零拷贝
文章目录
前言
零拷贝在很多地方都有用到,比如netty、kafka、rabbitMQ中,那为什么会需要用到零拷贝呢?我们今天来看一下原因。
IO基本原理
内核态与用户态
现代操作系统中,由于系统资源(CPU、内存、硬盘)可能同时被多个应用程序访问,如果不加保护,那各个应用程序之间可能会产生冲突,对于恶意应用程序更可能导致系统奔溃。
比如说,没有保护的情况下,可以访问任意内存空间,如果把一些内容写到某个系统运行的重要程序中,就有可能导致系统崩溃。
所以操作系统为了避免用户直接操作内核,保证内核的安全,将内存分为了两个空间:用户空间和内核空间。所对应的,内核程序运行在内核空间的进程称为内核态,用户程序运行在用户空间的进程的状态分为了用户态。
而内核程序既有权限访问受保护的内核空间,又有权限访问硬件设备;而处于用户空间的用户程序并没有这样的权限。应用程序(处于用户空间的用户程序)无法直接调用内核程序定义的函数,也无法直接在内核空间中进行读写。
系统调用
系统调用就是操作系统实现的所有系统调用所构成的集合即程序接口或应用编程接口,是应用程序同系统之间的接口。
比如,我们平时在IDE中会写一些读写磁盘中内容的程序,而在IDE中的程序是属于用户空间中的程序,运行之后,其对应的进程处于用户态,但是处于用户空间无法读取到内核空间中的数据,并且需要依靠内核中的读写程序才能真正读取到数据,而由于处于用户态的程序无法直接调用内核空间的内核程序,所以需要从用户态转换到内核态,进行调用读写的内核函数,而这一调用过程也称为系统调用。
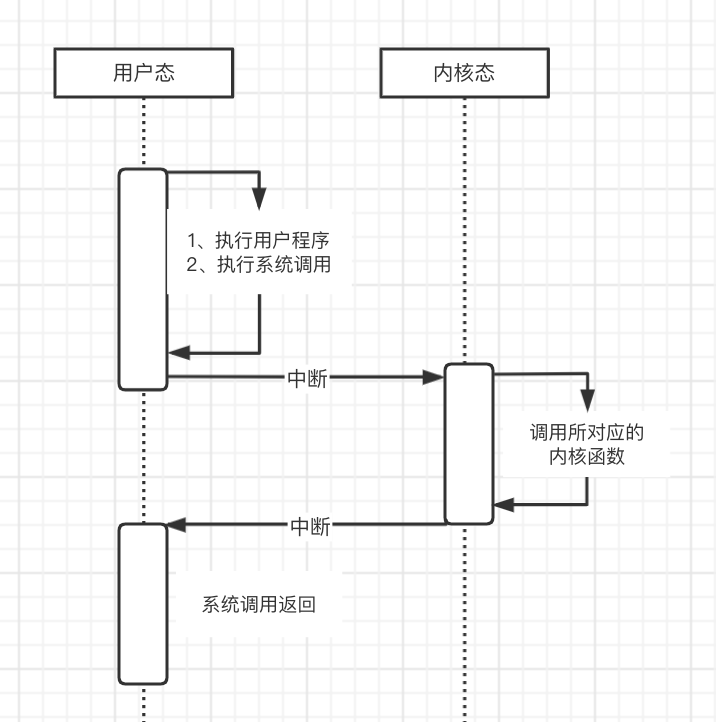
系统调用过程:
- 首先是用户态执行用户程序
- 程序中可能有些会用到系统调用,如读磁盘操作
- 然后会执行一个TRAP(陷入)指令,这个指令的作用就是:中断,从用户态进入到内核态
- 在内核态中调用所需的操作系统的内核函数
- 内核程序处理完之后,主动触发中断,系统调用返回,把CPU执行权限还给用户程序,继续执行用户程序
缓冲区
从上文我们可以知道,而从用户态切换到内核态的过程需要中断,而中断就意味着要保存当前运行的进程的数据和状态等信息,然后中断结束后要恢复之前运行的那个进程的数据和状态等信息。
