如果我们要将一个文件通过 socket 发送出去,我们一般会这样写:
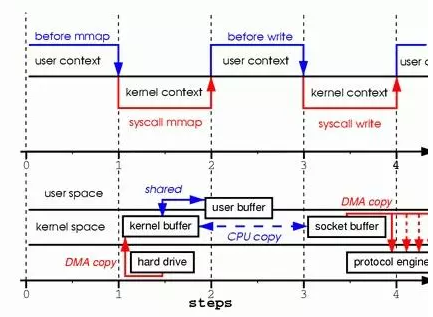
Socket socket = new Socket(); socket.connect(new InetSocketAddress("127.0.0.1", 33456),10 * 1000); DataOutputStream dout = new DataOutputStream(socket.getOutputStream()); File file = new File("E:\\TU\\DSCF0320.JPG"); FileInputStream fin = new FileInputStream(file); byte[] sendByte = new byte[1024]; dout.writeUTF(file.getName()); int length; while((length = fin.read(sendByte, 0, sendByte.length))>0){ dout.write(sendByte,0,length); dout.flush(); }
sendByte 是用户空间中的缓冲区,是 JVM 中的一块空间。
length = fin.read(sendByte, 0, sendByte.length))>0 这一句,os 将文件从硬盘读取到标准 IO 库开辟的内核缓冲区,这一过程是阻塞的。一旦读取数据到内核缓冲区的动作完成,设别管理器或者是更高层的DMA或通道发送中断,中断处理程序唤醒相关线程,使得 read 函数继续执行,执行将数据从内核缓冲区拷贝到用户缓冲区也就是 sendByte 的过程。
dout.write(sendByte,0,length) 这一句,write 函数将数据从用户缓冲区也就是 sendByte 拷贝到内核缓冲区中的输出缓冲区,内核中的协议栈将在合适的时机(行缓冲、满缓冲或不缓冲)将输出缓冲区的数据发送到网卡。
上述拷贝过程是充分的考虑了硬件管理效率、系统调用效率等因素。之所以将数据从磁盘读取到内核空间缓冲区而不是直接读取到用户空间缓冲区,是为了减少磁盘I/O操作以此来提高性能。因为OS会根据局部性原理在一次read()系统调用的时候预读取更多的文件数据到内核空间缓冲区中,这样当下一次read()系统调用的时候发现要读取的数据已经存在于内核空间缓冲区中的时候只要直接拷贝数据到用户空间缓冲区中即可,无需再进行一次低效的磁盘I/O操作,磁盘I/O操作的速度比直接访问内存慢了好几个数量级,同时频繁的访问磁盘会降低硬件的使用寿命。而像 BufferedInputStream 等 JVM 或者说应用层面的缓冲区的作用是,为我们预取更多的数据到它自己维护的一个内部字节数据缓冲区中,来减少系统调用的次数以此来提供性能。
缓冲区的作用都是通过预读来减少调用次数,内核缓冲区存在的意义是减少硬件驱动程序的调用次数,用户缓冲区存在的意义是减少系统调用的次数。虽然这种方案已经非常合理和完善,但在一些特殊场景下依然存在一些弊端,比如文件传输的场景。仔细看上面的过程中,数据从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区,这两次搬移就显得比较多余,应该有优化的余地。
