说明:本系列文章若无特别说明,则在技术上将 Continual Learning(连续学习)等同于 Incremental Learning(增量学习)、Lifelong Learning(终身学习),关于 Continual Learning、Incremental Learning 和 Lifelong Learning 更细节的区别参见 VALSE Seminar【20211215 - 深度连续学习】
本文内容:
- 连续学习常用的评估数据集:Permuted MNIST,Split MNIST;
- 两个变种 MNIST 数据集在三种连续学习场景下(Task-IL,Domain-IL,Class-IL)的使用
MNIST
Link: https://paperswithcode.com/dataset/mnist
MNIST 手写字符数据集,不用过多介绍了。

Permuted MNIST
Permuted MNIST 数据集是 Goodfellow 等人在 2013 年的论文 An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks 首次提出的,并广泛用于 Domain-IL 的性能评估。

图片来源:Three scenarios for continual learning
作者认为,许多自然界的任务具有潜在的高度相关性,但在输入表现上有着不同的格式。比如:学习意大利语和西班牙语,这两个任务虽然在输入数据上完全不同,但作为自然语言系统,两者结构和潜在模式是一致的。这种连续学习模式属于 Domain-IL 范畴,即学习目标保持不变,但输入数据/分布在发生改变。
为了验证 Domain-IL 模型表现,作者对 MNIST 数据集进行了 Input reformatting 用来构造连续 task。首先,原始 MNIST 数据集作为 task 1,用 D 1 D_{1} D1 表示;之后的每个 task 都基于 MNIST 数据集进行重构,作为 task t,表示为 D t ( t > 1 ) D_t \ (t > 1) Dt (t>1)。具体重构方法是:对于每个 task t (t > 1),都对 MNIST 中所有图像以相同的方式进行像素重排(randomly permuted)。这样一来,每个 task 都具有和其他 task 完全不同的 input domain(每种 permutation 就是一个 input domain),但学习目标都是对数字 0~9 进行识别。在每个 task 上进行训练之后,模型都要在当前 task D t D_t Dt 以及之前学习过的所有 task { D 1 , . . . D t − 1 } \{D_1,...D_{t-1}\} { D1,...Dt−1} 上验证性能。
在论文 An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks 中对 Permuted MNIST 的解释:
To test this kind of learning problem, we designed a simple pair of tasks, where the tasks are the same, but with different ways of formatting the input. Specifically, we used MNIST classification, but with a different permutation of the pixels for the old task and the new task.
在论文 Measuring Catastrophic Forgetting in Neural Networks 中提供了对 Permuted MNIST 具体操作的解释:
Data Permutation Experiment - The elements of every feature vector are randomly permuted, with the permutation held constant within a session, but varying across sessions. The model is evaluated on its ability to recall data learned in prior study sessions. Each session contains the same number of examples.
通过以上对 Permuted MNIST 的解释,可以看出 Domain-IL 应该是最常见也最适合使用 Permuted MNIST 的场景。但在 Three scenarios for continual learning 中作者认为,Permuted MNIST 也可以使用在 Task-IL 和 Class-IL 场景中(参考论文 Table 3.)。对任意一个样本 x x x:
- Task-IL:给出 x x x 所在的 task-ID(permutation),预测样本 x x x 是数字几(0~9)
- Domain-IL:模型不知道 x x x 所在的 task-ID,预测样本 x x x 是数字几(0~9)
- Class-IL:模型不知道 x x x 所在的 task-ID,预测样本 x x x 是数字几(0~9)以及来自哪一个 permutation(task-ID)
为什么连续学习使用 Permuted MNIST 来验证模型性能?
使用 permuted MNIST 来验证连续学习模型(通常是 Domain-IL),都使用 MLP 而非 CNN。因为 MLP 不像 CNN 那样捕捉像素之间的空间关系,因此对 MLP 来说,是否 permute 图像中的像素对任务难度没有影响,每次都重新 permute 像素却可以生成新的任务。因此使用 permuted MNIST 的理由为:能够保持 output label 相同,同时能将 input data 的 distribution 打乱,生成完全不同的 n 个任务。
但在论文 Towards Robust Evaluations of Continual Learning 的 5.1 节,作者认为 Permuted MNIST 并非验证连续学习模型性能的最佳选择。理由如下:
1)permute 操作仅符合连续学习的字面定义(每个任务都不同),但并不符合现实场景中的数据
2)图像经过 permute 之后已经不再具备可识别性,即使是人也看不出图像中的目标是什么,这是不合理的
上面给出的理由还是从 CNN 角度来看的,但如果是 MLP 网络,实际上影响不大。
在这个问题里,也有相关讨论 Why is Permuted MNIST good for evaluating continual learning models?
Split MNIST
Split MNIST 数据集是 Zenke 等人在 2017 年的论文 Continual Learning Through Synaptic Intelligence 首次提出的。
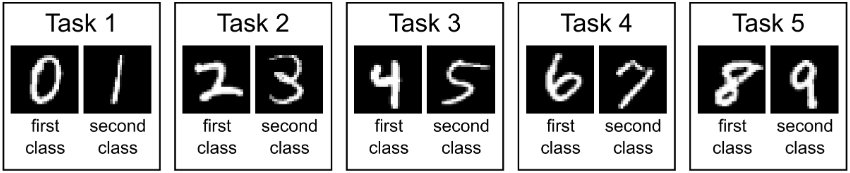
图片来源:Three scenarios for continual learning
为了验证连续学习模型表现,作者将 MNIST 数据集分为 5 部分,组成 5 个 task。第一个 task 为识别 ( 0 , 1 ) (0,1) (0,1),第二个 task 为识别 ( 2 , 3 ) (2,3) (2,3) 以此类推。可以看出,Split MNIST 比较适合 Task-IL 和 Class-IL 场景,而 Three scenarios for continual learning 作者认为 Split MNIST 与 Permuted MNIST 一样,同样能够应用于三种连续学习场景。对任意一个样本 x x x:
- Task-IL:给出 x x x 所在的 task-ID,预测样本 x x x 是数字几。若给出 ID=1,则可以预测 0/1,若给出 ID=2,则可以预测 2/3,以此类推。在 Task-IL 场景下,模型通常是 multi-head 的,也就是每个 task 都有一个单独的 output head,因此也叫 multi-headed split MNIST
- Domain-IL:模型不知道 x x x 所在的 task-ID,只能预测样本 x x x 属于第一类([0, 2, 4, 6, 8])还是第二类([1, 3, 5, 7, 9])
- Class-IL:模型不知道 x x x 所在的 task-ID,需要预测样本 x x x 是数字几(0~9),也就是不仅需要推断样本 x x x 来自哪一个 task,还要在该 task 中做出正确预测。在 Class-IL 场景下,模型通常是 single-head 的,预测难度更大
在论文 Re-evaluating Continual Learning Scenarios: A Categorization and Case for Strong Baselines 有专门解释 Split MNIST 在三种连续学习场景下的区别:
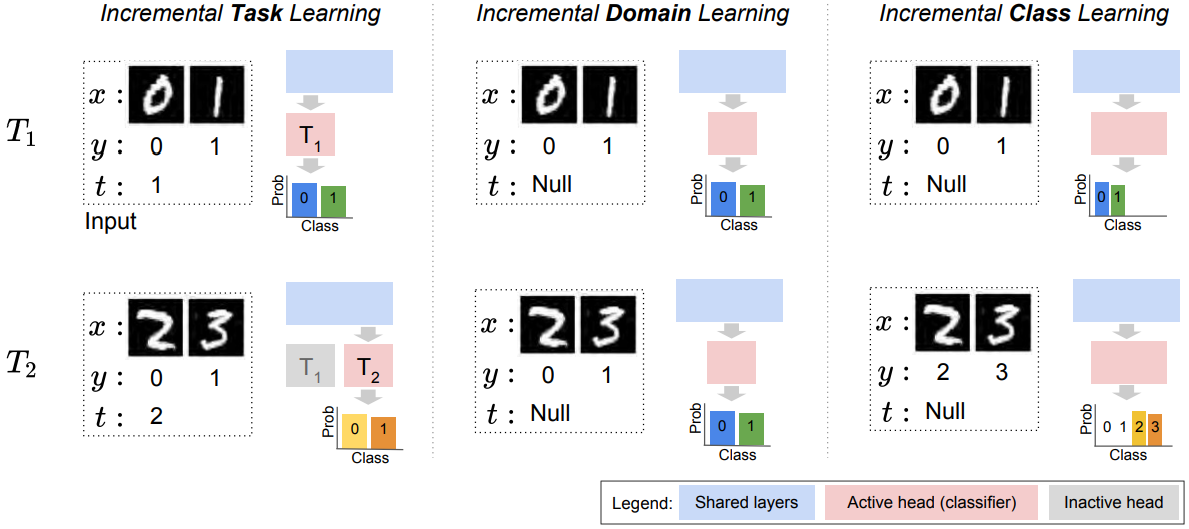
其中 x x x、 y y y、 t t t 分别表示输入数据、对应标签、task-ID。
Sequential MNIST
Sequential MNIST 出现的比较少,通常是指在序列任务中,模型不是一次性看到或生成 MNIST 的数据的,而是按顺序地一次只看一个像素。Sequential MNIST 通常用在 generative context 下。
论文 Professor Forcing: A New Algorithm for Training Recurrent Networks 4.3 节中有对 Sequential MNIST 的描述。
We evaluated Professor Forcing on the task of sequentially generating the pixels in MNIST digits.
Sequential MNIST 之后用到了再继续更新。