而为了减少中断所带来的耗时,最简单的想法就是减少中断的次数,前辈们也很聪明,发明了缓冲区的概念。
进程缓冲区和内核缓冲区
而缓冲区又分成了进程缓冲区和内核缓冲区。
注:下图箭头所指为数据流向。
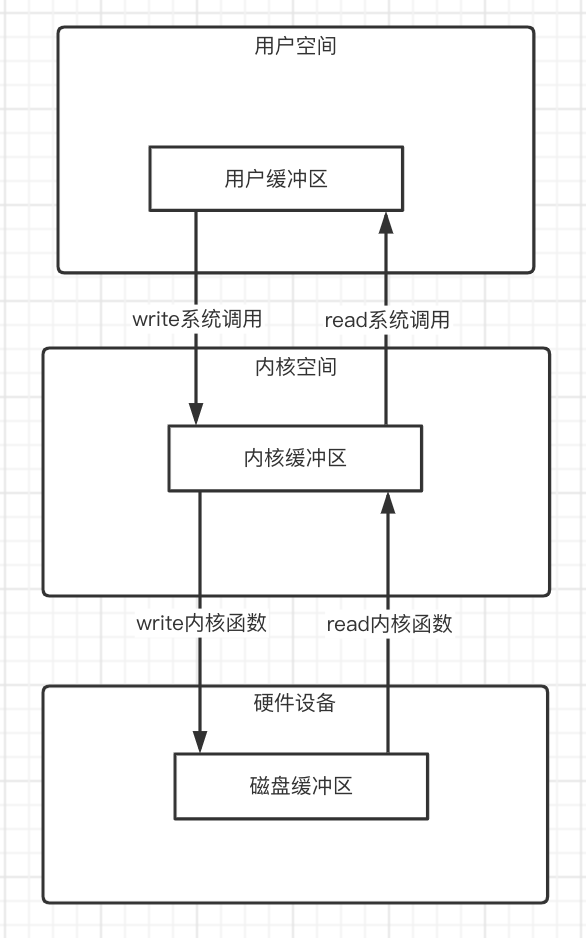
在进行系统调用的时候,比如read()系统调用,使用read()系统调用其实仅仅是把数据从内核缓存区拷贝到进程缓冲区,真正把数据从硬件设备读到操作系统的内核缓冲区中是通过操作系统的内核函数来完成的,至于什么时候会调用内核函数与硬件设备进行IO,就是操作系统的事了;而相对应的,write()系统调用时把进程缓冲区的数据拷贝到内核缓冲区。
DMA技术
在了解了基本的IO原理后,我们来看一下里面的详细过程。
比如,我们使用到了read()系统调用:
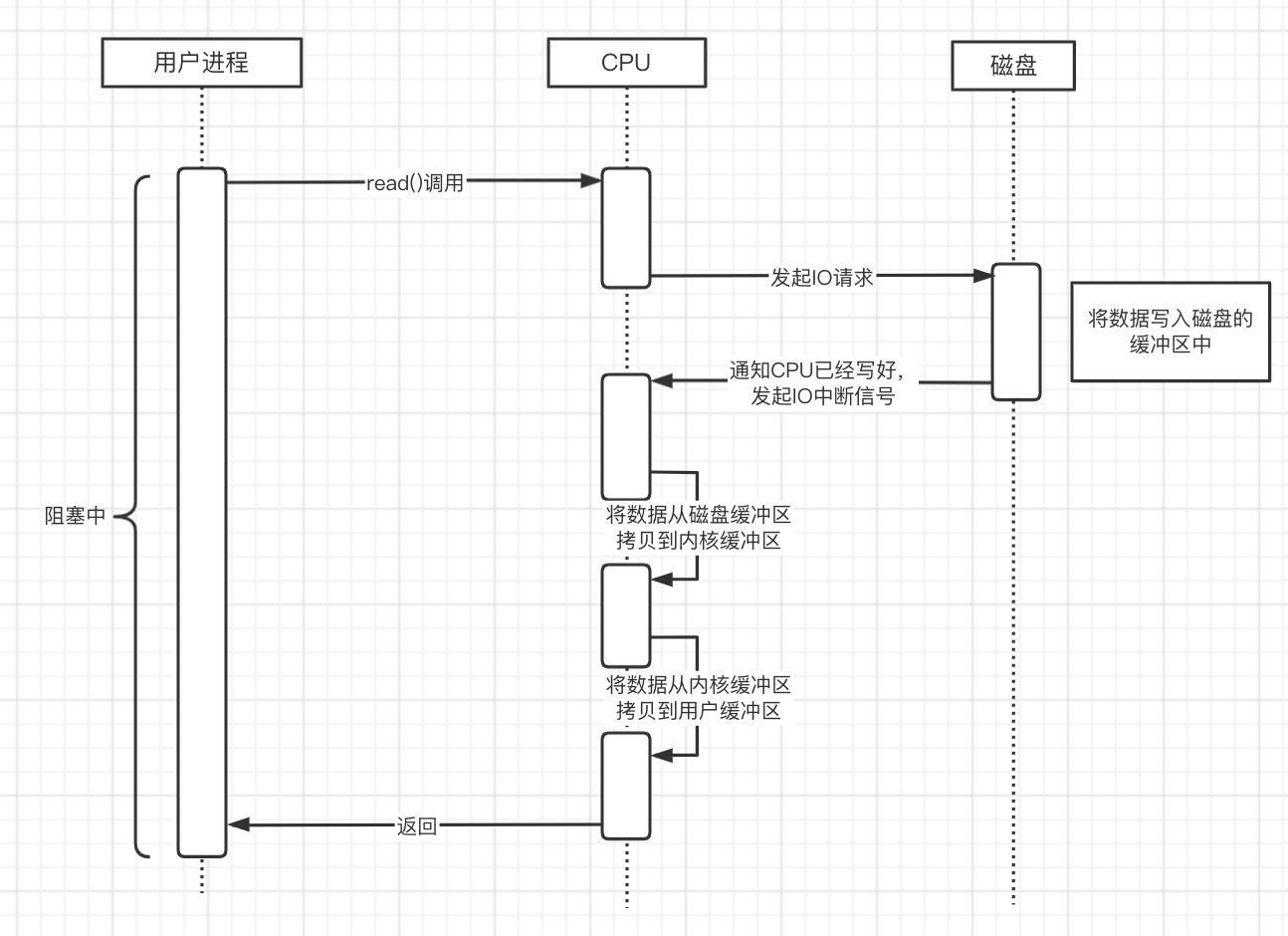
我们可以从图中看到,在用户进程发起read()调用的时候,CPU除了在向磁盘发起请求后,磁盘将数据写入到磁盘缓冲区时,CPU是空闲的外,之后都需要CPU的参与,在这个期间无法运行别的任务。
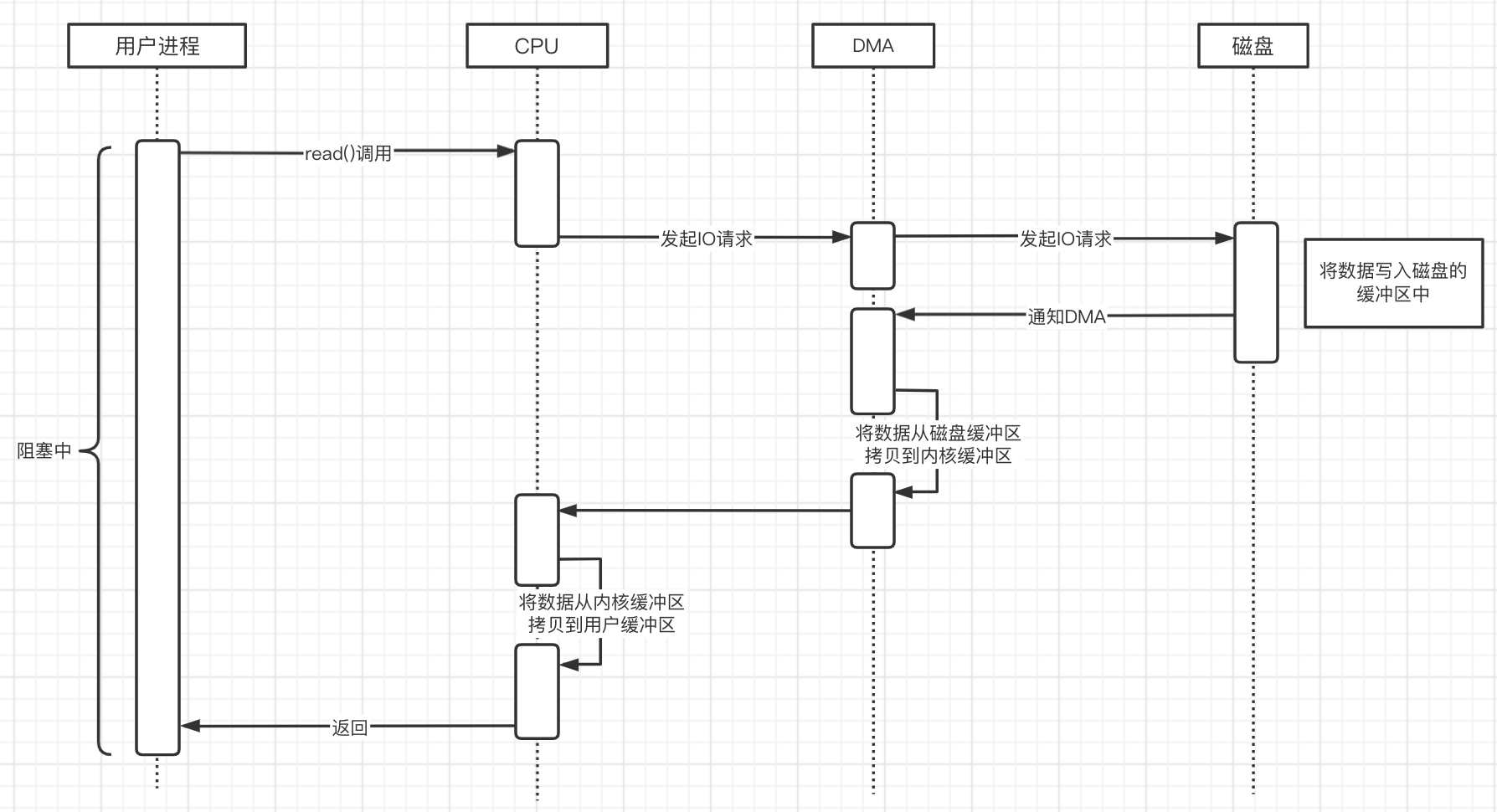
为了解决这个问题,前辈们发明了DMA技术(Direct Memory Access直接内存访问)。这下就把CPU解放了,这种脏活,累活就通过使用DMA控制器去专门处理IO设备与内存之间的数据传输,DMA把数据传输到内存中后,再通知CPU去处理。
零拷贝
read+write
我们以一个文件传输过程为例:
首先我们需要从磁盘中去读取文件,然后再把文件发出去。
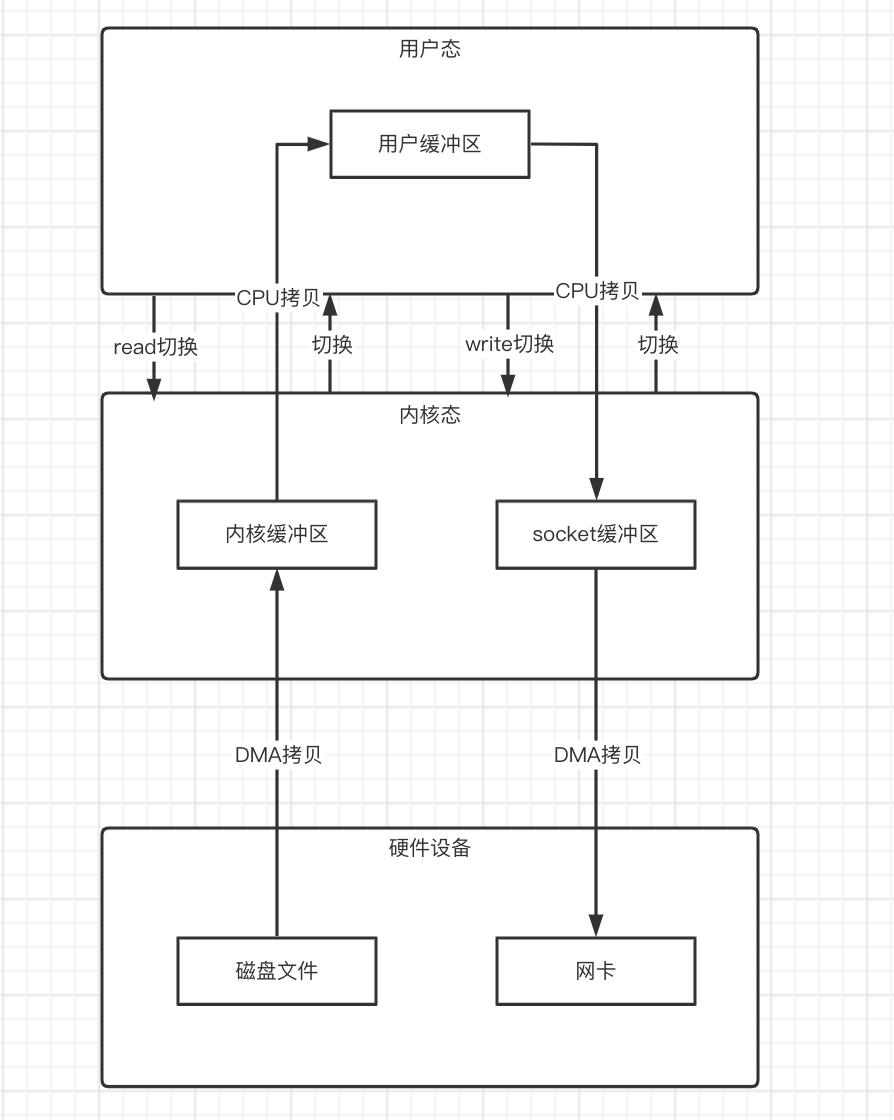
过程:
- 发起read()系统调用
- 从用户态切换到内核态,然后通过DMA拷贝,将磁盘的数据拷贝到内核缓冲区中
- 然后再通过CPU拷贝,将内核缓冲区的数据拷贝到用户缓冲区中
- 拷贝结束后,从内核态切回用户态
- 再发起write() 系统调用
- 从用户态切换到内核态,然后通过CPU拷贝,把用户缓冲区的数据拷贝到socket缓冲区中
- 然后再通过DMA拷贝,将socket缓冲区的数据拷贝到网卡中,发送出去
- 然后切换回用户态
在这个过程中,总共发生了4次上下文切换和4次数据拷贝,虽然可能对于高性能的CPU来说,这些时间并不算太长,但是如果并发度上来,时间的积累就会导致性能大大下降。
而比较容易想到的,提升性能的方法就是:
- 减少上下文切换次数
- 减少数据拷贝的次数
那如何去优化呢?
从上文中我们可以知道,四次上下文的切换是由于两次的系统调用产生的,所以我们可以考虑如何才能减少系统调用?
而在数据拷贝过程中,硬件我们没办法处理,但是在之后的过程,从内核缓冲区到用户缓冲区,再到socket缓冲区,这个过程中,用户缓冲区做了一次中间转存,却导致多花费了两次的数据拷贝,而且都是在内核态中,那是不是可以考虑直接把内核缓存区的数据拷贝到socket缓冲区呢?这样的话就减少了一次数据拷贝。
mmap+write
mmap()系统调用可以把内存缓冲区的数据,映射到用户空间中,这样就无需再把内存缓冲区的数据拷贝到用户缓冲区中了,从而减少了一次的数据拷贝过程,然后再调用write()系统调用函数,把内存缓冲区的数据,直接拷贝到socket缓冲区中。
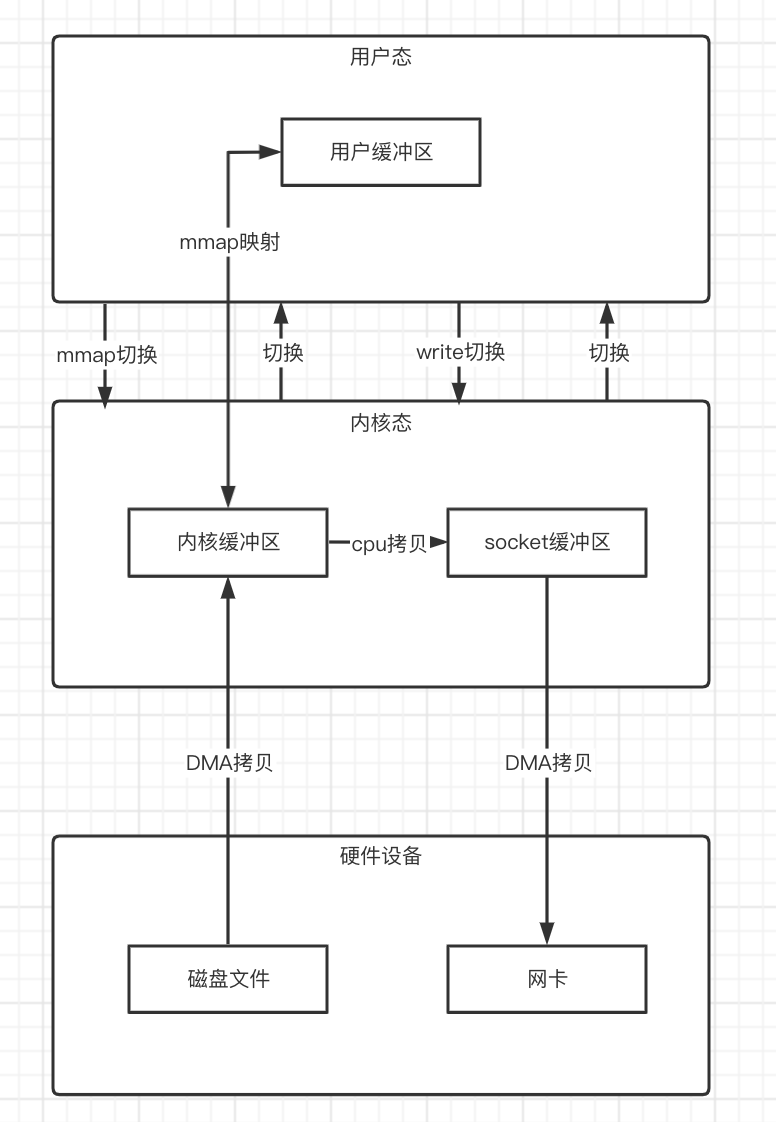
