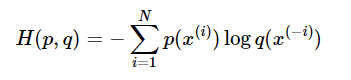专栏目录:pytorch(图像分割UNet)快速入门与实战——零、前言
pytorch快速入门与实战——一、知识准备(要素简介)
pytorch快速入门与实战——二、深度学习经典网络发展
pytorch快速入门与实战——三、Unet实现
pytorch快速入门与实战——四、网络训练与测试
深度学习一些概念
交叉熵,正则化,恒等映射与退化。我也迷,你别怕,反正能用就行啦。
什么梯度下降,什么BP算法,计算图什么,全连续网络、卷积网络……emmm好的,卷积网络我还是懂的,所以我冲深度学习。
卷积不懂的去看这个:机器学习之路三:卷积神经网络
争取最快的速度上手操刀动代码,所以,以下一些我了解之后会很舒服的概念,一个大概五分钟左右,了解一下:
参考某站@莫烦python和某乎@晓强DL以及本站等大佬
喜欢更细致的也可以某站找@刘二大人
0 机器学习与深度学习
机器学习发展:线性分类->感知机->梯度下降->神经网络->BP算法->三层全连接网络->CNN
像SVM支持向量感知机,决策树,EM算法,概率图,朴素贝叶斯等这些都特属于机器学习。
当然深度学习也属于机器学习。那区别在哪呢?
卷积神经网络!
2012年AlexNet将特征工程与分类集成为一体,利用卷积神经网络在CV领域碾压传统机器学习方法,作为里程碑,拉开卷积神经网络统治计算机视觉的序幕,也加速计算机视觉应用落地。
1 数据预处理中的概念
1.1 数据的特征
经典例子西瓜书,西瓜有各种特征可以输入进网络(或者人脑)进行判断。
西瓜我不太了解,所以换一个。
一群狗和一群猫,如果恰巧都是黄狗和白猫,那选取颜色特征,对于这个分类任务就可以很好的解决,但如果选择眼睛的数量和尾巴的数量就很难解决这个问题。
所以,好的特征能够很好的说明问题。
我们要选择好的特征,筛选不好的特征。
具体示例中要复杂的多。
参考:怎样区分好用的特征
1.2 特征标准化
具体实例中有很多特征是不标准的:
房价根据众多参数( 到市中心的举例,楼层,面积,所在城市等 )而变化。
抽两个参数举例, 以km为单位的距离,以单位m2的面积
距离都是10km左右,而面积0~200,跨度不同,影响力不同,也就是权重不同(却不体现重要程度),但是标准化之后就可以让权重更好的体现重要程度。
两种方法:

而且!有些特征是量化的,比如距离和面积。
但是还有些特征比如“所在城市”却不是量化的,就可以想办法对特征量化来解决问题:比如对城市进行分级。
参考:为什么要特征标准化
1.3 不均衡数据的处理
典例:99个猫的"图片” “例子”(“图片”可能导向识别问题,这里换成“例子”),1只狗的图片例子作为训练集。(这些例子都是特征描述,可以是颜色高度重量,也可以是图片中像素值分布关系)
只要机器全部猜测猫,准确率就可以达到99%
但是对于猫狗分类问题来说,这个机器的分类方法对猫的分类准确率是100%,对狗的分类准确率却是0%
所以其实这个机器并不能解决猫狗分类问题
【单纯说分类,不说识别】
• 也就是说这个数据集不能解决这个问题,那么就要对数据集进行处理。
1.寻找更好的数据集
2.复制狗的例子,使其均衡
3.减少猫的例子,使其均衡
其他方法参考下面文章:处理不均衡数据
2 网络设计中的概念
2.1 激励函数
我也不是很懂,简略说下我的看法:
首先并不是每次捏的特征都能一直作用下去,在神经网络工作的过程中,有很多特征组合是要被淘汰的,淘汰机制就是激活函数。所以激活函数对结果的一次再变换,判断其是否符合激活标准。
通俗地说,这条路能不能走,是0就不能走(杀死神经元),不是0就可以走(激活神经元)。
先前的笔记:
将线性函数变成非线性来解决非线性问题。也就是对y再进行一次变换。
但这些激励函数必须可微分。因为多层网络的梯度传导中,需要对微分计算梯度下降方向。
对于浅层网络,激励函数选择没有那么大要求。
但是当网络层数比较深的时候,激励函数选择不甚会导致梯度消失以及梯度下降问题。
也和梯度传导过程中的微分有关。
浅层的CNN可以用relu,浅层循环网络可以用relu或者tanh
emmm我的感觉而已,具体参考:
为什么需要激励函数
常用激励函数
2.2 优化器optimizer 加速神经网络训练 (如SGD)
参考:优化器加速神经网络训练
2.3 BN层
本节简单介绍,后续在GoogleNet-V2中详细介绍
批量归一化(BN:Batch Normalization:解决在训练过程中,中间层数据分布发生改变的问题,以防止梯度消失或爆炸、加快训练速度)
以tanh激活函数为例,只有训练数据在中间部分的时候才是相对更有效的数据,当其分布在两边的时候在训练过程中的影响就会比较。。。“固定”(随着变化并不怎么变化)
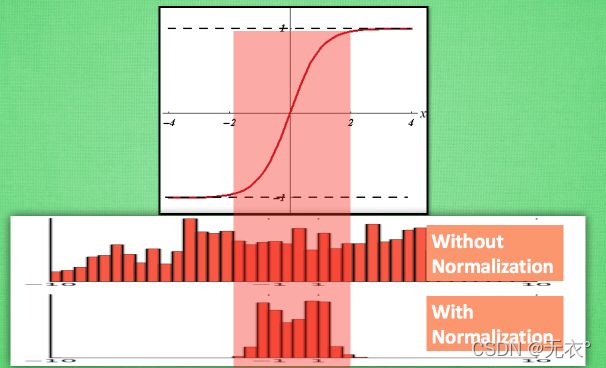
所以我们可以在不影响数据整体分布的情况下,对其进行迁移,也就是标准化,将数据在相对保留分布的情况下,变换到一个好的区间,从而更好的“影响”训练。
2.4 经典网络发展与选择
由于如果给网络内分模块的话,四级结构太过于庞大,而且本身篇幅太长,不便编写与阅读。这里我医学图像处理直接选择Unet网络开冲。
单开一篇文章介绍:pytorch快速入门与实战——二、深度学习经典网络发展
3. Loss函数中的概念
别陷入太深,随便看看就行,不看也行。现阶段简单了解就好了,反正就是算误差的。
常见损失函数
3.1 L1 L2正则化
3.2 均方误差(Mean Squared Error)
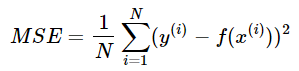
3.3 交叉熵代价函数(Cross Entry)