另外,从硬盘到内核缓冲区/从内核缓冲区到网卡的动作是内存与外设的交互,我们底层的硬件有 DMA 或 通道 等专门的 IO 管理设备可以代替 CPU 做这些工作,将 CPU 从简单的输入输出中解放出来。CPU 只需要向它们发送指令就可以将线程挂起去做其它事情,等待它们完成工作后发送中断再做后续处理即可,也就是说 内核空间 与 外设 的交互占用的 CPU 的计算资源是很少的。但上面标红的两次交互,是内核缓冲区与用户缓冲区的交互,也就是内存与内存的交互,这就必须要 CPU 亲力亲为,一个字节一个字节的搬运了,将会占用更多的 CPU 资源。
其次,内核缓冲区与用户缓冲区之间的数据传递一定会涉及到系统调用,即造成处理器在用户态与内核态之间的切换,众所周知,这是一个非常耗时的动作。
整个交互过程如下图所示:
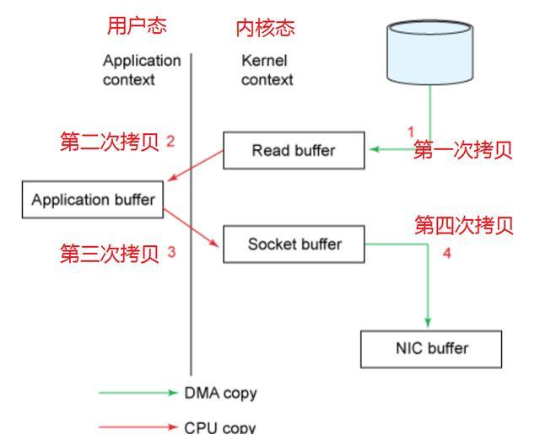
zeroCopy 技术解决了 2,3 两次多余拷贝的问题,使用 zeroCpoy 技术,我们可以将数据在内核缓冲区之间传输,而不经过用户空间。当然,既然是在内核空间进行传递,必须由 OS 支持,通过系统调用来完成。在linux 2.1内核中,添加了 “数据被copy到socket buffer”的动作,我们的 javaNIO,可以通过直接调用transferTo()的方法来使用这项技术。优化后的调用过程如下:
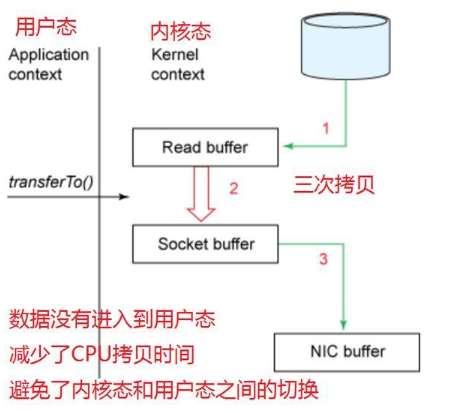
数据直接从内核缓冲区中 IO 文件流的输入缓冲区拷贝到了 socket 对应的输出缓冲区,虽然这一步依然需要 CPU 亲力亲为,但比起原始的 IO 传输方式效率已经得到了极大的提升。但即使这样,内核开发人员还是想办法将这一步 CPU 拷贝优化掉了,我们又有了更高效的传输方式:

DMA引擎将 IO 文件流输入缓冲区中的数据直接传输到了 协议栈引擎,从Linux 2.4版本开始,操作系统底层提供了带有scatter/gather的DMA来从内核空间缓冲区中将数据读取到协议引擎中。至此,整个传输过程便没有了 CPU 直接进行的数据传输动作,都是委托 DMA 或 通道 来完成的。这便是零拷贝技术。零拷贝技术下,CPU 直接进行数据传输的动作次数为0,数据在内核空间与用户空间之间的传输次数为0。
zeroCopy 是一种技术理念,其实现有多种方式:
① 直接 I/O:对于这种数据传输方式来说,应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输。这种方式依旧存在用户空间和内核空间的上下文切换,但是硬件上的数据不会拷贝一份到内核空间,而是直接拷贝至了用户空间,因此直接I/O不存在内核空间缓冲区和用户空间缓冲区之间的数据拷贝。
② 在数据传输过程中,避免数据在用户空间缓冲区和系统内核空间缓冲区之间的CPU拷贝,以及数据在系统内核空间内的CPU拷贝。上面主要讨论的就是该方式下的零拷贝机制。
③ copy-on-write(写时复制技术):在某些情况下,Linux操作系统的内核空间缓冲区可能被多个应用程序所共享,操作系统有可能会将用户空间缓冲区地址映射到内核空间缓存区中。当应用程序需要对共享的数据进行修改的时候,才需要真正地拷贝数据到应用程序的用户空间缓冲区中,并且对自己用户空间的缓冲区的数据进行修改不会影响到其他共享数据的应用程序。所以,如果应用程序不需要对数据进行任何修改的话,就不会存在数据从系统内核空间缓冲区拷贝到用户空间缓冲区的操作。