在上述过程中,总共发生了三次的数据拷贝,相比传统的数据拷贝减少了一次;但是在上下文切换方面,由于我们还是进行了两次的系统调用,所以依然还是发生了四次。
sendfile()
在Linux2.1中,专门提供了一个用于文件传输的函数:sendfile()。
函数定义:
#include<sys/sendfile.h>
ssize_t senfile(int out_fd,int in_fd,off_t* offset,size_t count);
参数含义:
- in_fd参数是待读出内容的文件描述符
- out_fd参数是待写入内容的文件描述符
- offset参数指定从读入文件流的哪个位置开始读,如果为空,则使用读入文件流默认的起始位置
- count参数指定文件描述符in_fd和out_fd之间传输的字节数。
sendfile()函数可以直接将内核缓冲区的数据拷贝到socket缓冲区中,而无需再使用write()系统调用了。
在Java中,fileChannel.transferTo()函数底层就是调用的sendfile()函数。
所以,整个过程就变成了:
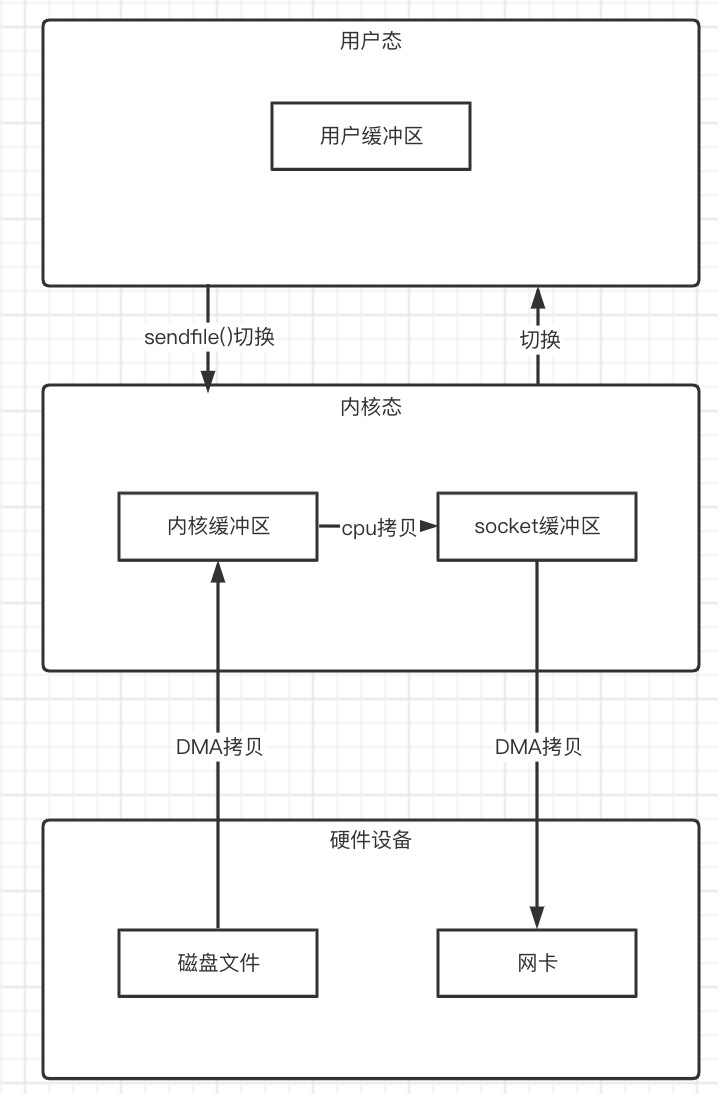
现在整个过程就是:两次的上下文切换和三次数据拷贝。
但是,这还不是最终的零拷贝过程。
sendfile()+SG-DMA
linux 2.4版本之后,对sendfile()做了优化升级,引入SG-DMA技术。
如果网卡支持SG-DMA(Scatter-gather DMA)的话,可以直接把内核缓冲区的数据拷贝到网卡中,这样就又减少了一次数据拷贝。
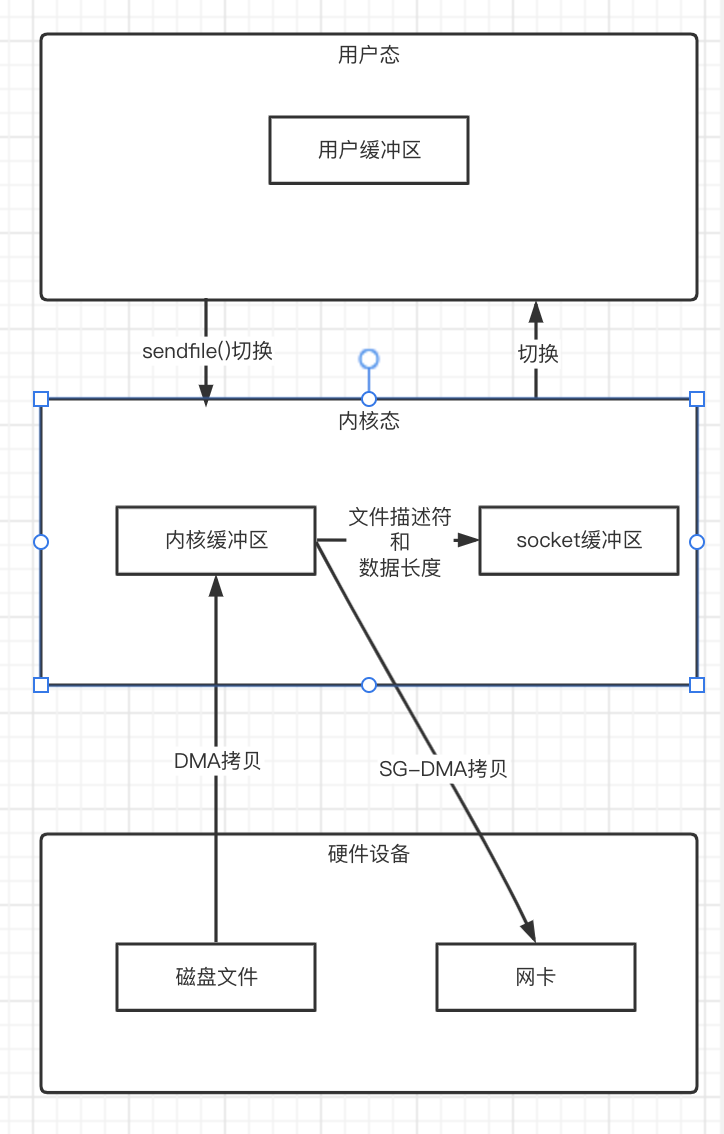
这次整个过程就只需要两次的上下文切换和两次的数据拷贝。
总结
想要理解零拷贝,首先要对IO过程有个理解,为什么有系统调用,为什么有缓冲区,什么是DMA;再从整个较为详细的IO过程出发,前辈们如何做的优化,理解起来就比较容易了。
零拷贝,听起来好像没有经过数据拷贝,但其实只是从刚开始的四次上下文切换和四次数据拷贝,减少到现在的两次上下文切换和两次数据拷贝,并不是真的一次数据拷贝都没有,从而大大提高了系统IO的性能。