归约求和算法(三)
前两个里面 kernel 函数在使用线程时很浪费,每个块中有一半线程根本没执行。而且在每个块归约后是通过串行求和的,本节使用一种循环调用kernel的方法对块内归约的结果进行求和,直接从kernel输出最终结果。而且每个线程都执行运算,能处理的元素数是原来算法的两倍。
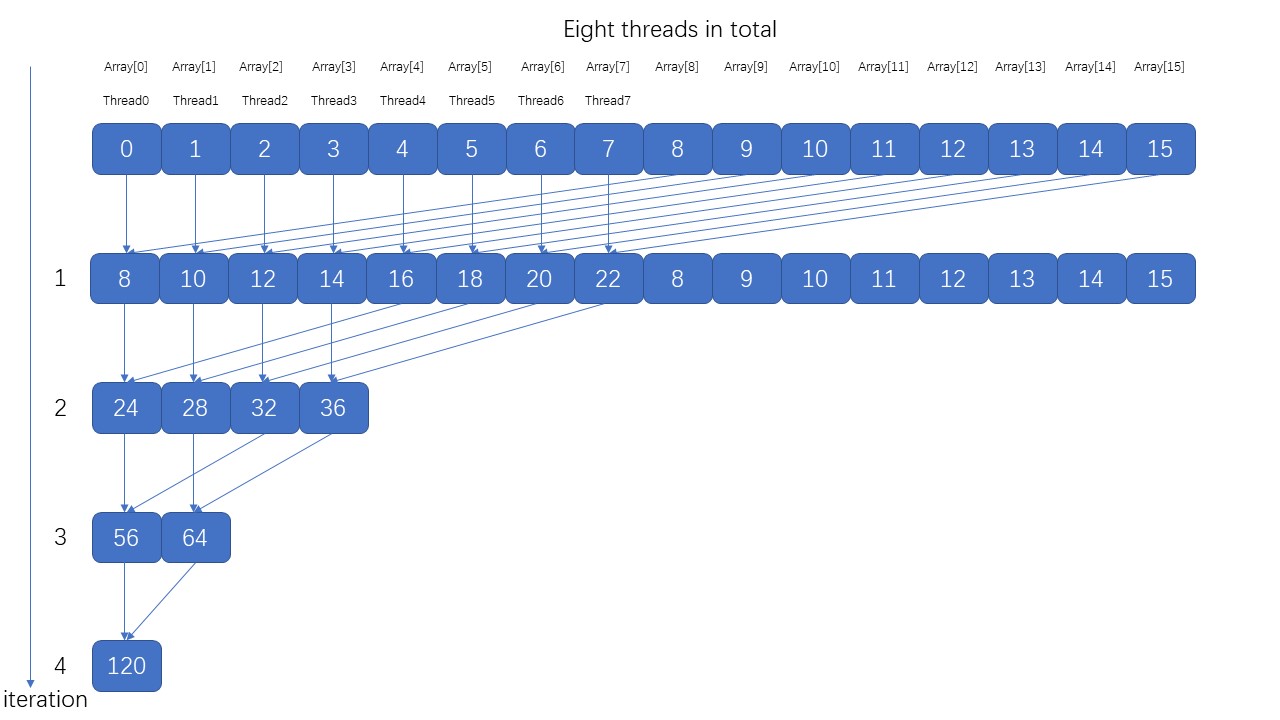
原理如下图:
代码如下:
#include<cuda.h>
#include<stdlib.h>
#include<stdio.h>
#define THREAD_LENGTH 1024
//the same as before
__global__ void reduction_sum(double *X, size_t input_size){
__shared__ double partialSum[2 * THREAD_LENGTH];
int i = 2 * blockIdx.x * blockDim.x + threadIdx.x;
if(i < input_size) partialSum[threadIdx.x] = X[i];
else partialSum[threadIdx.x] = 0.0;
if(i + blockDim.x < input_size) partialSum[threadIdx.x + blockDim.x] = X[i + blockDim.x];
else partialSum[threadIdx.x + blockDim.x] = 0.0;
__syncthreads();
//without console stream
unsigned int t = threadIdx.x;
for(int stride = blockDim.x; stride >= 1; stride /= 2){
if(t < stride)
partialSum[t] += partialSum[t + stride];
__syncthreads();
}
//with console stream
// unsigned int t = threadIdx.x * 2;
// for(int stride = 1;stride <= blockDim.x;stride <<= 1){
// if(t % (2*stride) == 0){
// partialSum[t] +=partialSum[t + stride];
// }
// __syncthreads();
// }
if(t == 0){
X[blockIdx.x] = partialSum[t];
}
}
//host code
double reduceArray(double* array, unsigned int length){
double *d_A;
int size = length*sizeof(double);
cudaMalloc(&d_A, size);
cudaMemcpy(d_A, array, size, cudaMemcpyHostToDevice);
int num_blocks = (length - 1)/THREAD_LENGTH/2 + 1;
while(num_blocks >= 1){
reduction_sum<<<num_blocks, THREAD_LENGTH>>>(d_A, length);
if(num_blocks == 1)
break;
length = num_blocks;
num_blocks = (num_blocks - 1)/THREAD_LENGTH/2 + 1;
}
double result(0);
cudaMemcpy(&result, d_A, sizeof(double), cudaMemcpyDeviceToHost);
cudaFree(d_A);
return result;
}
//test
int main(int argc, char **argv){
int n = atoi(argv[1]);
double *A = (double *)malloc(n * sizeof(double));
for(int i = 0; i < n;++i){
A[i] = 1.0;
}
double result = reduceArray(A, n);
printf("%lf\n", result);
free(A);
return 0;
}
- 代码首先把数组copy到GPU中;
- 用总数组元素个数除以线程数的二倍的结果作为启动线程的线程块数量;
- kernel首先把输入数组从全局存储器加载到共享存储器中,其中利用参数 blockIdx.x 让一个线程加载两个元素;
- 在块内进行归约求和;
- 将每个块内的结果利用变量blockIdx.x存入全局存储器数组的前方;
- 循环调用kernel,直到只剩一个线程块处理完求和。
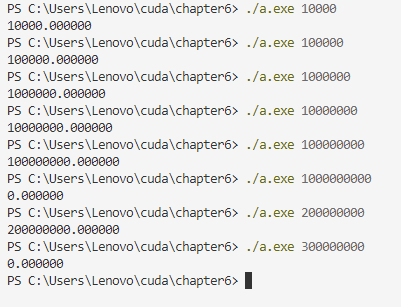
运行结果: