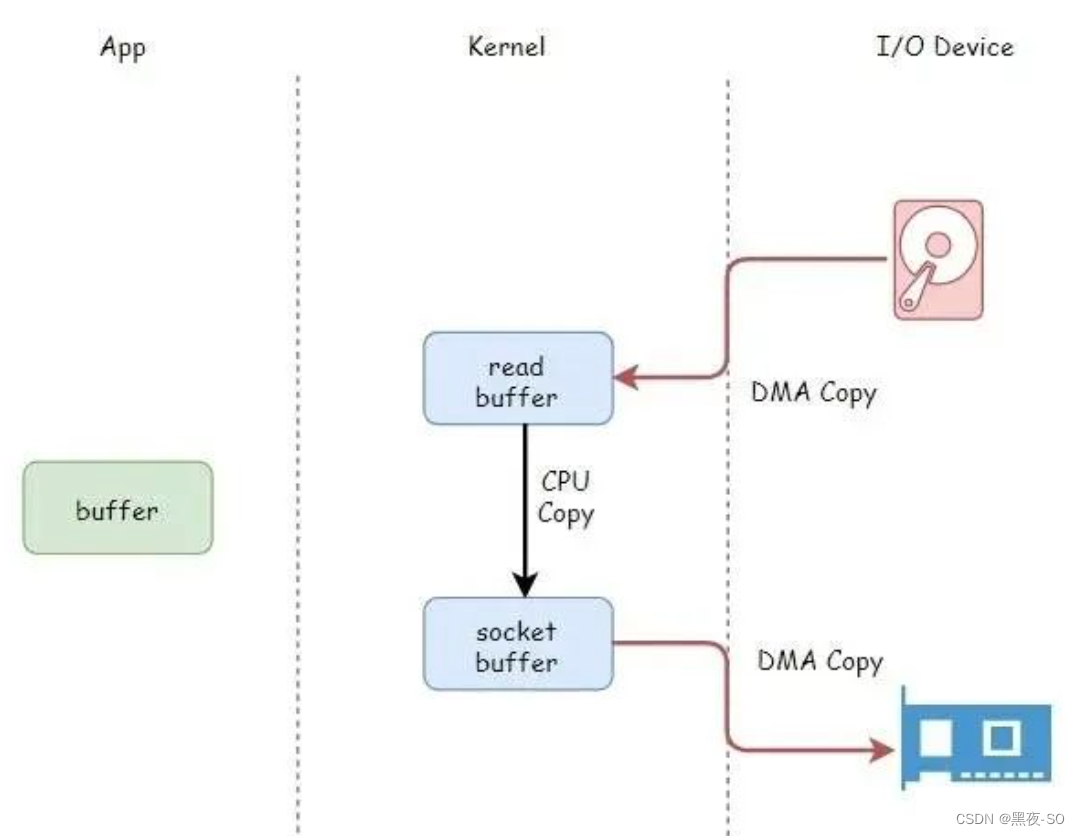
利用 DMA 技术减少 2 次 CPU 全程参与的拷贝
DMA 负责磁盘到内核空间中的 Page cache(read buffer)的数据拷贝以及从内核空间中的 socket buffer 到网卡的数据拷贝。
传递文件描述符代替数据拷贝
传递文件描述可以代替数据拷贝,这是由于两个原因:
1、page cache 以及 socket buffer 都在内核空间中;
2、数据在传输中没有被更新;
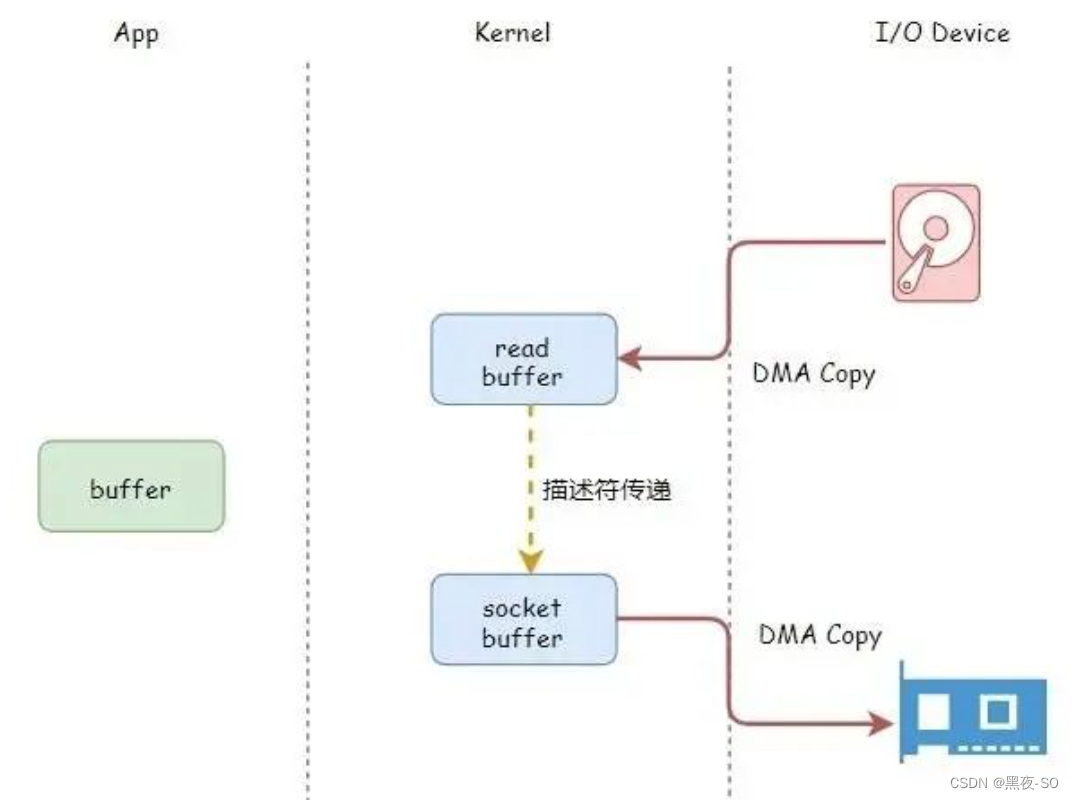
利用传递文件描述符代替内核中的数据拷贝
注意事项
只有网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术才可以通过传递文件描述符的方式避免内核空间内的一次 CPU 拷贝。这意味着此优化取决于 Linux 系统的物理网卡是否支持(Linux 在内核 2.4 版本里引入了 DMA 的 scatter/gather – 分散/收集功能,只要确保 Linux 版本高于 2.4 即可)。
一次系统调用代替两次系统调用
由于 sendfile 仅仅对应一次系统调用,而传统文件操作则需要使用 read 以及 write 两个系统调用。
正因为如此,sendfile 能够将用户态与内核态之间的上下文切换从 4 次降到 2 次。
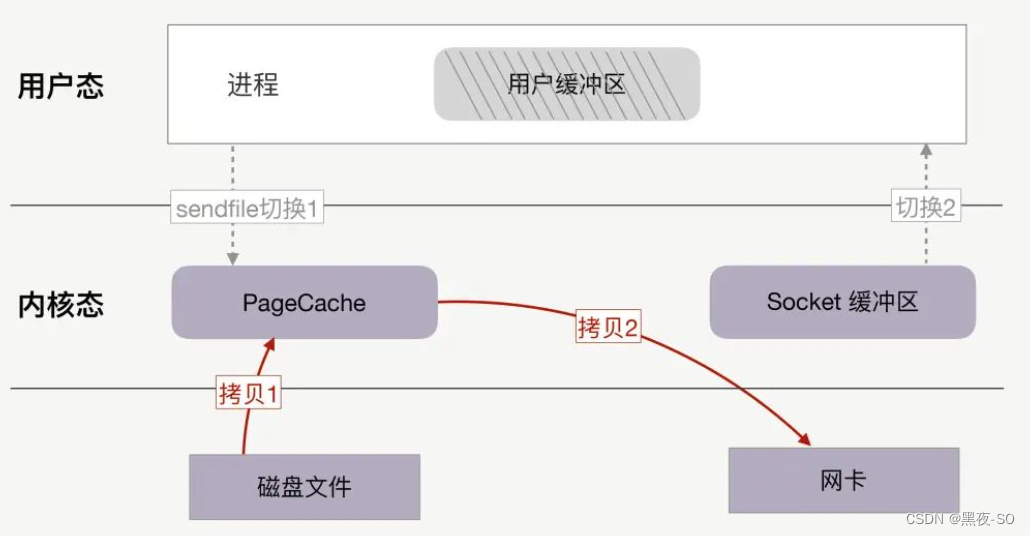
sendfile 系统调用仅仅需要两次上下文切换
另一方面,我们需要注意 sendfile 系统调用的局限性。如果应用程序需要对从磁盘读取的数据进行写操作,例如解密或加密,那么 sendfile 系统调用就完全没法用。这是因为用户线程根本就不能够通过 sendfile 系统调用得到传输的数据。
mmap
定义
mmap(Memory Mapped Files)是一种零拷贝技术,学名内存映射文件,Java中的实现就是MappedByteBuffer,通过channel#map方法得到。
mmap将一个文件(或者文件的一部分)映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间地址的一一对映关系。注意这时候没有分配和映射到具体的物理内存空间,而是到第一次加载这个文件的时候,通过MMU把之前虚拟地址换算成物理地址,把文件加载进物理内存——内核空间的Page Cache中。
实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read,write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
简单的说,使用mmap之后,数据无需拷贝到用户空间中,应用程序可以直接操作Page Cache中的数据。
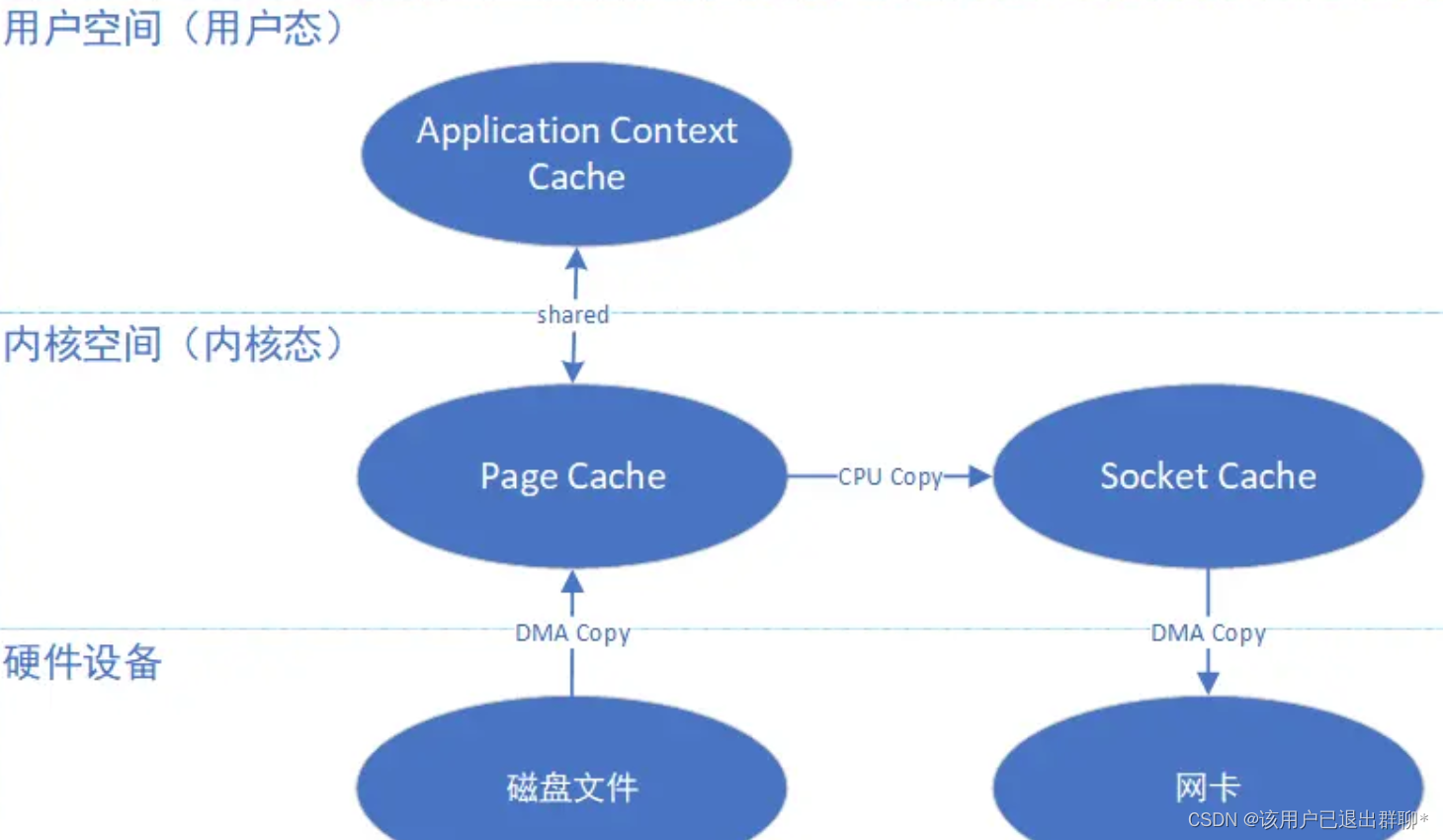
优缺点
这种mmap+write的方式相比于传统IO少了一次CPU Copy,从而极大地提高了效率。虽然性能弱于sendfile零拷贝,但其好处是可以在中途修改内存中的数据之后再传输。
另外,==支持修改数据后的持久化。==当应用程序往 mmap 输出数据时,此时就直接输出到了内核态的缓冲区数据,如果此时输出设备是磁盘的话,不会立即写磁盘,linux系统下通常会间隔是30秒由操作系统自动落盘,也可手动调用fsync()函数让其立即落盘,实现真正的持久化。
Direct I/O
定义
Direct I/O 即直接 I/O。其名字中的”直接”二字用于区分使用 page cache 机制的缓存 I/O。
- 缓存文件 I/O:用户空间要读写一个文件并不直接 与磁盘交互,而是中间夹了一层缓存,即 page cache;
- 直接文件 I/O:用户空间读取的文件直接 与磁盘交互,没有中间 page cache 层;
“直接”在这里还有另一层语义:其他所有技术中,数据至少需要在内核空间存储一份,但是在 Direct I/O 技术中,数据直接存储在用户空间中,绕过了内核。
Direct I/O 模式如下图所示:
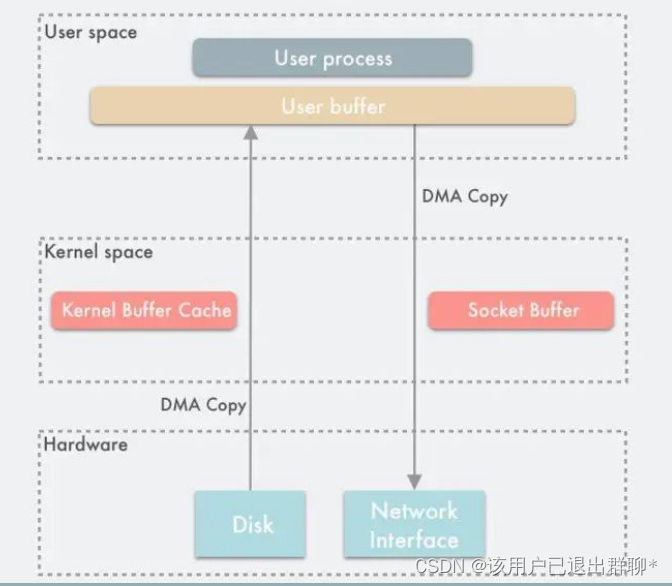
此时用户空间直接通过 DMA 的方式与磁盘以及网卡进行数据拷贝。
Direct I/O 的读写非常有特点 :
Write 操作:由于其不使用 page cache,所以其进行写文件,如果返回成功,数据就真的落盘了(不考虑磁盘自带的缓存);
Read 操作:由于其不使用 page cache,每次读操作是真的从磁盘中读取,不会从文件系统的缓存中读取。
事实上,即使 Direct I/O 还是可能需要使用操作系统的 fsync 系统调用。为什么?
这是因为虽然文件的数据本身没有使用任何缓存,但是文件的元数据仍然需要缓存,包括 VFS 中的 inode cache 和 dentry cache 等。
在部分操作系统中,在 Direct I/O 模式下进行 write 系统调用能够确保文件数据落盘,但是文件元数据不一定落盘。如果在此类操作系统上,那么还需要执行一次 fsync 系统调用确保文件元数据也落盘。否则,可能会导致文件异常、元数据确实等情况。MySQL 的 O_DIRECT 与 O_DIRECT_NO_FSYNC 配置是一个具体案例[9]。
优缺点
优点
-
Linux 中的直接 I/O 技术省略掉缓存 I/O 技术中操作系统内核缓冲区的使用,数据直接在应用程序地址空间和磁盘之间进行传输,从而使得自缓存应用程序可以省略掉复杂的系统级别的缓存结构,而执行程序自己定义的数据读写管理,从而降低系统级别的管理对应用程序访问数据的影响 。
-
与其他零拷贝技术一样,避免了内核空间到用户空间的数据拷贝,如果要传输的数据量很大,使用直接 I/O 的方式进行数据传输,而不需要操作系统内核地址空间拷贝数据操作的参与,这将会大大提高性能。
缺点
- 由于设备之间的数据传输是通过 DMA 完成的,因此用户空间的数据缓冲区内存页必须进行 page pinning(页锁定) ,这是为了防止其物理页框地址被交换到磁盘或者被移动到新的地址而导致 DMA 去拷贝数据的时候在指定的地址找不到内存页从而引发缺页错误,而页锁定的开销并不比 CPU 拷贝小,所以为了避免频繁的页锁定系统调用,应用程序必须分配和注册一个持久的内存池,用于数据缓冲。
- 如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。
- 在应用层引入直接 I/O 需要应用层自己管理,这带来了额外的系统复杂性。
如何使用 Direct I/O
用户应用需要实现用户空间内的缓存区,读/写操作应当尽量通过此缓存区提供。如果有性能上的考虑,那么尽量避免频繁地基于 Direct I/O 进行读/写操作。
应用
Kafka
-
生产者写入消息使用mmap方式。数据从Producer到Broker,需要将来自网卡的消息持久化的磁盘中,Kafka中采用mmap的方式写,并且不会立即持久化到磁盘中,而是存入page cache内核缓冲区中就直接返回成功。后续有消费者来拉取消息的时候,也是先冲缓冲区中查找消息,如果有就直接发送给消费者,不会再查找磁盘,又提升了拉消息的性能。实际上它的日志文件并没有用到 mmap,而索引文件用了 mmap。
-
消费者读取消息使用sendfile方式。 数据从Broker到Consumer,需要将磁盘中的消息通过网卡发送出去,Kafka中采用sendfile的方式,将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。
RocketMQ
无论是消息存储还是消费,都是采用mmap的方式,并且通过预热来减少大文件 mmap 因为缺页中断产生的性能问题。